







李宏毅深度学习
一、深度学习的简单介绍
Deep Learning的三个步骤:
-
− S t e p 1 − : d e f i n e a s e t o f f u n c t i o n -Step1-:define\ a\ set\ of\ function −Step1−:define a set of function(给出一个 n e t w o r k s t r u c t u r e network\ structure network structure就相当于定义了一个函数集合)
-
− S t e p 2 − : g o o d n e s s o f f u n c t i o n - Step2-:goodness\ of\ function −Step2−:goodness of function
-
− S t e p 3 − : p i c k t h e b e s t f u n c t i o n - Step3-:pick\ the\ best\ function −Step3−:pick the best function
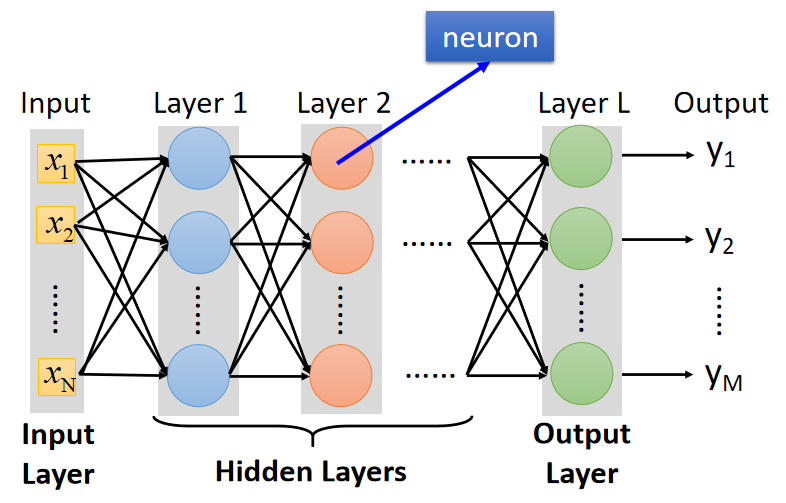
全连接层前馈网络 ( F u l l y C o n n e c t F e e d f o r w a r d N e t w o r k ) (Fully\ Connect \ Feedforward\ Network) (Fully Connect Feedforward Network):
接收输入数据的第 0 0 0层称为输入层,中间由很多neuron组成的层称为隐藏层,输出结果的第 L L L层称为输出层。
矩阵运算 ( M a t r i x O p e r a t i o n ) (Matrix Operation) (MatrixOperation):
在神经网络中一般采用矩阵运算,不仅方便表示,还能加速运算。第
1
1
1层输出的矩阵运算如下图所示:
(假设激活函数
σ
σ
σ使用的是
s
i
g
m
o
i
d
sigmoid
sigmoid)
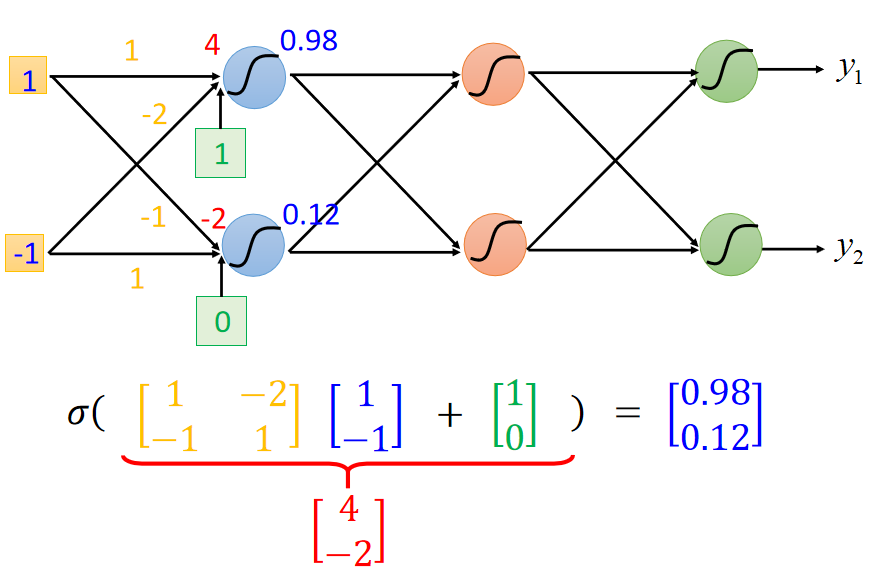
将各层的参数都进行向量化,神经网络的前向传播做的其实就是很多的矩阵运算,如下图:
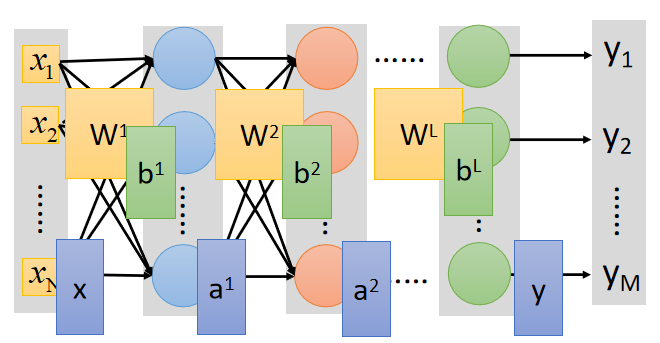
W 1 、 b 1 W^1、b^1 W1、b1表示第 0 0 0层(输入层)和第 1 1 1层之间的权重和偏置的向量化表示。
