







AudioSet 是谷歌于 2017 年发布的一个大规模的标注音频事件数据集,具有以下特点和信息:
数据构成
- 音频片段数量:包含 2,084,320 个人工标注的 10 秒声音片段,这些片段均来源于 YouTube 视频13.
- 音频事件类别:拥有 632 个音频事件类的扩展本体,其事件类别以层次结构组织,最大深度为 6 级,涵盖了人类和动物的各种声音、乐器和流派以及常见的日常环境声音等,例如鸟叫、汽车行驶声、乐器演奏声等3.
标注信息
- 每个音频片段都附带了清晰准确的标签,标注信息以 JSON 格式发布,其中包括音频的 ID、显示名称、描述、示例音频的 URL、子类别以及限制条件等详细内容,方便研究人员进行分类和分类算法的训练2.
数据收集与整理
- 谷歌通过人工标注员来验证 YouTube 视频片段中声音的存在性,从而收集数据。在提名标注片段时,依靠 YouTube 的元数据和基于内容的搜索来筛选合适的视频片段.
下载数据集索引
进入AudioSet
可以看见有三种数据集:

label 的索引
进入这里
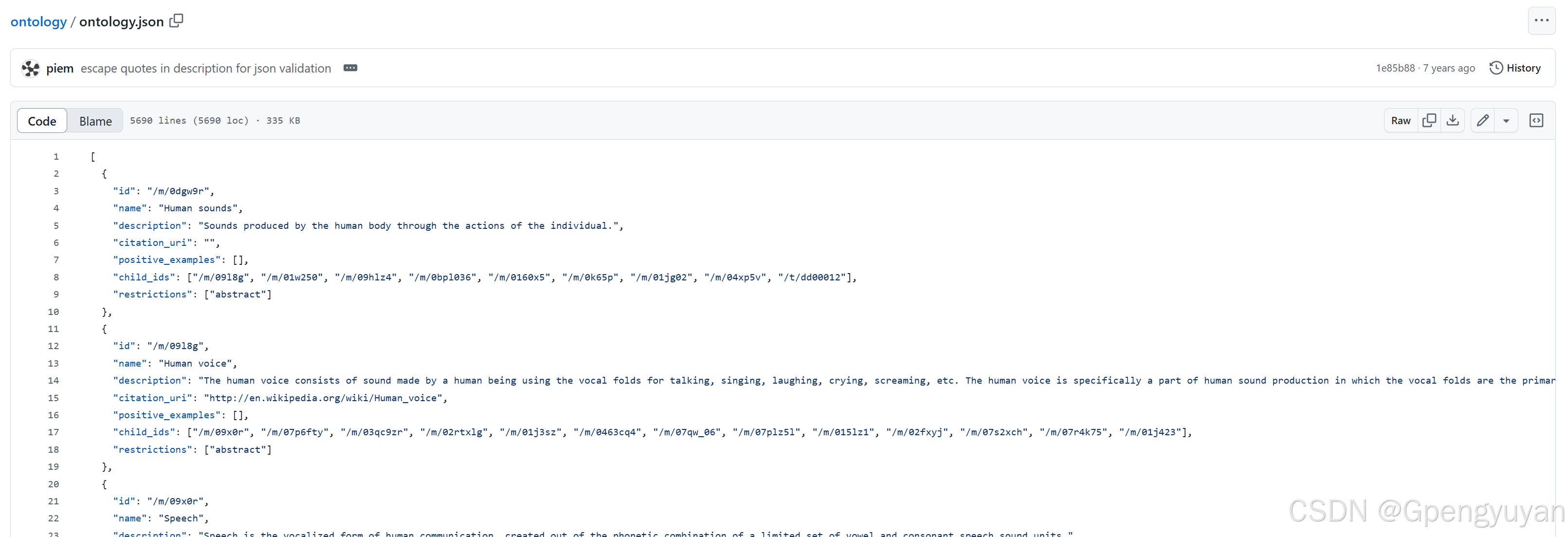
https://github.com/audioset/ontology
打开ontology.json文件,这里有label的编码和对应的实际意义。
AudioSet音频数据的下载:
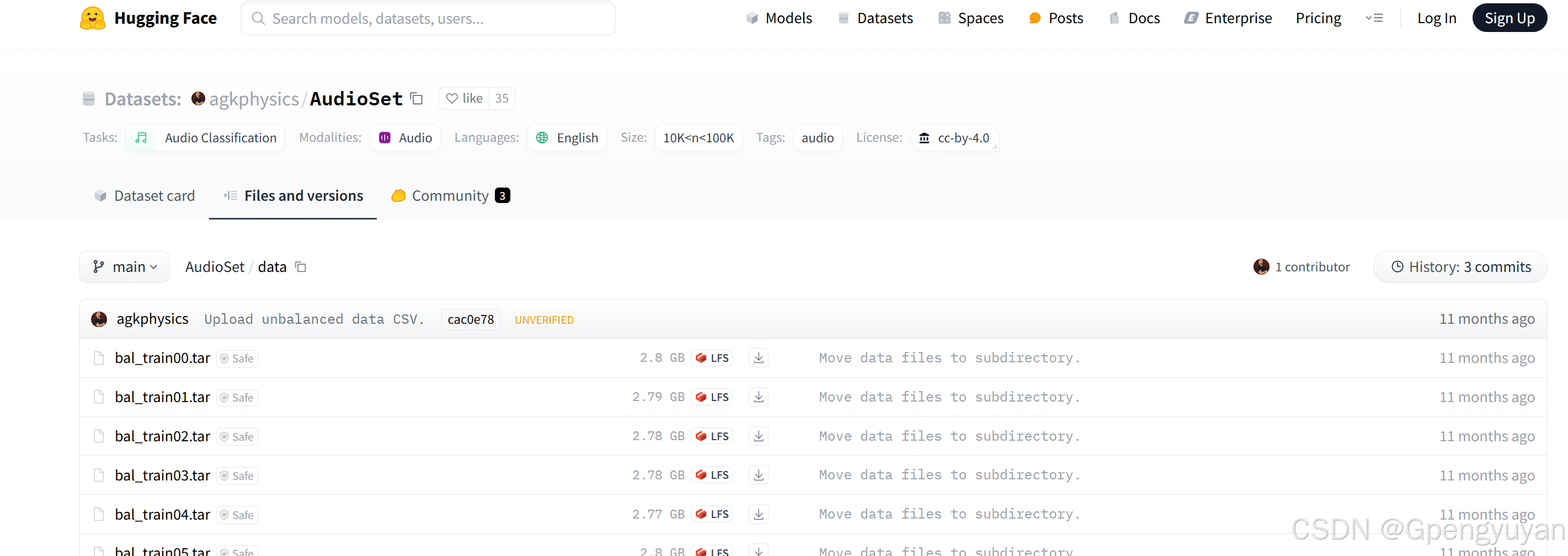
进入这里:agkphysics/AudioSet at main![]() https://huggingface.co/datasets/agkphysics/AudioSet/tree/main/data
https://huggingface.co/datasets/agkphysics/AudioSet/tree/main/data

















 4691
4691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









