







文章目录
一、数据类型
R 语言中的最基本数据类型主要有三种:
- 数字
- 逻辑
- 文本
R(S)中没有标量,它通过使用各种类型的向量来存储数据。常用的数据类型(class)有:
| Type | Description | 示例 |
|---|---|---|
| 字符(charactor) | 它们常常被引号包围 | a='Hello' |
| 数字(numeric) | 实数向量 | x=c(1,2,3,4,5) |
| 整数(integer) | 整数向量 | a=1:5 |
| 逻辑(logical) | 逻辑向量(TRUR=T,FALSE=F) | a=c(T,F) |
| 复数(complex) | 复数 | a=1+1i |
| 列表(list) | S对象的向量 | list() |
| 因子(factor) | 常用于标记样本 |
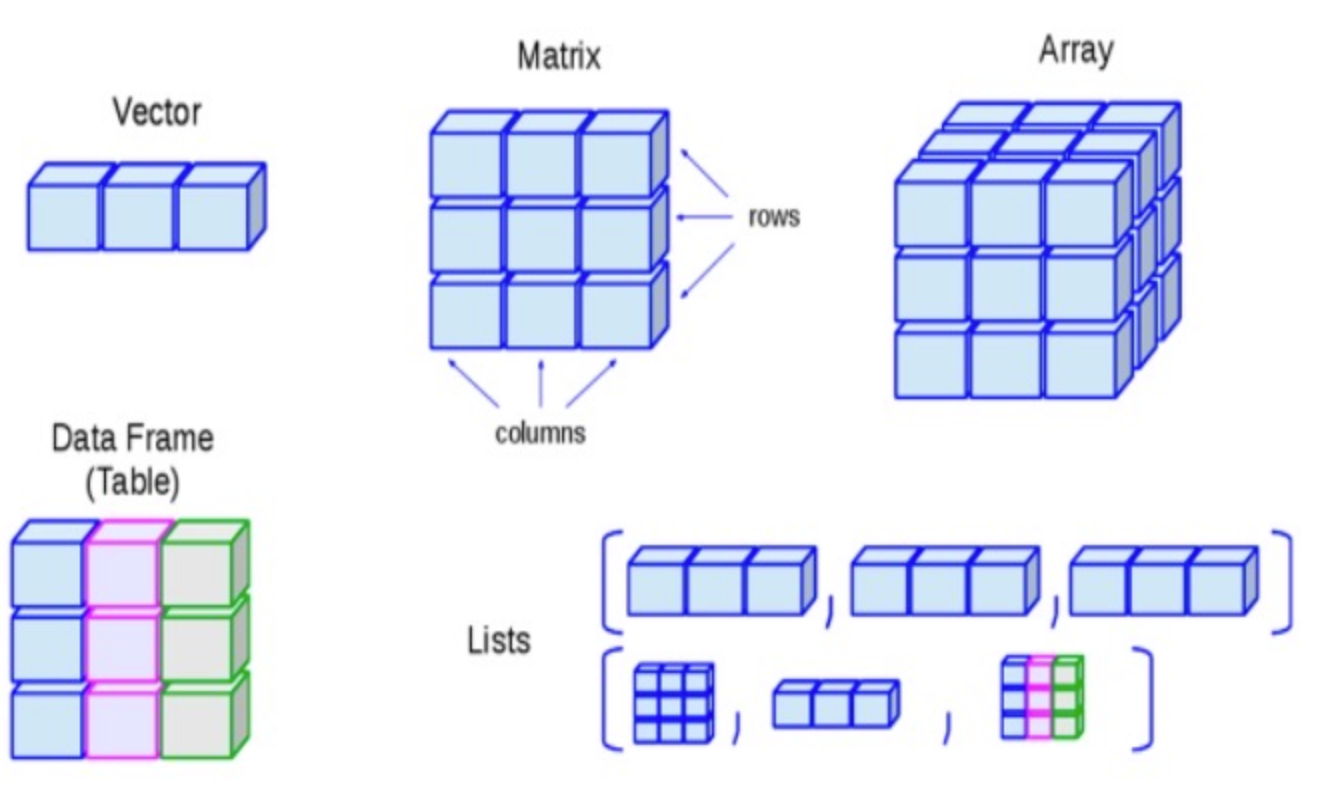
按对象类型来分是以下 6 种
- 向量(vector)
- 列表(list)
- 矩阵(matrix)
- 数组(array)
- 因子(factor)
- 数据框(data.frame)
它们的关系如下所示:
一些简单的数据类型就不做赘述,下面对几种比较复杂点的数据类型进行详细的介绍。
1、向量 vector
向量(Vector)在 Java、Rust、C# 这些专门编程的的语言的标准库里往往会提供,这是因为向量在数学运算中是不可或缺的工具。c() 在 R 中是一个创造向量的函数,通常有如下三种方法生成一个向量
c()构造任意的向量seq()构造等差序列的向量rep()构造重复序列的向量
生成向量的示例如下:
a=c(1,2,3,4,5)
seq生成等差序列的向量
seq(from = 1, to = 1, by = ((to - from)/(length.out - 1)),length.out = NULL, along.with = NULL, ...)