第
1
1
1层的的输出
a
1
a^1
a1的表达式为:
a
1
=
σ
(
W
1
⋅
x
+
b
1
)
a^1=σ(W^1\cdot x+b^1)
a1=σ(W1⋅x+b1)
同理第
2
2
2层
a
2
a^2
a2的输出为:
a
2
=
σ
(
W
2
⋅
a
1
+
b
2
)
=
σ
(
W
2
⋅
σ
(
W
1
⋅
x
+
b
1
)
+
b
2
)
a^2=σ(W^2\cdot a^1+b^2)=σ(W^2\cdot σ(W^1\cdot x+b^1)+b^2)
a2=σ(W2⋅a1+b2)=σ(W2⋅σ(W1⋅x+b1)+b2)
依此类推,第L层的输出为:
a
L
=
σ
(
W
L
⋯
σ
(
W
2
⋅
σ
(
W
1
⋅
x
+
b
1
)
+
b
2
)
+
b
L
)
a^L=σ(W^L\cdots σ(W^2\cdot σ(W^1\cdot x+b^1)+b^2)+b^L)
aL=σ(WL⋯σ(W2⋅σ(W1⋅x+b1)+b2)+bL)
在做这些矩阵运算的时候,就可以通过GPU来进行计算,加速运算过程。
将输出层作为多元分类器:
此时的输入的 X X X是待分类对象的 f e a t u r e s features features;中间隐藏层做的工作是接收前一层的特征输入并提取/转换特征作为下一层的输入;最后一层接收的结果是通过提炼的、抽象的 f e a t u r e s features features,通过一个简单的 s o f t m a x softmax softmax输出分类结果。
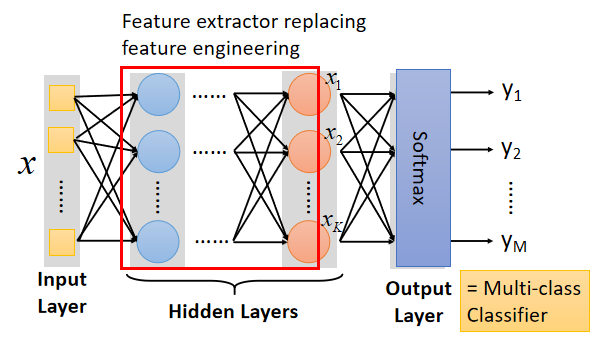
以手写数字识别为例子,如下图:
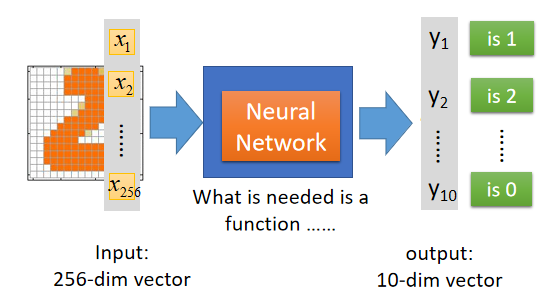
将 16 × 16 16\times16 16×16的图片平铺展开成256维度的向量作为神经网络输入的 f e a t u r e s features features,最后输出层经过 s o f t m a x softmax softmax函数输出 10 10 10个概率值作为输出,选中其中概率最大的作为分类结果。
goodness of function:
确定 n e t w o r k s t r u c t u r e network\ structure network structure后,如何定义一个好的 f u n c t i o n function function呢?
