






新项目可用!!爬取Google,Baidu,Sougou搜索引擎中的图片
项目地址GitHub:🔗点我跳转
图片下载工具
✨如果有用的话,麻烦点个Star吧~
本程序使用Python语言采用Selenium工具完成对网页图片的爬取,现已支持Google,Baidu,Sougou搜索引擎的图片下载
本项目依托于Chrome浏览器进行,请确保电脑上安装有Chrome浏览器
❗注意:若采用Google引擎下载图片时,请科学上网,否则无法访问到资源。
📍运行时强烈建议使用--disable_gui=True选项(默认选项),并保证所打开的浏览器窗口在界面前端
1. 程序运行方式
- step 1 创建环境并安装相关依赖
conda create -n pic_download python=3.10
conda activate pic_download
pip install requirement.txt
- 程序运行指令(命令行)
python main.py --query=keywords --engine=google,baidu,sogou --min_count=500
- 也可以采用Pycharm等工具运行,运行文件为
main.py webpic下的三个文件分别对应不同搜索引擎的爬虫实现编码,也可直接运行
2. 程序运行相关参数
--query:(type:str) 搜索关键词
--engine:(type:str) 所要使用的图片搜索引擎,目前可采用参数为google,baidu,sougou,不区分顺序,可一次填写一个或多个搜索引擎
--disable_gui:(type:bool)是否禁用浏览器界面,默认为False,建议采用False选项,若采用True选项可能导致网页资源加载失败,从而导致抓取不到网页上的图片链接。