from是首项,默认为1 ;to是末项,默认为1;by是步长或者等差增量,可以为负数;length.out是向量的长度;along.with用于指明该向量与另外一个向量的长度相同,along.with后应为另一个向量的名字
s1<-seq(1,10,3)
# [1] 1 4 7 10
使用rep函数创建重复序列的向量
rep(x, times = 1, length.out = NA, each = 1)
x为要重复的序列对象;times为重复的次数,默认为1;length.out为产生的向量长度,默认为NA(不限制);each为每个元素重复的次数,默认为1,也可以给一个同序列对象相同长度的列表
r2<-rep(c(2,5),c(3,4))
# [1] 2 2 2 5 5 5 5
2、字符串 string
字符串本身并不复杂,下面介绍一些对字符串的操作函数:
| 名称 | 含义 | 示例 |
|---|---|---|
<- 或= | 赋值 | str<-"hello"(单引号双引号都可) |
toupper() | 小写转大写 | toupper("hello") |
tolower() | 大写转小写 | tolower("HELLO") |
nchar() | 统计字节长度 | nchar("中文", type="bytes")=4 |
nchar() | 统计字符数量 | nchar("中文", type="char")=2 |
substr() | 截取字符串 | substr("123456789", 2, 5)="2345" |
substring() | 截取字符串 | substring("1234567890", 5)="567890" |
as.numeric() | 字符串转数字 | as.numeric("12.1")=12.1 |
as.character() | 数字转字符串 | as.character(12.34)="12.34" |
strsplit() | 字符串分割 | strsplit("2019;10;1", ";") |
gsub() | 替换字符 | gsub("/", "-", "2019/10/1")="2019-10-1" |
paste() | 连接字符串 | paste(a,b,c, sep = "-")连接符是-,默认为空格 |
format() | 格式化字符串 | format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none")) |
注:R 支持 perl 语言格式的正则表达式
> gsub("[[:alpha:]]+", "$", "Two words")
[1] "$ $" # 就是将两个单词替换为 $
letters # R 中已有的字符向量,小写a-z
> paste(letters[1:6],1:6, sep = "", collapse = "=")
"a1=b2=c3=d4=e5=f6" # 先将两组字符串以""为分隔符进行连接,然后再用"="进行连接
format(x, digits, nsmall, scientific, width, justify = c("left", "right", "centre", "none"))
关于format函数的参数的释义如下:
- x : 输入对向量
- digits : 显示的位数
- nsmall : 小数点右边显示的最少位数
- scientific : 设置科学计数法
- width : 通过开头填充空白来显示最小的宽度
- justify:设置位置,显示可以是左边、右边、中间等。
示例可参看:https://www.runoob.com/r/r-string.html
3、矩阵 matrix
R 提供了语言级的矩阵运算支持,首先看看矩阵的生成
> vector=c(1, 2, 3, 4, 5, 6)
> matrix(vector, 2, 3) # 将向量改写为2行3列的矩阵,按列存储
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6
> matrix(vector, 2, 3, byrow=TRUE) # 如果想按行填充,需要指定 byrow 属性
# 下面是一个参数较全的矩阵构造示例
> rownames = c("row1", "row2", "row3", "row4")
> colnames = c("col1", "col2", "col3")
> P <- matrix(c(3:14), nrow = 4, byrow = TRUE, dimnames = list(rownames, colnames))
> print(P)
col1 col2 col3
row1 3 4 5
row2 6 7 8
row3 9 10 11
row4 12 13 14
下面是一些对矩阵的常用操作:
| 名称 | 含义 | 示例 |
|---|---|---|
[] | 取矩阵中元素的值 | m[1,1]=1 |
colnames() | 给矩阵的列命名 | colnames(m1) = c("x", "y", "z") |
