







如你所见,在NIO中,数据的读写操作始终是与缓冲区相关联的。Channel将数据读入缓冲区,然后我们又从缓冲区访问数据。写数据时,首先将要发送的数据按顺序填入缓冲区。基本上,缓冲区只是一个列表,它的所有元素都是基本数据类型(通常为字节型)。缓冲区是定长的,它不像一些类那样可以扩展容量(例如,List,StringBuffer等)。注意,ByteBuffer是最常用的缓冲区,因为:1)它提供了读写其他数据类型的方法,2)信道的读写方法只接收ByteBuffer。那么其他类型的信道,如IntBuffer,DoubleBuffer等的优点在哪呢?稍安毋躁!答案将在第5.4.6节揭晓。
5.4.1 Buffer索引
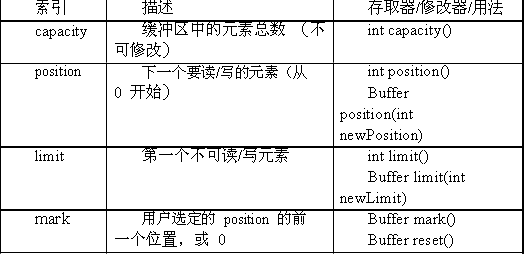
缓冲区不仅仅是用来存放一组元素的列表。在读写数据时,它有内部状态来跟踪缓冲区的当前位置,以及有效可读数据的结束位置等。为了实现这些功能,每个缓冲区维护了指向其元素列表的4个索引,如表5.1所示。(不久我们将看到如何使用缓冲区的各种方法来修改索引值。)
表5.1:缓冲区内部状态
position和limit之间的距离指示了可读取/存入的字节数。Java中提供了两个方便的方法来计算这个距离。
ByteBuffer:剩余字节
boolean hasRemaining()
int remaining()
当缓冲区至少还有一个元素时,hasRemaining()方法返回true,remaining()方法返回剩余元素的个数。
在这些变量中,以下关系保持不变:
0 ≤ mark ≤ position ≤ limit ≤ capacity
mark变量的值"记录"了一个将来可返回的位置,reset()方法则将position的值还原成上次调用mark()方法后的position值(除非这样做会违背上述的不变关系)。
5.4.2创建 Buffer
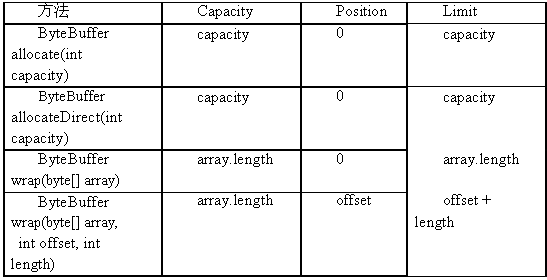
通常使用分配空间或包装一个现有的基本类型数组来创建缓冲区。创建ByteBuffer的静态工厂方法,以及相应的capacity,position,和limit的初始值见表5.2。所有新创建的Buffer实例都没有定义其mark值,在调用mark()方法前,任何试图使用reset()方法来设置position的值的操作都将抛出InvalidMarkException异常。
要分配一个新的实例,只需要简单地调用想要创建的缓冲区类型的allocate()静态方法,并指定元素的总数:
ByteBuffer byteBuf = ByteBuffer.allocate(20);
DoubleBuffer dblBuf = DoubleBuffer.allocate(5);
表5.2:ByteBuffer 创建方法
在上面代码中,byteBuf分配了20个字节,dblBuf分配了5个Java的double型数据。这些缓冲区都是定长的,因此无法扩展或缩减它们的容量。如果发现刚创建的缓冲区容量太小,惟一的选择就是重新创建一个大小合适的缓冲区。
还可以通过调用wrap()静态方法,以一个已有的数组为参数,来创建缓冲区:
byteArray[] = new byte[BUFFERSIZE];
// ...Fill array...