在分类问题中一般常用交叉熵作为损失函数,交叉熵是比较两个不同分布模型(理想模型和现实模型)之间距离的度量。
如下图,神经网络通过前向传播输出预测结果 y y y,使用交叉熵来判断预测结果 y y y和实际结果 y ^ \hat{y} y^之间还有多少“距离”。
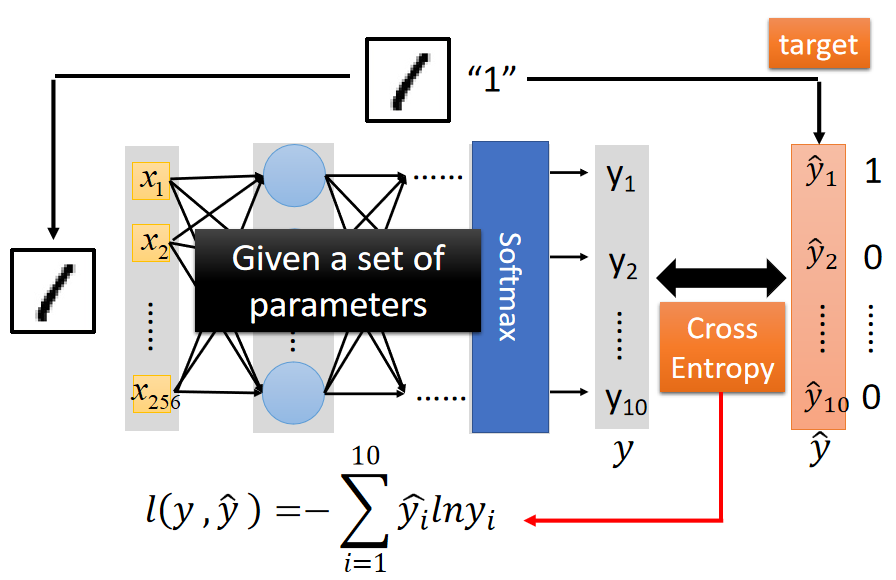
交叉熵表达式为:
l
(
y
,
y
^
)
=
−
∑
i
=
1
10
y
^
i
⋅
l
o
g
y
i
l(y,\hat{y})=-\sum\limits_{i=1}^{10} {\hat{y}_i\cdot log\ y_i}
l(y,y^)=−i=1∑10y^i⋅log yi
然后对每个训练样本的Loss求和,计算整体的损失 L o s s Loss Loss:
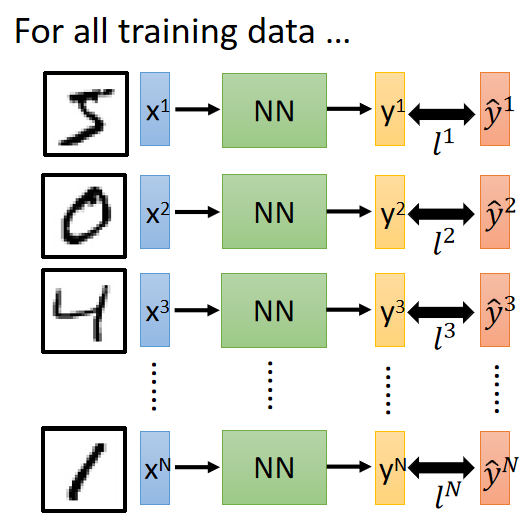
整体损失函数值
L
L
L表达式为:
T
o
a
l
L
o
s
s
=
L
=
∑
n
=
1
N
l
n
Toal \ Loss=L=\sum\limits_{n=1}^{N} {l^n}
Toal Loss=L=n=1∑Nln
后面的事情就是使用 g r a d i e n t d e s c e n d gradient\ descend gradient descend来找到使 L L L最小化的参数。
二、为什么要做“深度”学习?
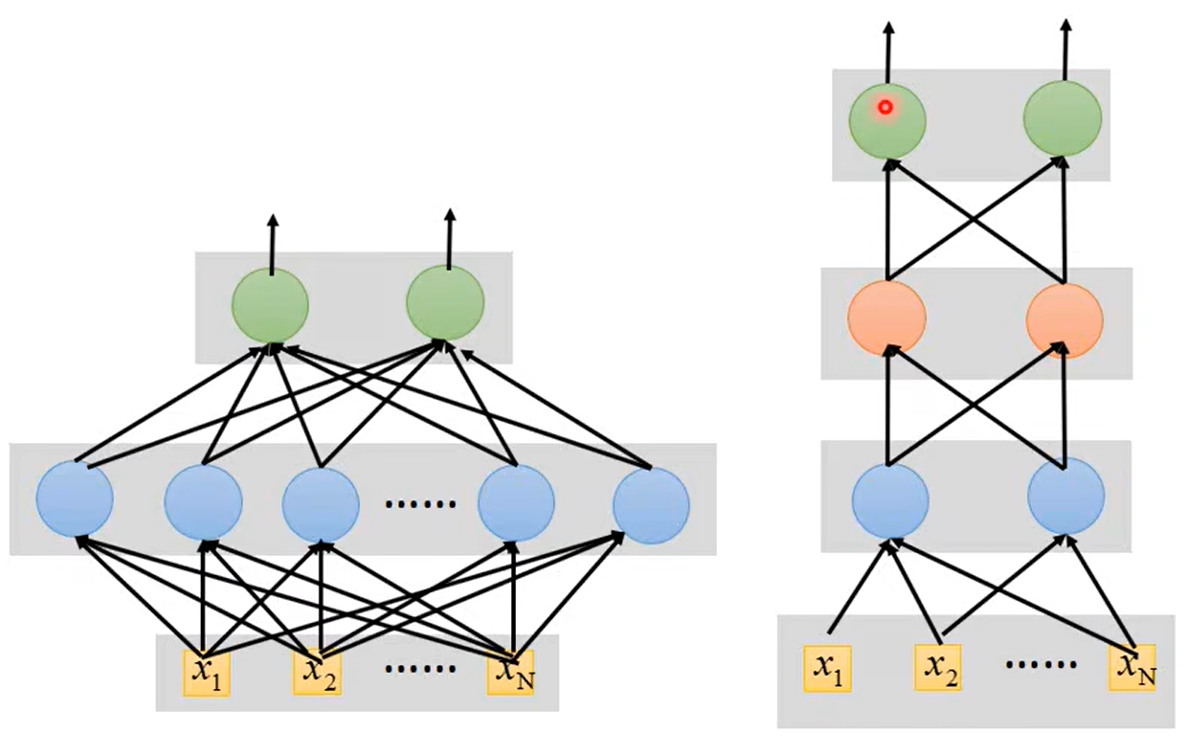
参数一样的情况下,让模型更“高”比更“宽”更有用
如下面两个图,左边的模型结构宽而短,右边的模型窄而高。为什么参数相同的情况下右边的模型会更好一些呢?
