






前言
随着计算资源和数据规模的爆发式增长,深度学习(Deep Learning)在过去十年里成为推动人工智能突飞猛进的关键力量,从图像识别到语音识别、从自然语言处理到强化学习,深度学习无处不在。对于系统架构设计师而言,理解深度学习的根本原理、常见模型构造以及底层训练机制,不仅能帮助搭建更高效、可扩展的AI系统,也能为上层应用(如大模型)提供更扎实的基础思路。
AI深度学习与神经网络的工作本质
深度学习之所以能在计算机视觉、自然语言处理等领域取得突破,根源在于其背后的神经网络能够模拟人脑神经元的连接,通过层层抽象逐步学习数据的潜在模式;这种方法摆脱了传统机器学习中大量依赖人工特征工程的局限,让模型从数据中自主提取特征,推动了AI能力的跨越式提升,理解深度学习的工作本质,有助于我们把握这一技术的潜力与局限。
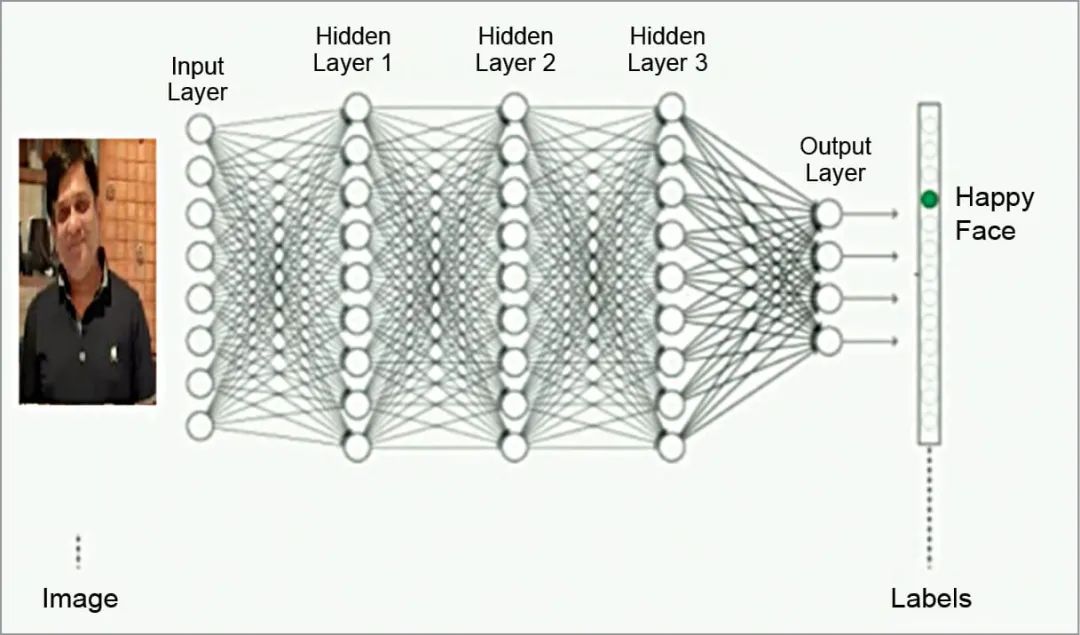
多层非线性映射
在传统机器学习时代,特征工程常由专家手动设计;而深度学习的核心在于多层神经网络能够自动学习和提炼特征,大体可将深度学习视为:

-
层数越深:网络有更高的表示能力,可以在不同层学到从低级到高级的特征;
-
非线性激活(如ReLU、Sigmoid):赋予神经网络超越线性模型的表达能力;
-
端到端学习:深度网络把特征提取与任务预测合二为一,从数据直接学到最优特征与决策方式。
从计算视角看神经网络
神经网络本质上是计算图(Computation Graph),由一系列线性变换(矩阵乘法)与非线性激活组成,通过前向传播进行输出推导,反向传播(Backpropagation)进行梯度更新。
-
前向传播:将输入按层级顺序通过权重W与激活函数f,得到输出;
-
反向传播:根据损失函数(Loss)对每个权重的梯度进行计算与更新,采用如SGD、Adam等优化算法来最小化损失。
训练过程
-
损失函数:
用于衡量网络输出与真实标签(或预期值)之间差异,如交叉熵损失、均方误差等。
模型目标是通过训练来最小化损失函数的值。
-
梯度下降:
通过计算损失函数对每个参数的偏导数,迭代式地进行权重更新;
在大型数据集上,一般用Mini-batch方式来平衡收敛速度与内存占用。
-
正则化与防过拟合:
