







 本文介绍如何使用Python抓取搜狗图片网站上的图片,包括分析页面结构以找到动态加载图片的URL,并通过tkinter创建展示图片的简单UI界面。内容涉及网页源码解析、动态加载图片的处理以及爬虫实现。
本文介绍如何使用Python抓取搜狗图片网站上的图片,包括分析页面结构以找到动态加载图片的URL,并通过tkinter创建展示图片的简单UI界面。内容涉及网页源码解析、动态加载图片的处理以及爬虫实现。
1.利用python抓取网站上的图片,对于学习python及对网页数据分析处理很有帮助,也可以学习一些web方面的知识,我尝试使用【搜狗图片】搜索到的图片作为抓取对象,抓取【搜狗图片】主页各个标题栏的图片,以及【其他】输入图片类型的图片,使用tkinter完成了一个简单的UI界面。
2.一般抓取网页图片,需要先访问页面,然后提取源码,依次解析各个图片URL,然后直接下载即可,这些网上的教程很多,在此不再赘述。但是对于一些图片较多的页面,往往使用动态加载的方式呈现图片,也就是我们抓取的页面源码中,并没有各个图片的URL,这就需要 分析页面结构,找到页面图片真正的URL资源地址,才能完成下载。
3.例如在【搜狗图片】搜索美女,然后点进图片,查找该图片的URL地址:
【请求URL】:

【页面源码】:找不到对应的图片URL。
但是通过分析发现图片是动态加载出来的,然后参考了 Python爬取网页中的图片(搜狗图片)详解 ,
发现【标题类】的图片都集中在如下URL:


而通过【搜索】得到得图片URL集中在:

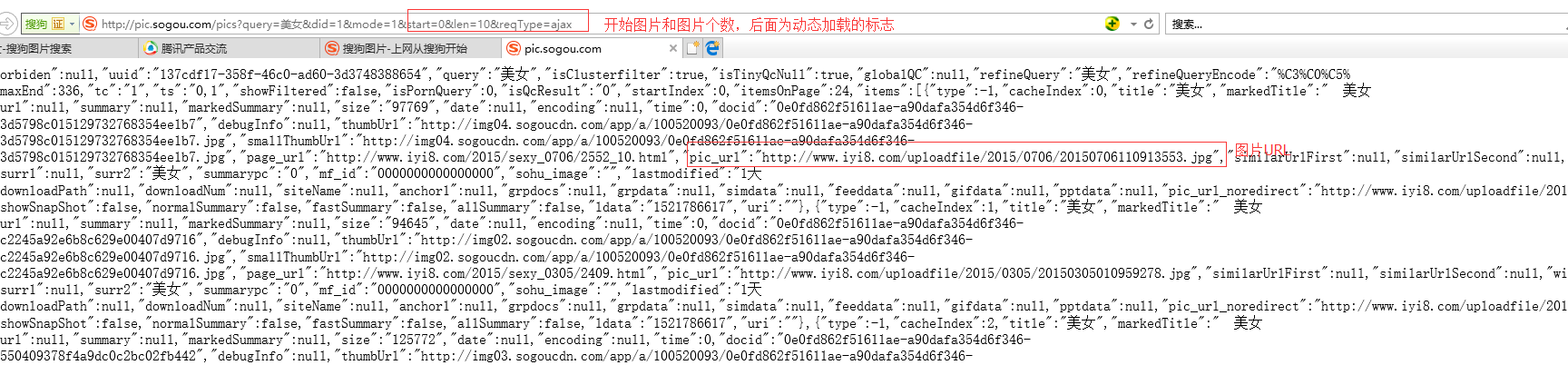
这样,就可以很清楚的得到各个图片URL的地址,爬取图片了。
4.源码:
#-*- encoding=UTF-8 -*-
import urllib.request,socket,re,sys,os
from urllib.request import urlopen
import time
from tkinter import *
import webbrowser
from bs4 import BeautifulSoup
import requests
import json
import urllib
##############################常量区##############################
sougou_url="http://pic.sogou.com/"
###URL
download_pics_path="C:/bz2018/"
download_pics_num=10
download_success = ""
sougou_pics_tag=["pic_url","thumbUrl","bthumbUrl","ori_pic_url"]
sougou_url_pics_start="http://pic.sogou.com/pics/channel/getAllRecomPicByTag.jsp?category="
sougou_url_pics_mid="&tag=%E5%85%A8%E9%83%A8&start=0&len="
sougou_url_pics_start_other="http://pic.sogou.com/pics?query="
sougou_url_pics_mid_other="&did=1&mode=1&start=0&len="
sougou_url_pics_stop_other= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