这就像平时在写的程序,我们不会将所有功能实现都放在 m a i n f u n c t i o n main\ function main function中。我们会更愿意将功能模块化( m o d u l a r i z a t i o n modularization modularization),如下图:
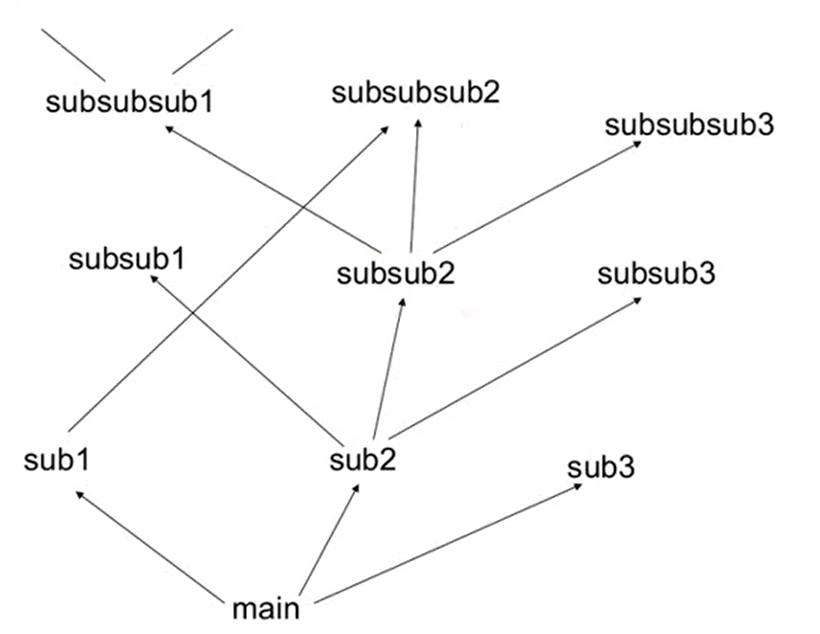
结构化的编程的好处是很多函数都可以重复使用,深层的功能实现也能很好的调用浅层的功能。
将
m
o
d
u
l
a
r
i
z
a
t
i
o
n
modularization
modularization的概念带入到神经网络实例中去,假设我们要对图片进行分类,分出长头发女生、长头发男生、短头发男生、短头发女生4各类别。数据集情况如下图所示:

当使用窄而宽的神经网络直接去训练这个分类器时,长头发男生训练样本太少,那么分类器对长头发男生的分类效果就会很差。
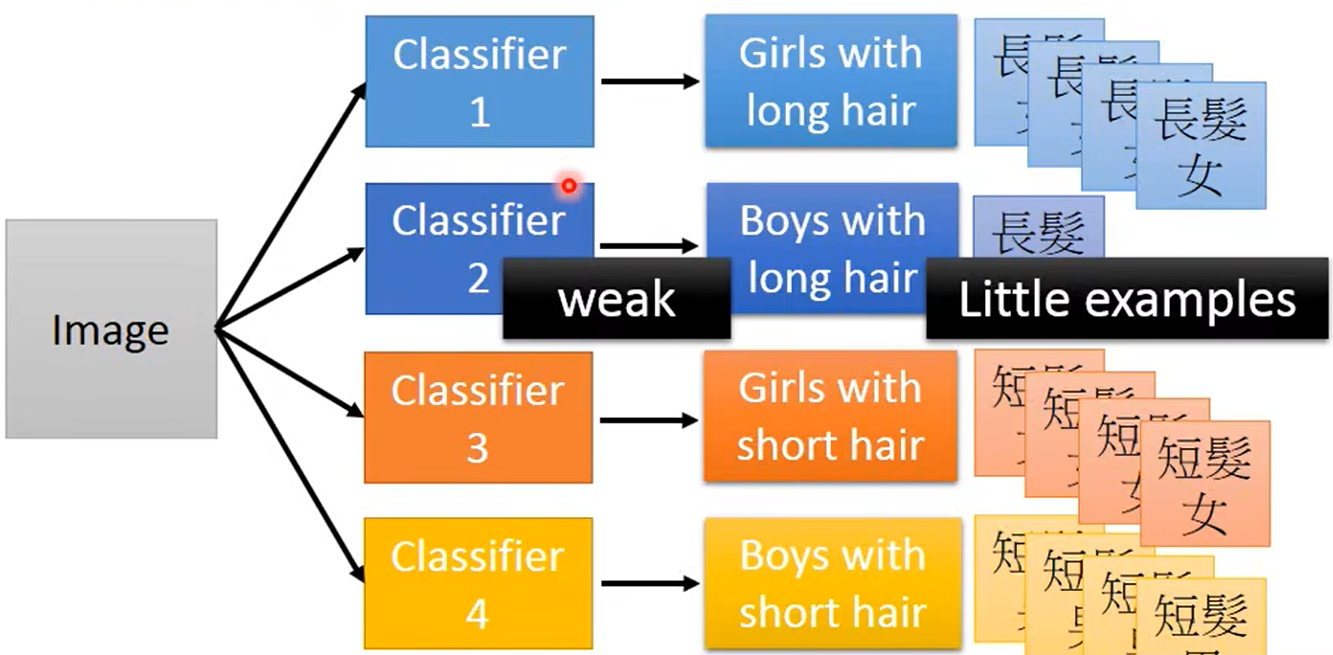
我们使用
m
o
d
u
l
a
r
i
z
a
t
i
o
n
modularization
modularization将这个问题分成两个
B
a
s
i
c
C
l
a
s
s
i
f
i
e
r
Basic\ Classifier
Basic Classifier:是男孩还是女孩、长头发还是短头发。