ByteBuffer byteWrap = ByteBuffer.wrap(byteArray);
ByteBuffer subByteWrap = ByteBuffer.wrap(byteArray, 3,
3);
通过包装的方法创建的缓冲区保留了被包装数组内保存的数据。实际上,wrap()方法只是简单地创建了一个具有指向被包装数组的引用的缓冲区,该数组称为后援数组。对后援数组中的数据做的任何修改都将改变缓冲区中的数据,反之亦然。如果我们为wrap()方法指定了偏移量(offset)和长度(length),缓冲区将使用整个数组为后援数组,同时将position和limit的值初始化为偏移量(offset)和偏移量+长度(offset+length)。在偏移量之前和长度之后的元素依然可以通过缓冲区访问。
使用分配空间的方式来创建缓冲区其实与使用包装的方法区别不大。惟一的区别是allocate()方法创建了自己的后援数组。在缓冲区上调用array()方法即可获得后援数组的引用。通过调用arrayOffset()方法,甚至还可以获取缓冲区中第一个元素在后援数组中的偏移量。使用wrap()方法和非零偏移量参数创建的缓冲区,其数组偏移量依然是0。
到目前为止,我们实现的所有缓冲区都将数据存放在Java分配的后援数组中。通常,底层平台(操作系统)不能使用这些缓冲区进行I/O操作。操作系统必须使用自己的缓冲区来进行I/O,并将结果复制到缓冲区的后援数组中。这些复制过程可能非常耗费系统资源,尤其是在有很多读写需求的时候。Java的NIO提供了一种直接缓冲区(direct buffers)来解
决这个问题。使用直接缓冲区,Java将从平台能够直接进行I/O操作的存储空间中为缓冲区分配后援存储空间,从而省略了数据的复制过程。这种低层的、本地的I/O通常在字节层进行操作,因此只能为 ByteBuffer进行直接缓冲区分配。
ByteBuffer byteBufDirect =ByteBuffer.allocateDirect(BUFFERSIZE);
通过调用isDirect()方法可以查看一个缓冲区是否是直接缓冲区。由于直接缓冲区没有后援数组,在它上面调用array()或arrayOffset()方法都将抛出UnsupportedOperationException异常。在考虑是否使用直接缓冲区时需要牢记几点。首先,要知道调用allocateDirect()方法并不能保证能成功分配直接缓冲区--有的平台或JVM可能不支持这个操作,因此在尝试分配直接缓冲区后必须调用isDirect()方法进行检查。其次,要知道分配和销毁直接缓冲区通常比分配和销毁非直接缓冲区要消耗更多的系统资源,因为直接缓冲区的后援存储空间通常存在与JVM之外,对它的管理需要与操作系统进行交互。所以,只有当需要在很多I/O操作上长时间使用时,才分配直接缓冲区。实际上,在相对于非直接缓冲区能明显提高系统性能时,使用直接缓冲区是个不错的主意。
5.4.3存储和接收数据
只要有了缓冲区,就可以用它来存放数据了。作为数据的"容器",缓冲区既可用来输入也可用来输出。这一点就与流不同,流只能向一个方向传递数据。使用put()方法可以将数据放入缓冲区,使用get()方法则可以从缓冲区获取数据。信道的read()方法隐式调用了给定缓冲区的put(),而其write()方法则隐式调用了缓冲区的get()方法。下面展示ByteBuffer的get()和put()方法,当然,其他类型的缓冲区也有类似的方法。
ByteBuffer:获取和存放字节
相对位置:
byte get()
ByteBuffer get(byte[] dst)
ByteBuffer get(byte[] dst, int offset, int length)
ByteBuffer put(byte b)
ByteBuffer put(byte[] src)
ByteBuffer put(byte[] src, int offset, int length)
ByteBuffer put(ByteBuffer src)
绝对位置:
byte get(int index)
ByteBuffer put(int index, byte b)
有两种类型的get()和put():基于相对位置和基于绝对位置。基于相对位置的版本根据position的当前值,从"下一个"位置读取或存放数据,然后根据数据量给position增加适当的值(即,单字节形式增加1, 数组形式增加array.length, 数组/偏移量/长度形式则增加length)。也就是说,每次调用put()方法,都是在缓冲区中的已有元素后面追加数据,每次调用get()方法,都是读取缓冲区的后续元素。不过,如果这些操作会导致position的值超出limit的限制,get()方法将抛出BufferUnderflowException异常,put()方法将抛出BufferOverflowException异常。例如,如果传给get()方法的目标数组长度大于缓冲区的剩余空间大小,get()方法将抛出BufferUnderflowException异常,部分数据的get/put是不允许的。基于绝对位置的get()和put()以指定的索引位置为参数,从该位置读取数据或向该位置写入数据。绝对位置形式的get和put不会改变position的值。如果给定的索引值超出了limit的限制,它们将抛出IndexOutOfBoundsException异常。
除了字节类型外,ByteBuffer类还提供了其他类型数据的相当位置和绝对位置的get/put方法。这样一来,就有点像DataOutputStream了。
ByteBuffer:读取和存放Java多字节基本数据
<type> get<Type>()
<type> get<Type>(int index)
ByteBuffer put<Type>(<type> value)
ByteBuffer put<Type>(int index,<type> value)
其中"<Type>"代表Char,Double,Int,Long,Short之一,而"<type>"代表char,double,int,long,short之一。