rownames() | 给矩阵的行命名 | rownames(m1) = c("a", "b") |
["a",] | 给矩阵行列命名后可这样取元素 | m1["a",] |
* | 矩阵对应元素相乘 | matrix1*matrix2 |
%*% | 矩阵乘法 | m1 %*% m2 |
+ | 矩阵加法 | matrix1+matrix2 |
- | 矩阵减法 | matrix1-matrix2 |
/ | 矩阵对应元素相除 | matrix1 / matrix2 |
solve() | 矩阵求逆 | solve(A) |
t() | 矩阵转置 | t(A) |
4、列表 list
R 语言创建列表使用 list() 函数,示例如下:
> list_data <- list("google", c(11,22,33), 123, 51.23)
> print(list_data)
[[1]]
[1] "google"
[[2]]
[1] 11 22 33
[[3]]
[1] 123
[[4]]
[1] 51.23
下面是对list的一些常用操作
| 名称 | 含义 | 示例 |
|---|---|---|
names() | 给列表的元素命名 | names(list_data) <- c("Sites", "Numbers", "Lists") |
[] | 访问列表元素 | list_data[1] |
c() | 合并列表 | merged.list <- c(list1,list2) |
unlist() | 列表转向量 | v1 <- unlist(list1) |
5、数组 array
R 语言数组创建使用 array() 函数,该函数使用向量作为输入参数,可以使用 dim 设置数组维度。array() 函数语法格式如下:
array(data = NA, dim = length(data), dimnames = NULL)
- data 向量,数组元素。
- dim 数组的维度,默认是一维数组。
- dimnames 维度的名称,必须是个列表,默认情况下是不设置名称的。
下面是一个示例:
> vector1 <- c(5,9,3)
> vector2 <- c(10,11,12,13,14,15)
> column.names <- c("COL1","COL2","COL3")
> row.names <- c("ROW1","ROW2","ROW3")
> matrix.names <- c("Matrix1","Matrix2")
> result <- array(c(vector1,vector2),dim = c(3,3,2),dimnames = list(row.names,column.names,matrix.names))
> print(result)
, , Matrix1
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
, , Matrix2
COL1 COL2 COL3
ROW1 5 10 13
ROW2 9 11 14
ROW3 3 12 15
下面是一些对数组的常用的操作
result[,,2]:取array中的元素apply(x, margin, fun)对数组元素进行跨维度计算
- x 数组
- margin 数据名称
- fun 计算函数
# apply 示例,数据还是上面的 array
> apply(result, c(1), sum) # 计算数组中所有矩阵第一行的数字之和
ROW1 ROW2 ROW3
56 68 60
6、因子 factor
因子用于存储不同类别的数据类型,R 语言创建因子使用 factor() 函数,向量作为输入参数。factor() 函数语法格式:
factor(x = character(), levels, labels = levels,
exclude = NA, ordered = is.ordered(x), nmax = NA)
- x:向量。
- levels:指定各水平值, 不指定时由x的不同值来求得。
- labels:水平的标签, 不指定时用各水平值的对应字符串。
- exclude:排除的字符。
- ordered:逻辑值,用于指定水平是否有序。
- nmax:水平的上限数量。
下面是一个示例:
> sex=factor(c('f','m','f','f','m'),levels=c('f','m'),labels=c('female','male'),ordered=TRUE)
> print(sex)
[1] female male female female male
Levels: female < male
我们可以使用 gl() 函数来生成因子水平,语法格式如下:
gl(n, k, length = n*k, labels = seq_len(n), ordered = FALSE)
- n: 设置 level 的个数
- k: 设置每个 level 重复的次数
- length: 设置长度
- labels: 设置 level 的值
