






学习曲线:
随着训练样本的增多,模型在训练集和测试集的表现趋于一致。根据训练集合测试集的表现可以判断模型是过拟合和欠拟合。
查了很多关于sklearn的learning_curve的资料,没有找到其内部原理的文章,因此根据学习曲线的概念手动编写代码。
学习曲线的绘制过程如下:
(1)求出训练集的大小t=len(x_train)。
(2)训练集是一个长度为t的数据集,首先选择第一个数据进行建模,得到模型model1,然后使用model1在验证集上验证,得到评价分数score1;然后选择训练集的前2个数据进行建模,得到模型model2,然后使用model2在验证集上验证,得到评价分数score2;然后选择训练集的前3个数据,…重复上述操作,直到使用训练集的所有数据建模,并得到验证集的分数scoret。
(3)画图,横坐标为训练集的数据个数,纵坐标为在该训练个数下得到的评价分数score。
其中第2步中,如果定义了trainsize,则不需要循环t次,只需要按照trainsize定义的去计算。比如trainsize=[0.1,0.5,0.8,0.9,1.0],t=1000,则第二步只需要计算训练集为0.1t=100,0.5t=500,0.8t=800,0.9t=900,t=1000数量的时候,只需要循环5次。
示例代码
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
#构造一个6个特征的训练集,并以0.8为分割点,划分训练集和测试集
x = np.random.uniform(low=-1,high=1,size=(5000,6))
y = [3.4*i[0]+2.4*i[1]-0.9*i[2]+0.5*i[3]+0.7*i[4]-1.2*i[5]+np.random.uniform(low=-0.03,high=0.03) for i in x]
t = int(0.8*len(x))
X_train = x[:t]
y_train = y[:t]
X_test = x[t:]
y_test = y[t:]
#构造学习曲线函数
def learningCurve(model,X_train,y_train,X_test,y_test,trainsize):
#model是使用的模型,trainsize指使用多少个训练样本来求测试集的mse。
length = len(X_train)
#用来存储横坐标
xlist = []
#存储纵坐标的训练数据的mse
ylist_train = []
#存储纵坐标的测试数据的mse
ylist_test = []
for i in trainsize:
cutpoint = int(length*i)
if cutpoint == 0:
#为了防止在trainsize里有训练数据为0的时候,保证训练数据最少有1个。
cutpoint = 1
tempdatax = X_train[:cutpoint]
tempdatay = y_train[:cutpoint]
model.fit(tempdatax,tempdatay)
result_train = model.predict(tempdatax)
result_test = model.predict(X_test)
mse_train = mean_squared_error(tempdatay,result_train)
mse_test = mean_squared_error(y_test,result_test)
xlist.append(cutpoint)
ylist_train.append(mse_train)
ylist_test.append(mse_test)
fig,axes = plt.subplots(1,1)
axes.plot(xlist,ylist_train,'k-')
axes.plot(xlist,ylist_test,'r-')
plt.show()
#使用学习曲线函数画图
trainsize = np.linspace(0.01,0.999,20)
model = LinearRegression()
learningCurve(model,X_train,y_train,X_test,y_test,trainsize)
效果图
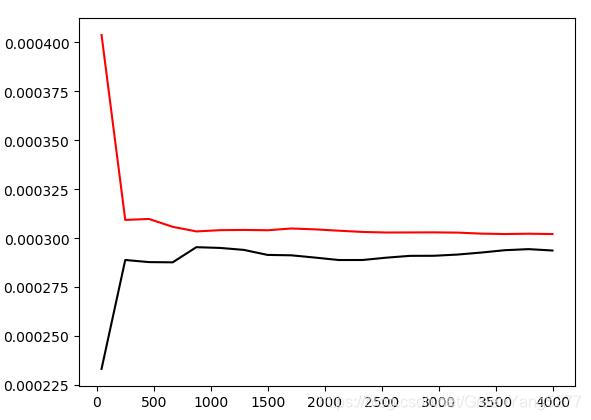
图中可以看出,训练集随着训练数据的增加,mse逐渐增大,而测试集随着训练数据的增加,mse逐渐减小。两条曲线随着训练数据的增大,趋于相同。
总结
本示例只是回归模型学习曲线画图。如果针对分类模型,纵坐标可以使用准确率来替代。希望可以为你的学习带来一点点的贡献。

















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