每次调用基于相对位置的put()或get()方法,都将根据特定参数类型的长度增加position的值:short加2,int加4,等。不过,如果这样做会导致position的值超出limit的限制,get()和put()方法将分别抛出BufferUnderflowException和BufferOverflowException异常:get和put不允许只对部分数据进行操作。发生了下溢/上溢(under/overflow)时,position的值不变。
可能你已经注意到,很多get/put方法都返回一个ByteBuffer。实际上它们返回的就是调用它们的那个ByteBuffer。这样做可以实现链式调用(call chaining),即第一次调用的结果可以直接用来进行后续的方法调用。例如,可以像下面那样将整数1和2存入ByteBuffer实例 myBuffer中:myBuffer.putInt(1).putInt(2);
回顾第3章的内容我们知道,多字节数据类型有一个字节顺序,称为big-endian或little-endian。Java默认使用big-endian。通过使用内置的ByteOrder.BIG_ENDIAN和
ByteOrder.LITTLE_ENDIAN实例,可以获取和设定多字节数据类型写入字节缓冲区时的字节顺序。
ByteBuffer:缓冲区中的字节顺序
ByteOrder order()
ByteBuffer order(ByteOrder order)
第一个方法以ByteOrder常量的形式返回缓冲区的当前字节顺序。第二个方法用来设置
写多字节数据时的字节顺序。
下面来看一个使用字节顺序的例子:
ByteBuffer buffer = ByteBuffer.allocate(4);
buffer.putShort((short) 1);
buffer.order(ByteOrder.LITTLE_ENDIAN);
buffer.putShort((short) 1);
// Predict the byte values for buffer and test your
prediction
看了这些有关字节顺序的讨论,你可能希望知道自己的处理器是什么字节顺序,ByteOrder定义了一个方法来解答这个问题:
ByteOrder:查找字节顺序
static final ByteOrder BIG_ENDIAN
static final ByteOrder LITTLE_ENDIAN
static ByteOrder nativeOrder()
nativeOrder()方法返回常量BIG_ENDIAN或LITTLE_ENDIAN之一。
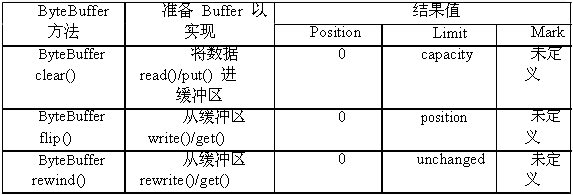
5.4.4准备 Buffer: clear(), flip(),和 rewind()
在使用缓冲区进行输入输出数据之前,必须确定缓冲区的position,limit都已经设置了正确的值。下面考虑一个容量为7的CharBuffer实例,并已经连续调用了put()或read()方法:
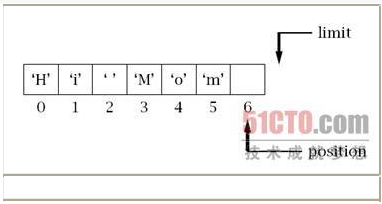
如果现在想用这个缓冲区进行信道的写操作,由于write()方法将从position指示的位置开始读取数据,在limit指示的位置停止,因此在进行写操作前,先要将limit的值设为position的当前值,再将position的值设为0。
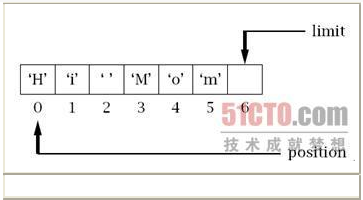
这种情况我们可以自己处理,不过,幸运的是Java已经提供了一些便利的方法来完成
这些工作,见表5.3。
注意,这些方法不会改变缓冲区中的数据,只是改变缓冲区的索引。clear()方法将position
设置为0,并将limit设置为等于capacity,从而使缓冲区准备好从缓冲区的put操作或信道
的读操作接收新的数据。
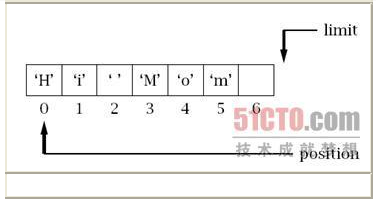
表5.3:ByteBuffer实例的方法
后续的put()/read()调用,将数据从第一个元素开始填入缓冲区,直到填满了limit所指
定的限制,其值等于capacity的值。
// Start with buffer in unknown state
buffer.clear(); // Prepare buffer for input,
ignoring existing state
channel.read(buffer); // Read new data into
buffer, starting at first element
虽然名字是clear(),但它实际上不会改变缓冲区中的数据,而只是简单地重置了缓冲区的主要索引值。考虑一个最近使用put()或read()存入了数据的缓冲区,其position值指示了不包含有效字符的第一个元素位置。
flip()方法用来将缓冲区准备为数据传出状态,这通过将limit设置为position的当前值,再将 position的值设为0来实现:
后续的get()/write()调用将从缓冲区的第一个元素开始检索数据,直到到达limit指示的位置。下面是使用flip()方法的例子:
// ... put data in buffer with put() or read() ...
buffer.flip(); // Set position to 0, limit to old position
while (buffer.hasRemaining()) // Write buffer
data from the first element up to limit
channel.write(buffer);
假设在写出缓冲区的所有数据后,你想回到缓冲区的开始位置再重写一次相同的数据(例如,想要将同样的数据发送给另一个信道)。rewind()方法将position设置为0,并使mark值无效。这很像flip()方法的操作,只是limit的值没变。这些操作什么时候会有用呢?当你想要将在网络上发送的所有数据都写入日志时就会用到:
// Start with buffer ready for writing
while (buffer.hasRemaining()) // Write all data to network
networkChannel.write(buffer);
buffer.rewind(); // Reset buffer to write again
while (buffer.hasRemaining()) // Write all data to logger
