







相关文件
关注小编,私信小编领取哟!
当然别忘了一件三连哟~~
对了大家可以关注小编的公众号哟~~
Python日志
大家好,我大胆又来了!
天天给大家分享小游戏啥的,肯定小伙伴都觉得有点无聊,今天给大家带来福利啦!!
今天我们又用Python来玩一个好玩的程序。随着收看直播的用户激增,越来越多的小姐姐们都在通过直播的方式和粉丝们交流互动。但是直播的界面中总是充斥着各种各样的广告推荐和弹幕信息,让我不能专注于欣赏小姐姐。
我们可以通过网页分析,来获取到小姐姐的直播信息源,然后通过本地的视频流播放器来收看小姐姐的直播。这让我感觉到小姐姐仿佛就在我的身边。既能锻炼自己的Python知识,又能欣赏小姐姐,岂不美哉。需要源码的+UP主Python学习交流群:773162165
01.直播信号抓取
首先,我们通过对于B站直播网页的分析,来获取小姐姐直播间的直播信号源。
大家可以任意打开一个B站小姐姐的直播间,如下图所示:

首先通过“F12”按键打开 “开发者模式”,然后在Network选项下,点击XHR组件。
通过翻阅可以找到以live开头的标签内容,双击之后,就可以得到请求的信息。
可以看到,这个Request URL就是直播的信号源。
# 确定url地址 获取每个视频的 ID
for page in range(5, 11):
print(f'=======================正在爬取第{page}页数据=======================')
url = f'https://v.huya.com/g/all?set_id=31&order=hot&page={page}'
"""
headers是什么? 请求头
请求头的作用是什么? 把python爬虫代码伪装浏览器对服务器发送请求 (如果不伪装: 服务器可能不会给你数据/ 给你的数据是错误的..)
请求头里面需要加那些东西呢? 这些东西有什么用呢?
user-agent: 浏览器的信息
cookies: 用户信息, 常用于检测是否有登录账号 爬VIP资料
referer: 防盗链 告诉服务器 我们请求的url地址是从哪里过来的
host: 域名,主机地址
headers 是字典的形式 : 键值对 一个键 对应一个值 键和值之间用:隔开的 值可以是任意类型 键 字符串 数字 元组
"""
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
程序抓取直播信号源
上述的方式,是通过手动的方式,来获取直播的信号源。
我们还可以通过程序的方式来进行直播信号源的获取。
直播信号源的接口地址为:
https://liveapi.huya.com/moment/getMomentContent?callback=jQuery112408236898064701803_1620994683221&videoId=485192023&uid=&_=1620994683241
为了获取视频源的地址,需要向上述的连接中,传递几个参数,分别为:
我们抓取的视频我们都可以直接放在我们建立的文件夹里面:
# 自动创建文件夹
filename = 'video\\'
我们抓取数据之后需要进行解析:
# 解析数据
"""
.*? 通配符 可以匹配任意字符 \d 匹配一个数字 \d+ 匹配多个数字
正则表达式 提取出来的内容 是一个列表的形式
"""
video_ids = re.findall('<a href="/play/(\d+)\.html" class="video-wrap statpid"', response.text)
# print(video_ids)
for index in video_ids:
# 爬虫入门简单 越到后面越难 难在解密 以及数据查找
# get 请求的url地址 ? 后面一大串内容 都是属于请求参数
index_url = 'https://liveapi.huya.com/moment/getMomentContent'
# params 请求参数
# 如果你post 请求 data表单
params = {
# 'callback': 'jQuery112408236898064701803_1620994683221',
'videoId': index,
'uid': '',
'_': '1620994683241',
}
response_1 = requests.get(url=index_url, params=params, headers=headers)
# pprint.pprint(response_1.json())
# 怎么提取json数据内容: 根据键值对 取值, 根据冒号左边的键 提取 冒号右边的值
video_url = response_1.json()['data']['moment']['videoInfo']['definitions'][-1]['url']
video_title = response_1.json()['data']['moment']['videoInfo']['videoTitle']
然后就是对数据进行保存:
# 保存数据
# 获取二进制数据内容
video_content = requests.get(url=video_url, headers=headers).content
with open(filename + video_title + '.mp4', mode='wb') as f:
f.write(video_content)
print(video_title, video_url)
最后咋们来看看效果吧:
使用Ctrl+shift+F10运行代码:

然后打开我们创建的文件夹video查看我们爬取的视频:
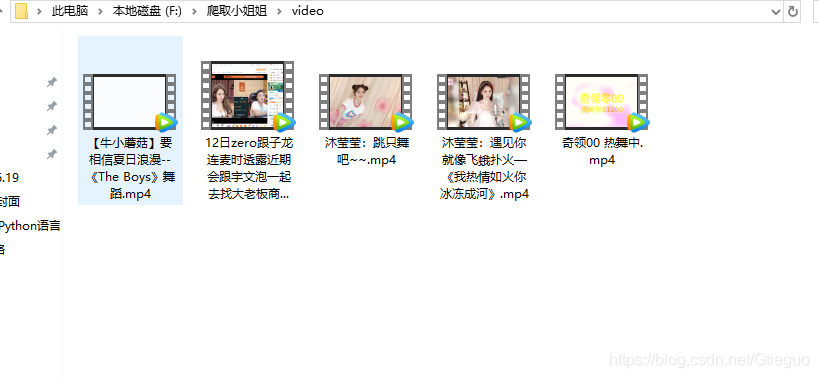
好啦,今天的福利就给大家安利到这里啦,有啥不懂的大家可以在下方评论,需要源码的可以找小编领取哟,记得关注小编的公众号哈~
很多小伙伴在学习python的时候总会遇到一些问题和瓶颈,没有方向感,不知道该从哪里入手去提升,对此我整理了一些资料,希望能够去帮助到小伙伴们,可以加Python学习交流裙:773162165














 1787
1787











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