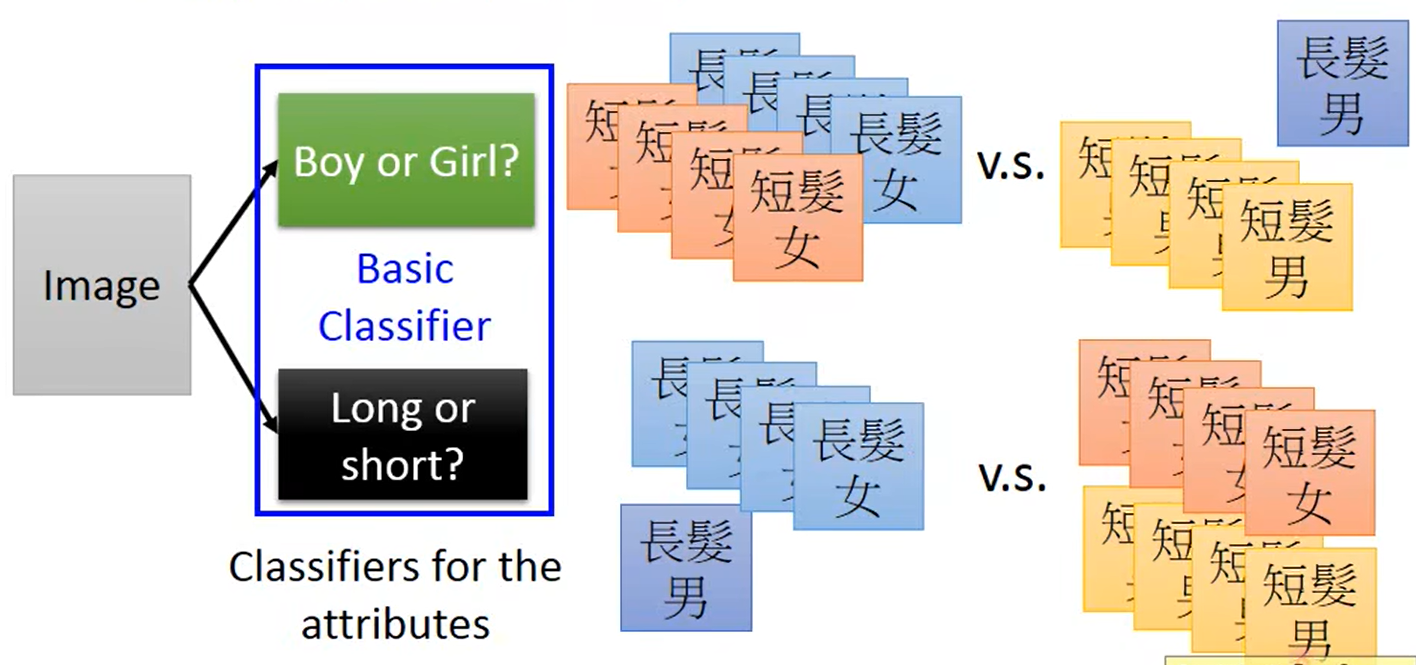
这样这两个子分类问题训练样本都比较充足;再将这两个问题的结果用于训练分类器分类,这样长头发男生虽然数据较少,但是也能获得比较好的分类结果。
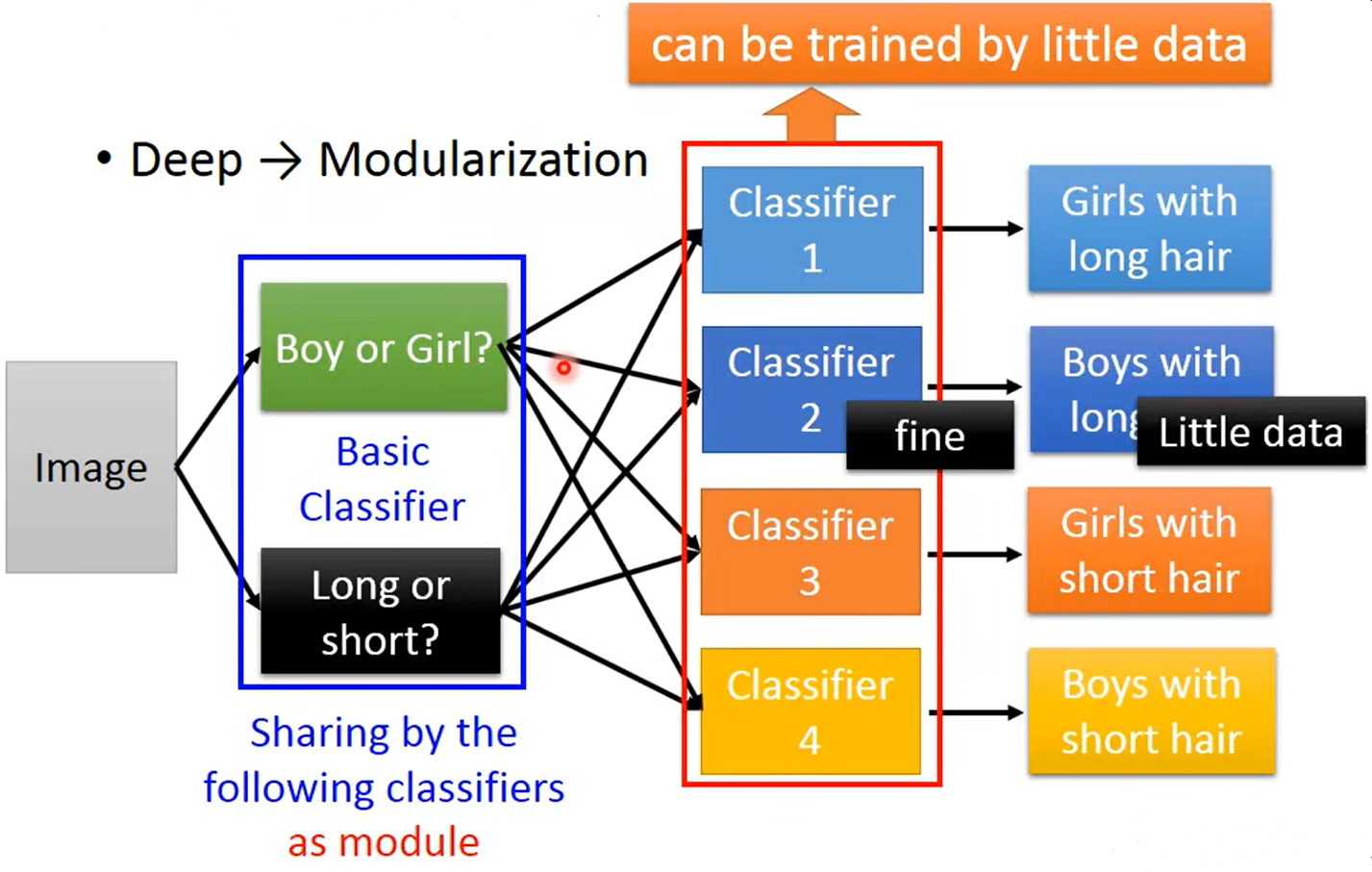
综上所述,当我们使用窄而高的模型进行分类时,就类似是将问题分解成了几个小问题,再用子问题的有用信息去解决更复杂的信息。
如下图所示,第一层可以看成 T h e m o s t b a s i c c l a s s i f i e r s The\ \ most\ \ basic\ \ classifiers The most basic classifiers(最基本的分类子问题),第二层就会使用第一层的子问题的分类结果去解决更复杂的 b a s i c c l a s s i f i e r s basic\ classifiers basic classifiers问题。
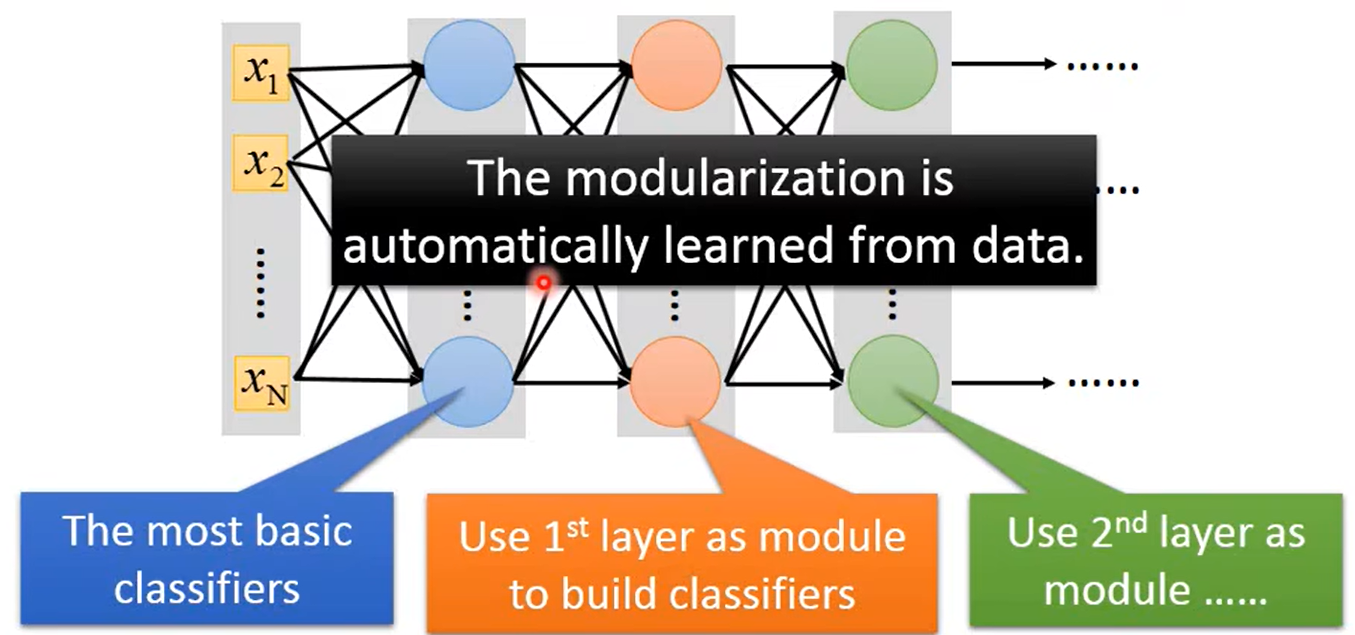
所以在做Deep learning解决问题时,就是将问题模块化的过程,而如何模块化是机器自动从数据中学习到的。
Universality Theorem:
存在一个理论:
当隐藏层的的神经节点足够的多,任何连续函数(
c
o
n