loggerChannel.write(buffer);
5.4.5压缩 Buffer中的数据
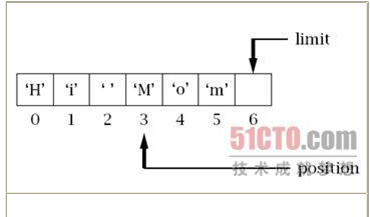
compact()方法将 position与limit之间的元素复制到缓冲区的开始位置,从而为后续的put()/read()调用让出空间。position的值将设置为要复制的数据的长度,limit的值将设置为capacity,mark则变成未定义。考虑在下面的缓冲区调用compact()前的状态:
下面是调用compact()后的状态:
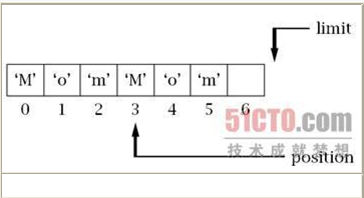
为什么要使用这个操作呢?假设你有一个缓冲区要写数据。回顾前面的内容我们知道,对write()方法的非阻塞调用只会写出其能够发送的数据,而不会阻塞等待所有数据发送完。因此write()方法不一定会将缓冲区中的所有元素都发送出去。又假设现在要调用read()方法,在缓冲区中没有发送的数据后面读入新数据。处理方法之一就是简单地设置position = limit和limit = capacity。当然,在读入新数据后,再次调用write()方法前,还需要将这些值还原。这样做有个问题即缓冲区的空间最终将消耗殆尽,如上图中,只剩下一个元素位置可以再存入一个字节。此外,缓冲区前面的空间又被浪费掉了。这就是compact()方法要解决的问题。在调用write()方法后和添加新数据的read()方法前调用compact()方法,则将所有"剩余"的数据移动到缓冲区的开头,从而为释放最大的空间来存放新数据。
// Start with buffer ready for reading
while (channel.read(buffer) != -1) {
buffer.flip();
channel.write(buffer);
buffer.compact();
}
while (buffer.hasRemaining())
channel.write(buffer);
注意,如在本章开始已经提到的,复制数据是一个非常耗费系统资源的操作,因此要保守地使用compact()方法。
5.4.6 Buffer透视: duplicate(), slice()等
NIO提供了多种方法来创建一个与给定缓冲区共享内容的新缓冲区,这些方法对元素的处理过程各有不同。基本上,这种新缓冲区有自己独立的状态变量(position,limit,capacity和mark),但与原始缓冲区共享了同一个后援存储空间。任何对新缓冲区内容的修改都将反映到原始缓冲区上。可以将新缓冲区看作是从另一个角度对同一数据的透视。表5.4列出了相关的方法。
duplicate()方法用于创建一个与原始缓冲区共享内容的新缓冲区。新缓冲区的position,
limit,mark和capacity都初始化为原始缓冲区的索引值,然而,它们的这些值是相互独立的。
表 5.4:在Buffer上创建不同透视的方法
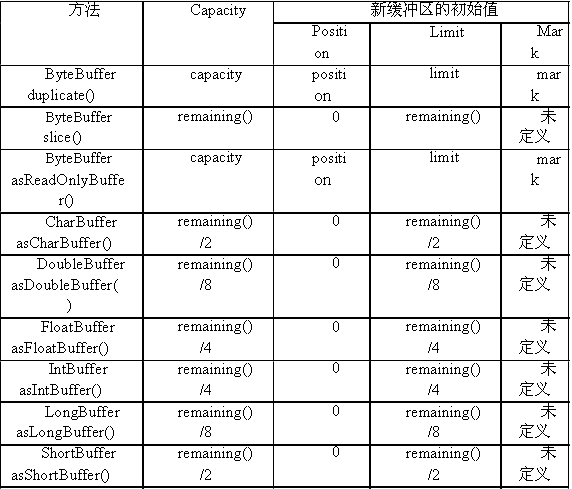
由于共享了内容,对原始缓冲区或任何复本所做的改变在所有复本上都可见。下面回到
前面的例子,假设要将在网络上发送的所有数据都写进日志。
// Start with buffer ready for writing
ByteBuffer logBuffer = buffer.duplicate();
while (buffer.hasRemaining()) // Write all data to network
networkChannel.write(buffer);
while (logBuffer.hasRemaining()) // Write all data to
logger
loggerChannel.write(buffer);
注意,使用了缓冲区复制操作,向网络写数据和写日志就可以在不同的线程中并行进行。slice()方法用于创建一个共享了原始缓冲区子序列的新缓冲区。新缓冲区的position值是0,而其limit和capacity的值都等于原始缓冲区的limit和position的差值。slice()方法将新缓冲区数组的offset值设置为原始缓冲区的position值,然而,在新缓冲区上调用array()方法还是会返回整个数组。
Channel在读写数据时只以ByteBuffer为参数,然而我们可能还对使用其他基本类型的数据进行通信感兴趣。ByteBuffer能够创建一种独立的"视图缓冲区(view buffer)",用于将ByteBuffer的内容解释成其他基本类型(如CharBuffer)。这样就可以从该缓冲区中读取(写入数据是可选操作)新类型的数据。新缓冲区与原始缓冲区共享了同一个后援存储空间,因此,在任一缓冲区上的修改在新缓冲区和原始缓冲区上都可以看到。新创建的视图缓冲区的position值为0,其内容从原始缓冲区的position所指位置开始。这与slice()操作非常相似。不过,由于视图缓冲区操作的是多字节元素,新缓冲区的capacity和limit的值等于剩余总字节数除以每个该类型元素对应的字节数(例如,创建DoubleBuffer时则除以8)。
下面来看一个例子。假设通过某个Channel接收到一条消息,该消息由一个单独字节,后跟大量big-endian顺序的双字节整数(如short型)组成。由于该消息是通过Channel送达的,它一定在一个ByteBuffer中,在此为buf。消息的第一个字节包含了消息中双字节整数的数量。你可能要调用第一个字节指定次数的buf.getShort()方法,或者你可以一次获取所有的整数,如下所示:
// ...get message by calling channel.read(buf) ...
int numShorts = (int)buf.get();
if (numShorts < 0) {
throw new SomeException()
} else {
short[] shortArray = new short[numShorts];
ShortBuffer sbuf = buf.asShortBuffer();
sbuf.get(shortArray); // note: will throw if header was
incorrect!