L2正则化、Dropout、BatchNorm等手段可防止网络过度拟合训练数据,增强泛化能力;
对网络结构复杂度及训练数据多样性也需平衡,让模型既具表达力又不过度贴合噪音。
AI深度学习的主要网络类型
深度学习在实际应用中涌现了多种网络结构,每种都针对特定类型数据或任务需求作了优化设计,以下是几种经典网络,为深度学习奠定了最初的成功。
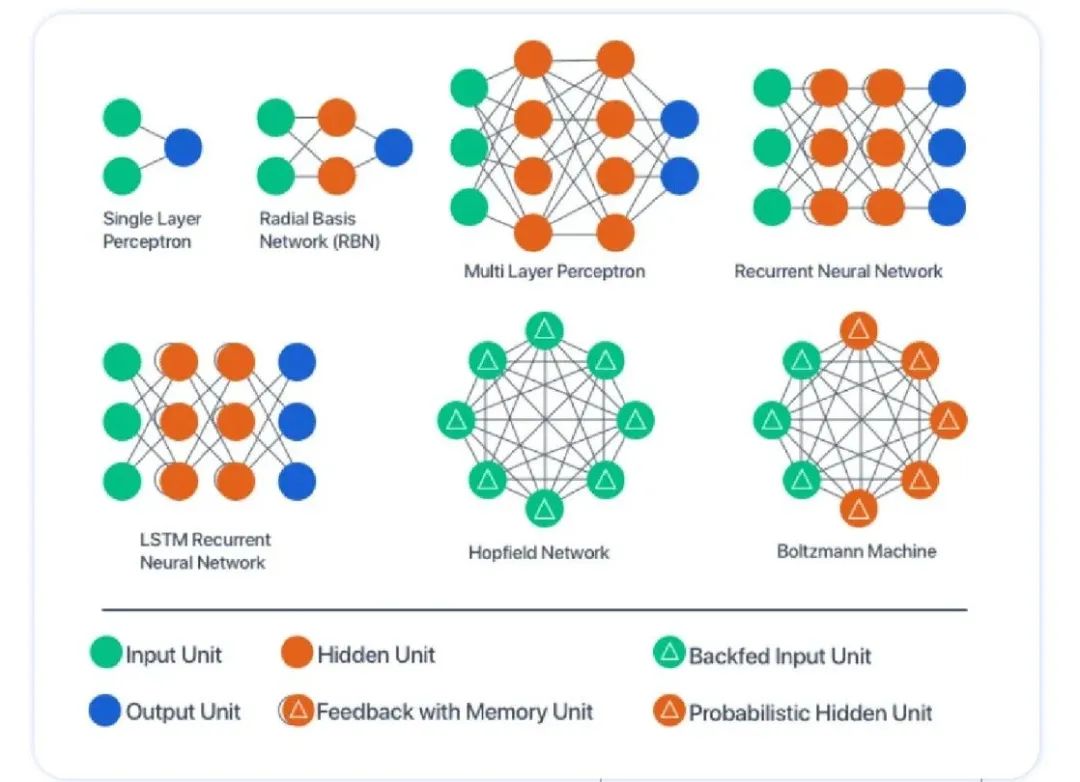
MLP(多层感知器)
多层感知器(Multi-Layer Perceptron,MLP) 是最简单的前馈网络,由若干全连接层堆叠而成:
-
结构:输入层 -> 隐藏层(1到多层)-> 输出层,每层均是全连接 + 激活函数;
-
优点:易于实现,适用于低维度或结构化数据任务,如分类、回归等;
-
缺点:对高维数据(如图像、语音)表现并不突出,需要更专门的网络(CNN、RNN等)。
在系统架构中,MLP常用于嵌入层或简单分类器的末端,如对推荐系统做特征交叉,或对上游CNN/RNN提取的特征进行最后一层决策。
CNN(卷积神经网络)
卷积神经网络(CNN)在图像处理与视频分析等领域大获成功:
-
工作原理:使用卷积核在局部感受野扫描特征,一方面减少参数量,另一方面捕捉空间或时空结构;
-
典型模型:如LeNet、AlexNet、VGG、ResNet等,伴随残差结构(ResNet)出现,极大提升网络深度与精度;
-
应用场景:图像分类、目标检测、语义分割、视频分析等。
系统架构师在部署CNN相关任务时需注意GPU占用、数据并行、批量大小等关键配置,以获得理想的训练与推理速度。
RNN(循环神经网络)、LSTM/GRU
循环神经网络(RNN)针对序列数据(语音、文本、时间序列)有天然的优越性,因为其内部状态可以捕捉时序依赖:
-
LSTM(长短期记忆)与GRU(门控循环单元)改进了传统RNN,缓解了梯度消失/爆炸问题;
-
适合处理相对短的序列,但对长序列处理仍会面临并行效率低、长程依赖困难等局限。
-
在Transformer出现前,RNN/LSTM曾是自然语言处理的主流网络结构。
在实际工程中,如果任务是简单的时间序列预测或小规模文本处理,RNN/LSTM仍是一种资源占用相对较低且易于掌握的选择;但对于大规模多语言场景,目前Transformer架构更受青睐。