t
i
n
u
o
u
s
f
u
n
c
t
i
o
n
continuous\ function
continuous function)
f
f
f:
f
:
R
N
→
R
M
f:R^N →R^M
f:RN→RM
都能被只有一个隐藏层的1神经网络学习到。
是的,短而宽的神经网络能够表示任何的函数;但是,使用窄而宽的深层结构会更有效率。
就像逻辑电路( l o g i c a l c i r c u i t logical\ circuit logical circuit),逻辑电路由一个一个的门( g a t e gate gate)组成。两层的 g a t e gate gate就能够代表任何的布尔函数( B o o l e a n f u n c t i o n Boolean\ function Boolean function);但是使用更多层的逻辑门去建立这些布尔函数会更简单、更加有效率。
具体例子,若想要构建一个奇偶校验的逻辑电路,如下图:
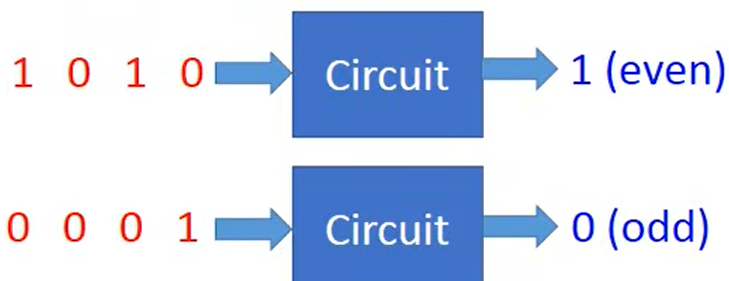
仅使用两层逻辑电路对
d
d
d个序列数进行奇偶校验,需要
O
(
2
d
)
O(2^d)
O(2d)数量级的
g
a
t
e
gate
gate;而使用深层的逻辑电路来表示,仅需要
O
(
d
)
O(d)
O(d)数量级的
g
a
t
e
gate