}
asReadOnlyBuffer()方法的功能与duplicate()方法相似,只是任何会修改新缓冲区内容的方法都将抛出ReadOnlyBufferException异常。包括各种型式的put(),compact()等,甚至连在缓冲区上调用无方向性的array()和arrayOffset()方法也会抛出这个异常。当然,对产生这个只读缓冲区的非只读缓冲区进行的任何修改,仍然会与新的只读缓冲区共享。就像用duplicate()创建的缓冲区一样,只读缓冲区也有独立的缓冲区状态变量。可以使用isReadOnly()方法来检查一个缓冲区是否是只读的。如果原缓冲区已经是只读的,调用duplicate()或slice()方法也将创建新的只读缓冲区。
5.4.7字符编码
回顾第3章介绍的内容我们知道,字符是由字节序列进行编码的,而且在字节序列与字符集合之间有各种映射(称为字符集)方式。NIO缓冲区的另一个用途是在各种字符集之间进行转换。要使用这个功能,还需要了解java.nio.charset包中另外两个类(在第3章中我们已经介绍了Charset类):CharsetEncoder和CharsetDecoder类。要进行编码,需要使用一个Charset实例来创建一个编码器并调用encode方法:
Charset charSet = Charset.forName("US-ASCII");
CharsetEncoder encoder = charSet.newEncoder();
ByteBuffer buffer = encoder.encode(CharBuffer.wrap("Hi
mom"));
要进行解码,需要使用Charset实例来创建一个解码器,并调用decode方法:
CharsetDecoder decoder = charSet.newDecoder();
CharBuffer cBuf = decoder.decode(buffer);
虽然这种方法能够正常工作,但当需要进行多次编码时,效率就会变得较低。例如,每次调用encode/decode方法都会创建一个新Byte/CharBuffer实例。其他导致低效率的地方与编码器的创建和操作有关。
encoder.reset();
if (encoder.encode(CharBuffer.wrap("Hi "),buffer,false)
== CoderResult.OVERFLOW) {
// ... deal with lack of space in buffer ...
}
if (encoder.encode(CharBuffer.wrap("Mom"),buffer,true)
== CoderResult.OVERFLOW) {
// ... ditto ...
}
encoder.flush(buffer);
encode()方法将给定CharBuffer转换为一个字节序列,并将其写入给定的缓冲区。如果缓冲区太小,encode()方法的返回值等于CoderResult.OVERFLOW。如果输入的数据完全被接收,并且编码器还准备对更多数据进行编码,encode()方法的返回值则等于CoderResult.UNDERFLOW。另外,如果输入的数据格式有错误,则将返回一个CoderResult对象,并指示了所存在的问题的位置和类型。只有到达了输入数据的结尾时,才将最后的boolean参数设为true。flush()方法将任何缓存的编码数据推送到缓冲区。注意,在新创建的编码器上调用reset()方法并不是必需的,该方法用来重新设置编码器的内部状态,以使其能够进行再次编码。
5.4.1 Buffer索引
缓冲区不仅仅是用来存放一组元素的列表。在读写数据时,它有内部状态来跟踪缓冲区的当前位置,以及有效可读数据的结束位置等。为了实现这些功能,每个缓冲区维护了指向其元素列表的4个索引,如表5.1所示。(不久我们将看到如何使用缓冲区的各种方法来修改索引值。)
表5.1:缓冲区内部状态
position和limit之间的距离指示了可读取/存入的字节数。Java中提供了两个方便的方法来计算这个距离。
ByteBuffer:剩余字节
boolean hasRemaining()
int remaining()
当缓冲区至少还有一个元素时,hasRemaining()方法返回true,remaining()方法返回剩余元素的个数。
在这些变量中,以下关系保持不变:
0 ≤ mark ≤ position ≤ limit ≤ capacity
mark变量的值"记录"了一个将来可返回的位置,reset()方法则将position的值还原成上次调用mark()方法后的position值(除非这样做会违背上述的不变关系)。
5.4.2创建 Buffer
通常使用分配空间或包装一个现有的基本类型数组来创建缓冲区。创建ByteBuffer的静态工厂方法,以及相应的capacity,position,和limit的初始值见表5.2。所有新创建的Buffer实例都没有定义其mark值,在调用mark()方法前,任何试图使用reset()方法来设置position的值的操作都将抛出InvalidMarkException异常。
要分配一个新的实例,只需要简单地调用想要创建的缓冲区类型的allocate()静态方法,并指定元素的总数:
ByteBuffer byteBuf = ByteBuffer.allocate(20);
DoubleBuffer dblBuf = DoubleBuffer.allocate(5);
表5.2:ByteBuffer 创建方法
在上面代码中,byteBuf分配了20个字节,dblBuf分配了5个Java的double型数据。这些缓冲区都是定长的,因此无法扩展或缩减它们的容量。如果发现刚创建的缓冲区容量太小,惟一的选择就是重新创建一个大小合适的缓冲区。
还可以通过调用wrap()静态方法,以一个已有的数组为参数,来创建缓冲区:
byteArray[] = new byte[BUFFERSIZE];
// ...Fill array...