--disable_logs:(type:bool)是否禁用系统日志,默认为True,此选项是为了过滤掉使用控制台来运行程序时,控制台所输出的无用日志。
--save_path:(type:str)文件保存路径,默认为当前程序目录。
--sleep_time:(type:float)网页进行下一步操作时所等待网页响应的时间,默认为3秒,此选项可根据实际网速进行调整,不应设置的过小,设置的过小可能会产生网页资源未全部加载完成所导致的资源寻找不到的问题。
--use_implicitly_wait:(type:bool)是否采用隐式等待,默认开启。开启后可提升程序运行效率,建议使用。
--min_count:(type:int)每个搜索引擎所需下载的图片数量,默认为500张,超过500张后,程序会自动停止。该设置并不是精确值,由于程序采用整页图片下载,实际下载图片数量会比设置值高一些。
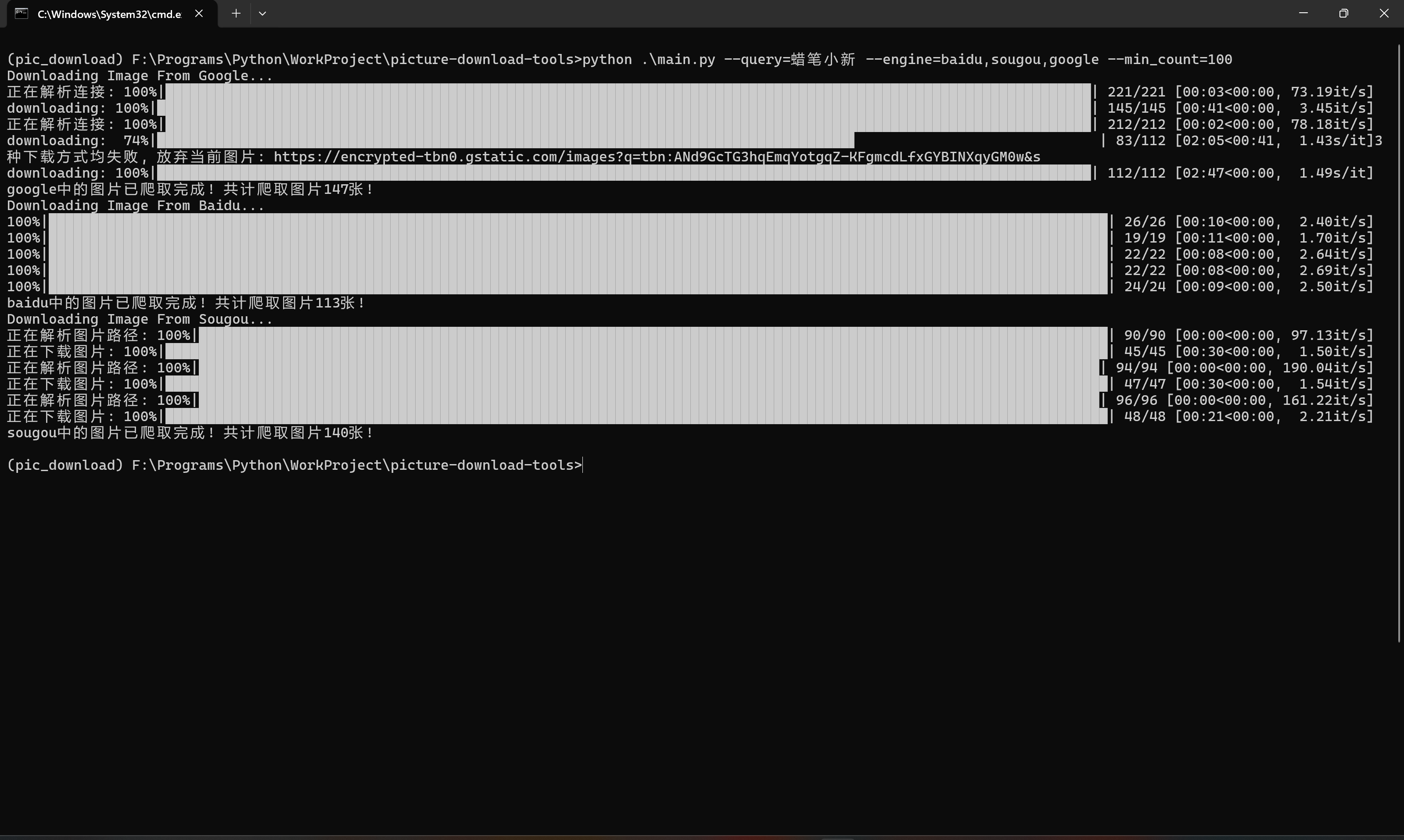
3. 程序实际运行截图
- 程序运行界面
-
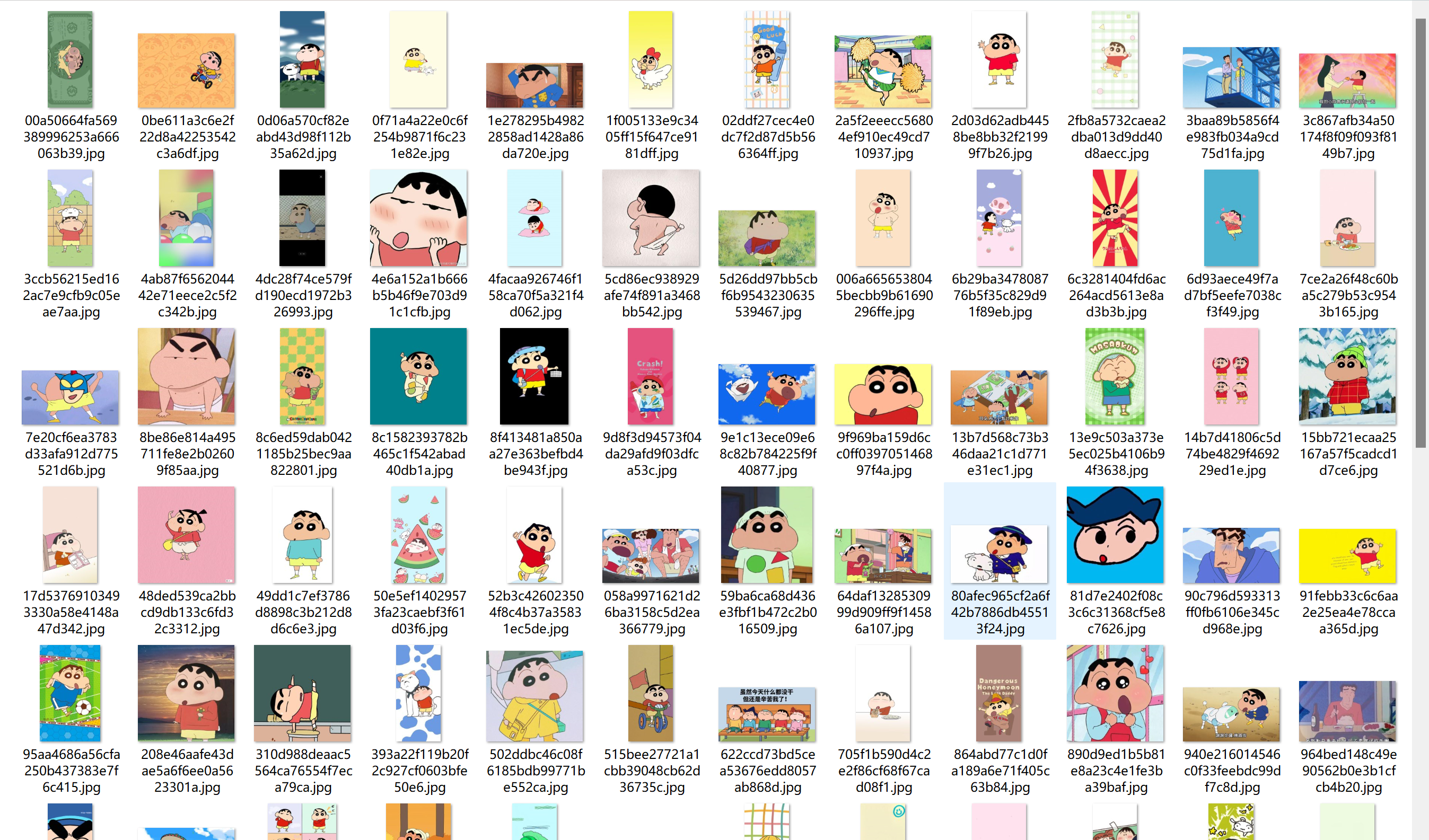
所下载的图片部分展示
- 百度
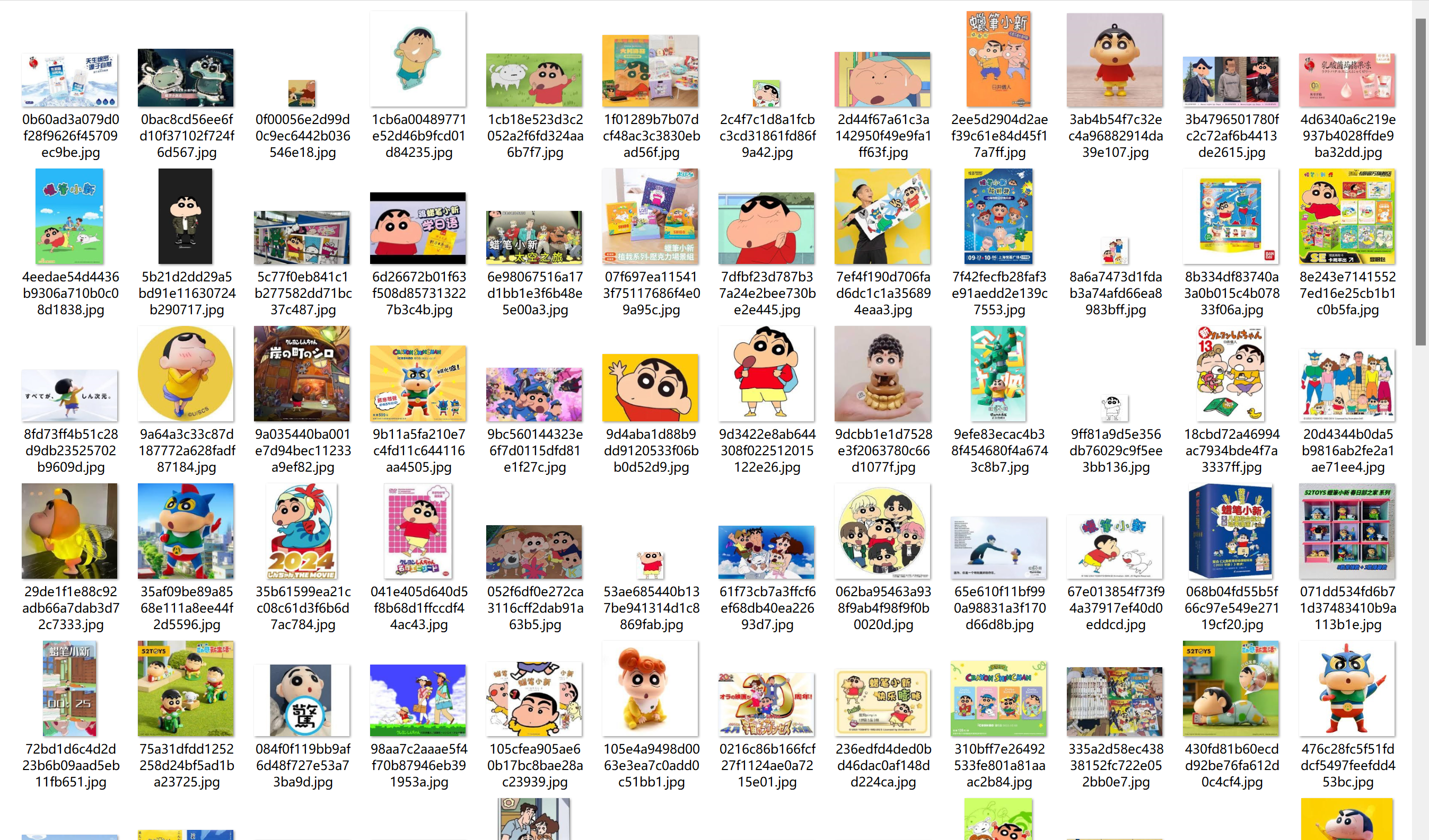
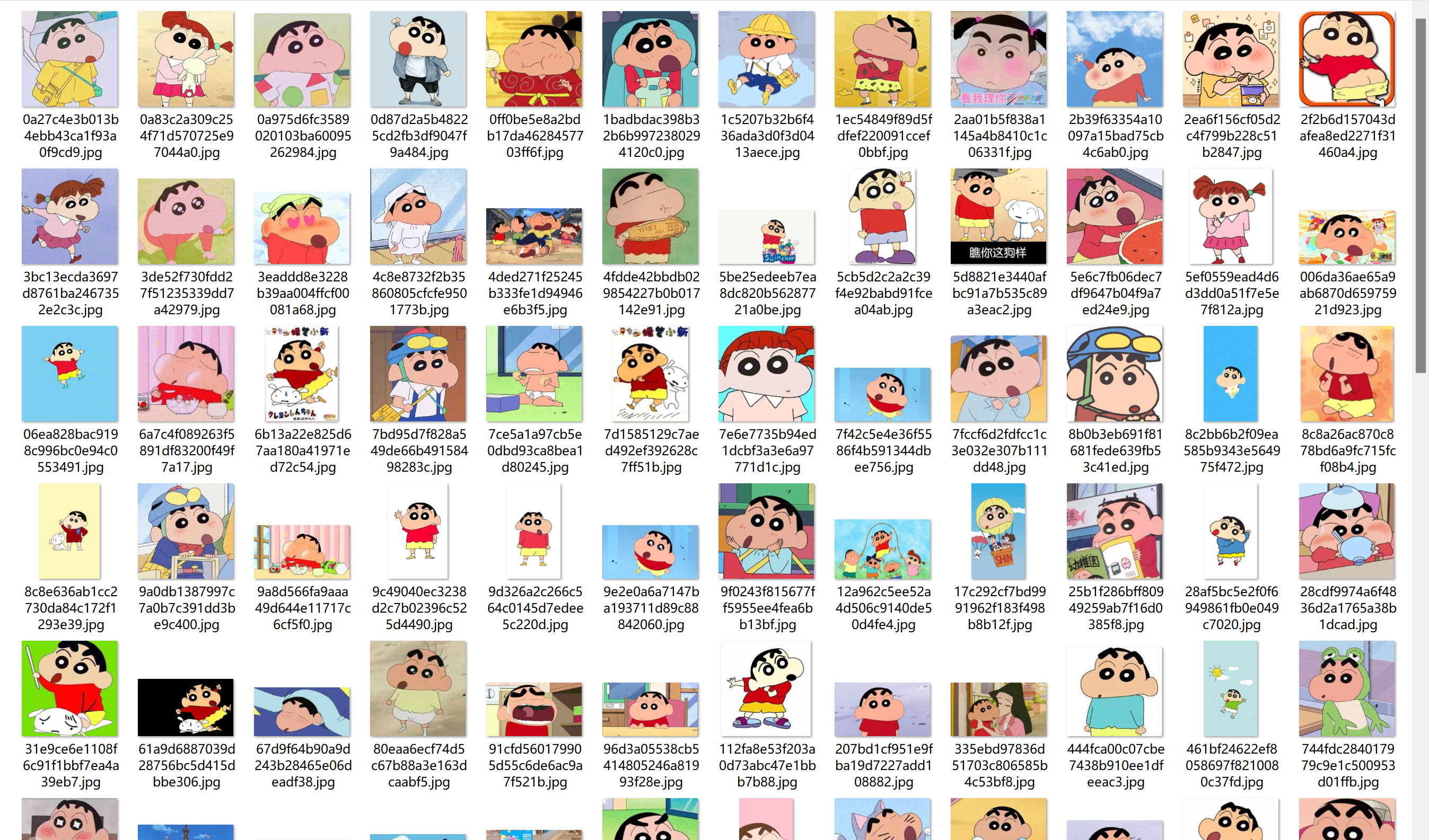
- Sougou
4. Tips
如有问题请在Issue中询问















 6040
6040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