gate就能表示。如下图,三个
g
a
t
e
gate
gate就能进行奇偶校验:
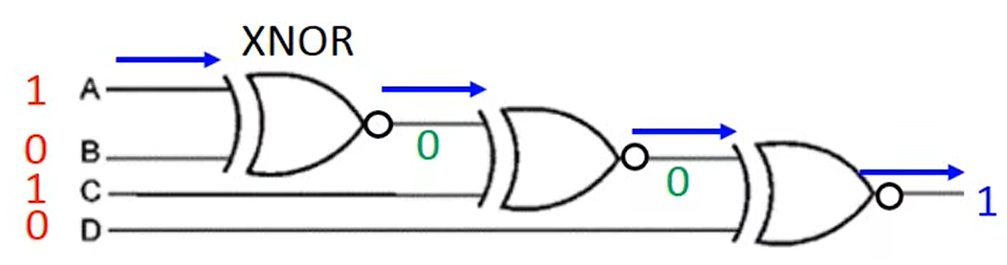
所以当我们使用 D e e p l e a r n i n g Deep\ \ learning Deep learning时,相比一层隐藏层的神经网络可以使用相对更少的神经节点,从而使用更少的参数,一方面避免了过拟合,另一方面可以使用更少的数据去训练模型。
端到端学习 ( E n d − t o − e n d L e a r n i n g ) (End-to-end\ Learning) (End−to−end Learning):
当我们使用 D e e p L e a r n i n g Deep\ Learning Deep Learning后,我们就可以使用端到端的学习;使用一个深层神经网络来省略复杂繁琐的人工操作。
什么是 E n d − t o − e n d L e a r n i n g End-to-end\ Learning End−to−end Learning看这个链接
Deep Learning 能够解决复杂的任务:
-
C o m p l e x T a s k 1 Complex\ Task1 Complex Task1:相似的输入,不同的输出;

-
C o m p l e x T a s k 2 Complex\ Task2 Complex Task2:不同的输入,相似的输出;