ByteBuffer byteWrap = ByteBuffer.wrap(byteArray);
ByteBuffer subByteWrap = ByteBuffer.wrap(byteArray, 3,
3);
通过包装的方法创建的缓冲区保留了被包装数组内保存的数据。实际上,wrap()方法只是简单地创建了一个具有指向被包装数组的引用的缓冲区,该数组称为后援数组。对后援数组中的数据做的任何修改都将改变缓冲区中的数据,反之亦然。如果我们为wrap()方法指定了偏移量(offset)和长度(length),缓冲区将使用整个数组为后援数组,同时将position和limit的值初始化为偏移量(offset)和偏移量+长度(offset+length)。在偏移量之前和长度之后的元素依然可以通过缓冲区访问。
使用分配空间的方式来创建缓冲区其实与使用包装的方法区别不大。惟一的区别是allocate()方法创建了自己的后援数组。在缓冲区上调用array()方法即可获得后援数组的引用。通过调用arrayOffset()方法,甚至还可以获取缓冲区中第一个元素在后援数组中的偏移量。使用wrap()方法和非零偏移量参数创建的缓冲区,其数组偏移量依然是0。
到目前为止,我们实现的所有缓冲区都将数据存放在Java分配的后援数组中。通常,底层平台(操作系统)不能使用这些缓冲区进行I/O操作。操作系统必须使用自己的缓冲区来进行I/O,并将结果复制到缓冲区的后援数组中。这些复制过程可能非常耗费系统资源,尤其是在有很多读写需求的时候。Java的NIO提供了一种直接缓冲区(direct buffers)来解
决这个问题。使用直接缓冲区,Java将从平台能够直接进行I/O操作的存储空间中为缓冲区分配后援存储空间,从而省略了数据的复制过程。这种低层的、本地的I/O通常在字节层进行操作,因此只能为 ByteBuffer进行直接缓冲区分配。
ByteBuffer byteBufDirect =ByteBuffer.allocateDirect(BUFFERSIZE);
通过调用isDirect()方法可以查看一个缓冲区是否是直接缓冲区。由于直接缓冲区没有后援数组,在它上面调用array()或arrayOffset()方法都将抛出UnsupportedOperationException异常。在考虑是否使用直接缓冲区时需要牢记几点。首先,要知道调用allocateDirect()方法并不能保证能成功分配直接缓冲区--有的平台或JVM可能不支持这个操作,因此在尝试分配直接缓冲区后必须调用isDirect()方法进行检查。其次,要知道分配和销毁直接缓冲区通常比分配和销毁非直接缓冲区要消耗更多的系统资源,因为直接缓冲区的后援存储空间通常存在与JVM之外,对它的管理需要与操作系统进行交互。所以,只有当需要在很多I/O操作上长时间使用时,才分配直接缓冲区。实际上,在相对于非直接缓冲区能明显提高系统性能时,使用直接缓冲区是个不错的主意。
5.4.3存储和接收数据
只要有了缓冲区,就可以用它来存放数据了。作为数据的"容器",缓冲区既可用来输入也可用来输出。这一点就与流不同,流只能向一个方向传递数据。使用put()方法可以将数据放入缓冲区,使用get()方法则可以从缓冲区获取数据。信道的read()方法隐式调用了给定缓冲区的put(),而其write()方法则隐式调用了缓冲区的get()方法。下面展示ByteBuffer的get()和put()方法,当然,其他类型的缓冲区也有类似的方法。
ByteBuffer:获取和存放字节
相对位置:
byte get()
ByteBuffer get(byte[] dst)
ByteBuffer get(byte[] dst, int offset, int length)
ByteBuffer put(byte b)
ByteBuffer put(byte[] src)
ByteBuffer put(byte[] src, int offset, int length)
ByteBuffer put(ByteBuffer src)
绝对位置:
byte get(int index)
ByteBuffer put(int index, byte b)
有两种类型的get()和put():基于相对位置和基于绝对位置。基于相对位置的版本根据position的当前值,从"下一个"位置读取或存放数据,然后根据数据量给position增加适当的值(即,单字节形式增加1, 数组形式增加array.length, 数组/偏移量/长度形式则增加length)。也就是说,每次调用put()方法,都是在缓冲区中的已有元素后面追加数据,每次调用get()方法,都是读取缓冲区的后续元素。不过,如果这些操作会导致position的值超出limit的限制,get()方法将抛出BufferUnderflowException异常,put()方法将抛出BufferOverflowException异常。例如,如果传给get()方法的目标数组长度大于缓冲区的剩余空间大小,get()方法将抛出BufferUnderflowException异常,部分数据的get/put是不允许的。基于绝对位置的get()和put()以指定的索引位置为参数,从该位置读取数据或向该位置写入数据。绝对位置形式的get和put不会改变position的值。如果给定的索引值超出了limit的限制,它们将抛出IndexOutOfBoundsException异常。
除了字节类型外,ByteBuffer类还提供了其他类型数据的相当位置和绝对位置的get/put方法。这样一来,就有点像DataOutputStream了。
ByteBuffer:读取和存放Java多字节基本数据
<type> get<Type>()
<type> get<Type>(int index)
ByteBuffer put<Type>(<type> value)
ByteBuffer put<Type>(int index,<type> value)
其中"<Type>"代表Char,Double,Int,Long,Short之一,而"<type>"代表char,double,int,long,short之一。
每次调用基于相对位置的put()或get()方法,都将根据特定参数类型的长度增加position的值:short加2,int加4,等。不过,如果这样做会导致position的值超出limit的限制,get()和put()方法将分别抛出BufferUnderflowException和BufferOverflowException异常:get和put不允许只对部分数据进行操作。发生了下溢/上溢(under/overflow)时,position的值不变。
可能你已经注意到,很多get/put方法都返回一个ByteBuffer。实际上它们返回的就是调用它们的那个ByteBuffer。这样做可以实现链式调用(call chaining),即第一次调用的结果可以直接用来进行后续的方法调用。例如,可以像下面那样将整数1和2存入ByteBuffer实例 myBuffer中:myBuffer.putInt(1).putInt(2);
回顾第3章的内容我们知道,多字节数据类型有一个字节顺序,称为big-endian或little-endian。Java默认使用big-endian。通过使用内置的ByteOrder.BIG_ENDIAN和