AI从系统架构设计的思考
随着深度学习模型规模的不断扩大,从研究到落地,系统架构已成为影响模型性能、训练效率和工程稳定性的关键因素。无论是CNN、RNN还是Transformer模型,在实际应用中都需要考虑计算资源调度、模型版本管理以及数据预处理流程等工程问题,只有将模型算法与系统架构深度结合,才能真正实现大规模神经网络的高效训练与稳定推理。

硬件与并行化
-
多GPU/TPU集群:对于CNN或RNN等模型的训练,是否支持数据并行或混合精度等并行方式是加速效率的关键;
-
容器化与微服务:将训练与推理微服务化后,借助 Kubernetes等编排平台实现弹性扩缩容,适应动态流量。
模型管理与生命周期
-
持续集成/持续部署(CI/CD):在深度学习项目中,需要版本化神经网络权重、训练脚本等;
-
在线/离线双模式:部分应用需要离线批量推理,部分则要求实时在线推理,对系统和计算资源分配有不同要求。
数据与特征工程
无论是CNN、RNN、还是MLP,都要先保障数据质量、预处理流程和特征抽取流程的稳定性;
NLP任务中还要搭配分词或文本编码策略;CV任务中则需图像数据增强或预处理管线。
结语
深度学习之所以成为“人工智能革命的引擎”,正是因为其多层非线性网络能够在海量数据中自动学习特征,从而在图像、语音、自然语言等高维场景表现出远超传统算法的能力;通过对神经网络基本构造(前向传播、反向传播、激活函数、损失函数)、常见模型类型(MLP、CNN、RNN等)的理解,系统架构设计师能够在规划AI系统时合理选择网络结构及部署方案。
无论是作为企业内部的研发框架,还是面向云端或边缘的推理服务,深度学习的核心机制都决定了工程落地的方向,后续若要进一步探讨Transformer、GAN、多模态大模型等前沿话题,就需要在本文所介绍的基础概念与经典网络上进行更深入的延伸与演化。
最后
如果你真的想学习人工智能,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!

















 232
232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