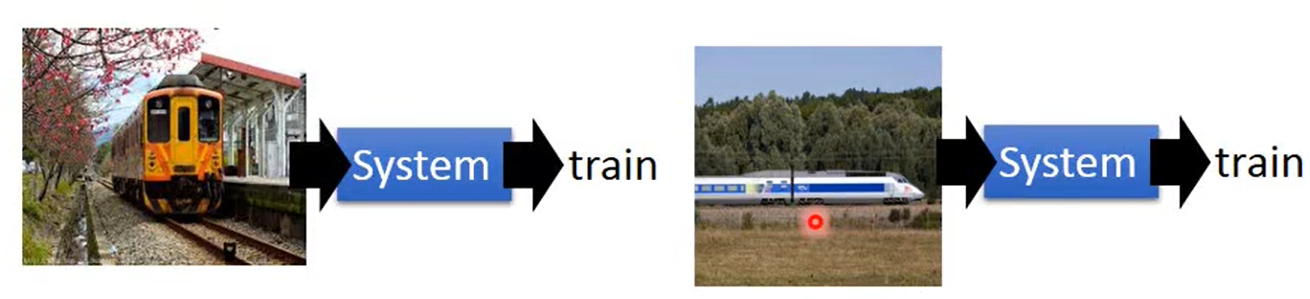
举一个语音识别的例子,收集了多个不同人说同一句话的语音,并降维到二维上进行可视化。如下图,相同颜色的代表同一个人说的语音,可以看同一句话被不同的人说都会有很大的差异。
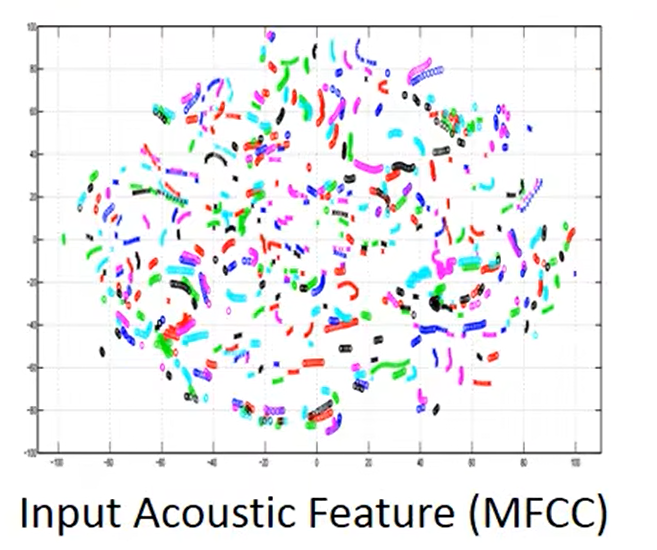
将上述式子输入到训练好的
D
e
e
p
L
e
a
r
n
i
n
g
Deep\ Learning
Deep Learning模型中,输出第
8
8
8层的输出:
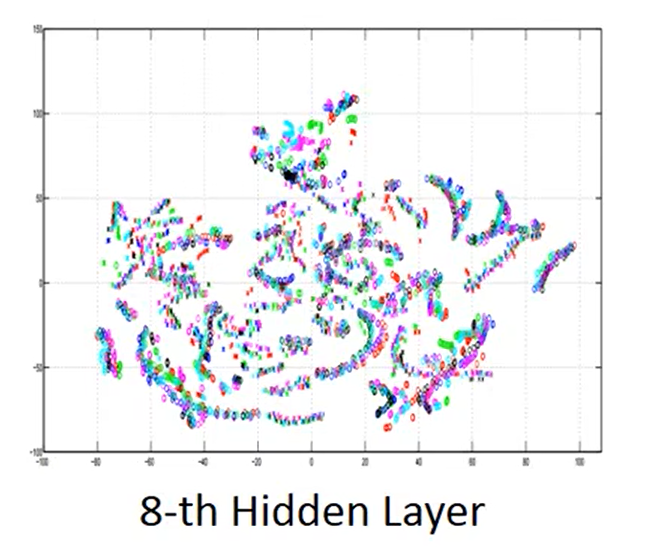
神奇的事情发生了,不同人的同一句话的语音变得十分的相似。
三、总结
- D e e p L e a r n i n g Deep\ Learning Deep Learning自动的对问题进行模块化;
- 参数一样的情况下,让模型更“高”比更“宽”更有用;
- 使用“深度”学习会更有效率;
- D e e p L e a r n i n g Deep\ Learning Deep Learning 能够解决复杂的任务。














 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