ByteOrder.LITTLE_ENDIAN实例,可以获取和设定多字节数据类型写入字节缓冲区时的字节顺序。
ByteBuffer:缓冲区中的字节顺序
ByteOrder order()
ByteBuffer order(ByteOrder order)
第一个方法以ByteOrder常量的形式返回缓冲区的当前字节顺序。第二个方法用来设置
写多字节数据时的字节顺序。
下面来看一个使用字节顺序的例子:
ByteBuffer buffer = ByteBuffer.allocate(4);
buffer.putShort((short) 1);
buffer.order(ByteOrder.LITTLE_ENDIAN);
buffer.putShort((short) 1);
// Predict the byte values for buffer and test your
prediction
看了这些有关字节顺序的讨论,你可能希望知道自己的处理器是什么字节顺序,ByteOrder定义了一个方法来解答这个问题:
ByteOrder:查找字节顺序
static final ByteOrder BIG_ENDIAN
static final ByteOrder LITTLE_ENDIAN
static ByteOrder nativeOrder()
nativeOrder()方法返回常量BIG_ENDIAN或LITTLE_ENDIAN之一。
5.4.4准备 Buffer: clear(), flip(),和 rewind()
在使用缓冲区进行输入输出数据之前,必须确定缓冲区的position,limit都已经设置了正确的值。下面考虑一个容量为7的CharBuffer实例,并已经连续调用了put()或read()方法:
如果现在想用这个缓冲区进行信道的写操作,由于write()方法将从position指示的位置开始读取数据,在limit指示的位置停止,因此在进行写操作前,先要将limit的值设为position的当前值,再将position的值设为0。
这种情况我们可以自己处理,不过,幸运的是Java已经提供了一些便利的方法来完成
这些工作,见表5.3。
注意,这些方法不会改变缓冲区中的数据,只是改变缓冲区的索引。clear()方法将position
设置为0,并将limit设置为等于capacity,从而使缓冲区准备好从缓冲区的put操作或信道
的读操作接收新的数据。
表5.3:ByteBuffer实例的方法
后续的put()/read()调用,将数据从第一个元素开始填入缓冲区,直到填满了limit所指
定的限制,其值等于capacity的值。
// Start with buffer in unknown state
buffer.clear(); // Prepare buffer for input,
ignoring existing state
channel.read(buffer); // Read new data into
buffer, starting at first element
虽然名字是clear(),但它实际上不会改变缓冲区中的数据,而只是简单地重置了缓冲区的主要索引值。考虑一个最近使用put()或read()存入了数据的缓冲区,其position值指示了不包含有效字符的第一个元素位置。
flip()方法用来将缓冲区准备为数据传出状态,这通过将limit设置为position的当前值,再将 position的值设为0来实现:
后续的get()/write()调用将从缓冲区的第一个元素开始检索数据,直到到达limit指示的位置。下面是使用flip()方法的例子:
// ... put data in buffer with put() or read() ...
buffer.flip(); // Set position to 0, limit to old position
while (buffer.hasRemaining()) // Write buffer
data from the first element up to limit
channel.write(buffer);
假设在写出缓冲区的所有数据后,你想回到缓冲区的开始位置再重写一次相同的数据(例如,想要将同样的数据发送给另一个信道)。rewind()方法将position设置为0,并使mark值无效。这很像flip()方法的操作,只是limit的值没变。这些操作什么时候会有用呢?当你想要将在网络上发送的所有数据都写入日志时就会用到:
// Start with buffer ready for writing
while (buffer.hasRemaining()) // Write all data to network
networkChannel.write(buffer);
buffer.rewind(); // Reset buffer to write again
while (buffer.hasRemaining()) // Write all data to logger
loggerChannel.write(buffer);
5.4.5压缩 Buffer中的数据
compact()方法将 position与limit之间的元素复制到缓冲区的开始位置,从而为后续的put()/read()调用让出空间。position的值将设置为要复制的数据的长度,limit的值将设置为capacity,mark则变成未定义。考虑在下面的缓冲区调用compact()前的状态:
下面是调用compact()后的状态:
为什么要使用这个操作呢?假设你有一个缓冲区要写数据。回顾前面的内容我们知道,对write()方法的非阻塞调用只会写出其能够发送的数据,而不会阻塞等待所有数据发送完。因此write()方法不一定会将缓冲区中的所有元素都发送出去。又假设现在要调用read()方法,在缓冲区中没有发送的数据后面读入新数据。处理方法之一就是简单地设置position = limit和limit = capacity。当然,在读入新数据后,再次调用write()方法前,还需要将这些值还原。这样做有个问题即缓冲区的空间最终将消耗殆尽,如上图中,只剩下一个元素位置可以再存入一个字节。此外,缓冲区前面的空间又被浪费掉了。这就是compact()方法要解决的问题。在调用write()方法后和添加新数据的read()方法前调用compact()方法,则将所有"剩余"的数据移动到缓冲区的开头,从而为释放最大的空间来存放新数据。
// Start with buffer ready for reading
while (channel.read(buffer) != -1) {
buffer.flip();
channel.write(buffer);
buffer.compact();
}
while (buffer.hasRemaining())
channel.write(buffer);
注意,如在本章开始已经提到的,复制数据是一个非常耗费系统资源的操作,因此要保守地使用compact()方法。
5.4.6 Buffer透视: duplicate(), slice()等
NIO提供了多种方法来创建一个与给定缓冲区共享内容的新缓冲区,这些方法对元素的处理过程各有不同。基本上,这种新缓冲区有自己独立的状态变量(position,limit,capacity和mark),但与原始缓冲区共享了同一个后援存储空间。任何对新缓冲区内容的修改都将反映到原始缓冲区上。可以将新缓冲区看作是从另一个角度对同一数据的透视。表5.4列出了相关的方法。