- ordered: 设置是否 level 是排列好顺序的,布尔值。
> v <- gl(3, 4, labels = c("1", "2","3"))
> print(v)
[1] 1 1 1 1 2 2 2 2 3 3 3 3
Levels: 1 2 3
7、数据框 data.frame
数据框(Data frame)可以理解成我们常说的"表格"。数据框是 R 语言的数据结构,是特殊的二维列表。数据框每一列都有一个唯一的列名,长度都是相等的,同一列的数据类型需要一致,不同列的数据类型可以不一样。R 语言数据框使用 data.frame() 函数来创建,语法格式如下:
data.frame(…, row.names = NULL, check.rows = FALSE,
check.names = TRUE, fix.empty.names = TRUE,
stringsAsFactors = default.stringsAsFactors())
…: 列向量,可以是任何类型(字符型、数值型、逻辑型),一般以 tag = value 的形式表示,也可以是 value。row.names: 行名,默认为 NULL,可以设置为单个数字、字符串或字符串和数字的向量。check.rows: 检测行的名称和长度是否一致。check.names: 检测数据框的变量名是否合法。fix.empty.names: 设置未命名的参数是否自动设置名字。stringsAsFactors: 布尔值,字符是否转换为因子,factory-fresh 的默认值是 TRUE,可以通过设置选项(stringsAsFactors=FALSE)来修改。
下面是一个简单的例子
> table = data.frame(
+ 姓名 = c("张三", "李四"),
+ 工号 = c("001","002"),
+ 月薪 = c(1000, 2000)
+
+ )
> print(table) # 查看 table 数据
姓名 工号 月薪
1 张三 001 1000
2 李四 002 2000
> str(table) # 获取数据结构
'data.frame': 2 obs. of 3 variables:
$ : chr "张三" "李四"
$ : chr "001" "002"
$ : num 1000 2000
> print(summary(table)) # 显示概要
姓名 工号 月薪
Length:2 Length:2 Min. :1000
Class :character Class :character 1st Qu.:1250
Mode :character Mode :character Median :1500
Mean :1500
3rd Qu.:1750
Max. :2000
> result <- data.frame(table$姓名,table$月薪) # 提取指定的列
> print(result)
table.姓名 table.月薪
1 张三 1000
2 李四 2000
> result <- table[1:2,] # 提取指定的行
> print(result)
姓名 工号 月薪
1 张三 001 1000
2 李四 002 2000
下面是对data.frame的一些常用操作:
| 名称 | 含义 | 示例 |
|---|---|---|
str() | 获取数据框的数据结构 | str(table) |
summary() | 显示数据框的概要信息 | summary(table) |
table$clo_name | 提取指定列 | result <- data.frame(table$姓名,table$月薪) |
[:,] | 提取指定行 | result <- table[1:2,] |
table$clo_name | 添加列 | table$部门 <- c("运营","技术") |
cbind() | 将多个向量合成一个数据框 | addresses <- cbind(sites,likes,url) |
rbind() | 对两个数据框进行合并 | result <- rbind(table,newtable) |
二、常用数据操作
is.na(x) #判断x是否是NA
m=x[!is.na(x)] #删除x中的NA值,把结果返回给m
eval(parse(text = a)) #将字符串变成命令执行,parse()将字符串转换为表达式(expression)而后使用eval()对其进行求解
class(x) #输出x的类型
n=append(m,0,after=0) #在m的索引为1处插入元素0,并将结果赋给n
y<-data.frame(matrix(1:30,nrow=5,byrow=T)) #byrow=T, 指按行存储数据,默认是按列存储数据
new.x1<-x[-c(1,4),] #去掉x中的第一、四行,其余元素赋给new.x1
new.x2<-x[,-c(2,3)] #去掉x中的第二、三列,其余元素赋给new.x2



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