duplicate()方法用于创建一个与原始缓冲区共享内容的新缓冲区。新缓冲区的position,
limit,mark和capacity都初始化为原始缓冲区的索引值,然而,它们的这些值是相互独立的。
表 5.4:在Buffer上创建不同透视的方法
由于共享了内容,对原始缓冲区或任何复本所做的改变在所有复本上都可见。下面回到
前面的例子,假设要将在网络上发送的所有数据都写进日志。
// Start with buffer ready for writing
ByteBuffer logBuffer = buffer.duplicate();
while (buffer.hasRemaining()) // Write all data to network
networkChannel.write(buffer);
while (logBuffer.hasRemaining()) // Write all data to
logger
loggerChannel.write(buffer);
注意,使用了缓冲区复制操作,向网络写数据和写日志就可以在不同的线程中并行进行。slice()方法用于创建一个共享了原始缓冲区子序列的新缓冲区。新缓冲区的position值是0,而其limit和capacity的值都等于原始缓冲区的limit和position的差值。slice()方法将新缓冲区数组的offset值设置为原始缓冲区的position值,然而,在新缓冲区上调用array()方法还是会返回整个数组。
Channel在读写数据时只以ByteBuffer为参数,然而我们可能还对使用其他基本类型的数据进行通信感兴趣。ByteBuffer能够创建一种独立的"视图缓冲区(view buffer)",用于将ByteBuffer的内容解释成其他基本类型(如CharBuffer)。这样就可以从该缓冲区中读取(写入数据是可选操作)新类型的数据。新缓冲区与原始缓冲区共享了同一个后援存储空间,因此,在任一缓冲区上的修改在新缓冲区和原始缓冲区上都可以看到。新创建的视图缓冲区的position值为0,其内容从原始缓冲区的position所指位置开始。这与slice()操作非常相似。不过,由于视图缓冲区操作的是多字节元素,新缓冲区的capacity和limit的值等于剩余总字节数除以每个该类型元素对应的字节数(例如,创建DoubleBuffer时则除以8)。
下面来看一个例子。假设通过某个Channel接收到一条消息,该消息由一个单独字节,后跟大量big-endian顺序的双字节整数(如short型)组成。由于该消息是通过Channel送达的,它一定在一个ByteBuffer中,在此为buf。消息的第一个字节包含了消息中双字节整数的数量。你可能要调用第一个字节指定次数的buf.getShort()方法,或者你可以一次获取所有的整数,如下所示:
// ...get message by calling channel.read(buf) ...
int numShorts = (int)buf.get();
if (numShorts < 0) {
throw new SomeException()
} else {
short[] shortArray = new short[numShorts];
ShortBuffer sbuf = buf.asShortBuffer();
sbuf.get(shortArray); // note: will throw if header was
incorrect!
}
asReadOnlyBuffer()方法的功能与duplicate()方法相似,只是任何会修改新缓冲区内容的方法都将抛出ReadOnlyBufferException异常。包括各种型式的put(),compact()等,甚至连在缓冲区上调用无方向性的array()和arrayOffset()方法也会抛出这个异常。当然,对产生这个只读缓冲区的非只读缓冲区进行的任何修改,仍然会与新的只读缓冲区共享。就像用duplicate()创建的缓冲区一样,只读缓冲区也有独立的缓冲区状态变量。可以使用isReadOnly()方法来检查一个缓冲区是否是只读的。如果原缓冲区已经是只读的,调用duplicate()或slice()方法也将创建新的只读缓冲区。
5.4.7字符编码
回顾第3章介绍的内容我们知道,字符是由字节序列进行编码的,而且在字节序列与字符集合之间有各种映射(称为字符集)方式。NIO缓冲区的另一个用途是在各种字符集之间进行转换。要使用这个功能,还需要了解java.nio.charset包中另外两个类(在第3章中我们已经介绍了Charset类):CharsetEncoder和CharsetDecoder类。要进行编码,需要使用一个Charset实例来创建一个编码器并调用encode方法:
Charset charSet = Charset.forName("US-ASCII");
CharsetEncoder encoder = charSet.newEncoder();
ByteBuffer buffer = encoder.encode(CharBuffer.wrap("Hi
mom"));
要进行解码,需要使用Charset实例来创建一个解码器,并调用decode方法:
CharsetDecoder decoder = charSet.newDecoder();
CharBuffer cBuf = decoder.decode(buffer);
虽然这种方法能够正常工作,但当需要进行多次编码时,效率就会变得较低。例如,每次调用encode/decode方法都会创建一个新Byte/CharBuffer实例。其他导致低效率的地方与编码器的创建和操作有关。
encoder.reset();
if (encoder.encode(CharBuffer.wrap("Hi "),buffer,false)
== CoderResult.OVERFLOW) {
// ... deal with lack of space in buffer ...
}
if (encoder.encode(CharBuffer.wrap("Mom"),buffer,true)
== CoderResult.OVERFLOW) {
// ... ditto ...
}
encoder.flush(buffer);
encode()方法将给定CharBuffer转换为一个字节序列,并将其写入给定的缓冲区。如果缓冲区太小,encode()方法的返回值等于CoderResult.OVERFLOW。如果输入的数据完全被接收,并且编码器还准备对更多数据进行编码,encode()方法的返回值则等于CoderResult.UNDERFLOW。另外,如果输入的数据格式有错误,则将返回一个CoderResult对象,并指示了所存在的问题的位置和类型。只有到达了输入数据的结尾时,才将最后的boolean参数设为true。flush()方法将任何缓存的编码数据推送到缓冲区。注意,在新创建的编码器上调用reset()方法并不是必需的,该方法用来重新设置编码器的内部状态,以使其能够进行再次编码。















 113
113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









