






python 数据分发项目
场景汇总:
公司下发了一系列csi数据,都为csv格式。每个csv文件中包括了几万行数据,一共6个csv
每一行的数据格式为:row[0]:小时
row[1]:分钟
row[2]:秒
row[3]:接收tx1的rssi
row[4]:接收tx2的rssi
row[5]:接收tx3的rssi
row[6]:接收tx4的rssi
row[7]:mcs
row[8]:接收tx1的增益gain
row[9]:接收tx2的增益gain
row[10]:接收tx3的增益gain
row[11]:接收tx4的增益gain
row[12]:从此格开始,往后数256格复数数据,每64格数据属于一个天线的子载波…
同时配给了6个txt文档,名为真值文档,每个文档中有151个数字,每个数字用/t隔开
数字的含义是表示人数,即我们的数据集是一个csi人体计数的数据。
那么我们的任务,就是把数据分开,储存。
我的计划是这样的:
一、读取该csv文件,搞清楚数据排列规则
二、按照排列规则,对应真值表,将csv文件分为6*151个文件
三、创建四个文件夹0,1,2,3,表示人数
四、将6*151个文件分发到四个文件夹中
五、通过一些处理方法,将这6*151个文件处理为npy数据格式
一、排列规则
我计算了一下csv文件的列,发现,数据时间大概为5分几秒,不足六分钟,秒数不足2秒。就是说每个csv文件需要划分为151个块。5分钟=60*5=300秒。即2s一个块,一块对应一个真值。最后超过5分钟的记作一个块,对应第151个真值。
二、文件分块
这部分我在前几期里展示过代码,但是当时并没有汇总,并且后续检查时发现代码有一些错误。所以这里重新发一次。
import csv
import os
# 你要分块的csv文件
csvpath = 'F:/CSI/CSIproject/dataset/dataset/room31_3.csv'
# 你要保存分块后的csv文件
folder_path = 'F:/CSI/CSIproject/dataset/newdatacsv/room313'
import csv
import os
# 此文件目的是将数据文件按照时间段分割,每个时间段的数据存储在一个csv文件中
# 打开csv文件
with open(csvpath, 'r') as f:
# 创建csv读取器
reader = csv.reader(f)
# 读取所有数据
data = list(reader)
# 存储分钟、秒和数据
minutes = []
seconds = []
values = []
for row in data:
minutes.append(int(row[1]))
seconds.append(float(row[2]))
values.append([str(x) if i < 9 else str(x) for i, x in enumerate(row[3:])])
# 计算时间段
time_intervals = [int((minutes[i] * 60 + seconds[i])) // 2 for i in range(len(minutes))]
# 存储数据
data_intervals = [[] for _ in range(len(set(time_intervals)))]
for i in range(len(values)):
data_intervals[time_intervals[i]].append(values[i])
# 创建文件夹
if not os.path.exists(folder_path):
os.makedirs(folder_path)
# 保存数据
for i, data_interval in enumerate(data_intervals):
if i < 150:
file_path = os.path.join(folder_path, str(i + 1) + '.csv')
print('file {} done'.format(i + 1))
else:
file_path = os.path.join(folder_path, '151.csv')
print('file {} done'.format(151))
with open(file_path, 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(data[0])
for j in range(len(data_interval)):# 150段数据 但
#if j % 2 == 0:
writer.writerow([str(x).replace('(', '').replace(')', '') for x in data_interval[j]])
print('data done')
# 这里出了问题。我在检查时发现每个文件第一行都有三个空值,因此需要减去
# 遍历文件夹中的所有csv文件
for file_name in os.listdir(folder_path):
if file_name.endswith('.csv'):
# csv文件路径
file_path = os.path.join(folder_path, file_name)
# 打开csv文件
with open(file_path, 'r') as f:
# 创建csv读取器
reader = csv.reader(f)
# 读取所有数据
data = list(reader)
# 删除第一行的前三列数据
for row in data:
del row[0:3]
break
# 将第一行的其余数据向前移动3列
#for i in range(3, len(data[0])):
# data[0][i-3] = data[0][i]
#del data[0][-3:]
# 保存处理后的数据
with open(file_path, 'w', newline='') as f:
writer = csv.writer(f)
writer.writerows(data)
分好后是这样的
文件可以自己定义名字。我是偷懒了。
三、创建文件夹
如图所示
四、将分块后的csv文件按真值表对应放入上述四个文件夹中
真值表是这样的:
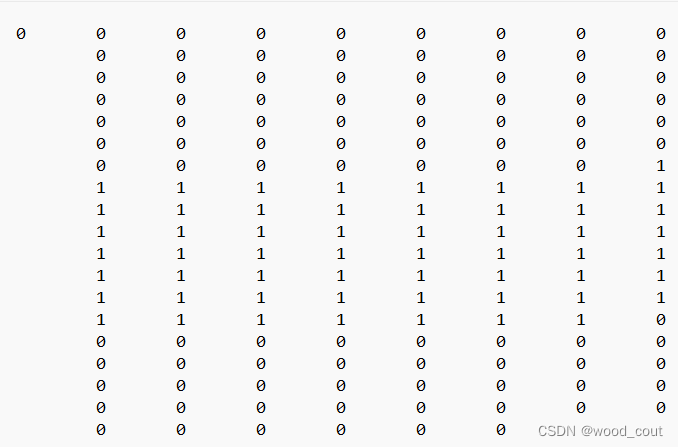
我的思想时先将真值表中的值存在一个数组中。
再将文件夹下的文件名存入一个数组中,按照索引与真值数组一一对应
代码如下:
import numpy as np
import os
from matplotlib import pyplot as plt
import shutil
# 此文件的目的是根据真值文件将数据文件分为四类,分别存储在四个文件夹中
def readtxt(path):
with open(path, 'r') as f:
data = f.read().split('\t')
data = [int(x.strip()) for x in data]
data = np.array(data)
return data
wenjianname = 'room323'
path = 'F:/CSI/CSIproject/dataset/dataset/房间3真值/真值-part2/csi_2023_09_09_22_06.txt'
folder_path = 'F:/CSI/CSIproject/dataset/newdatacsv/'+wenjianname
new_folder_path = 'F:/CSI/CSIproject/dataset/dataset/datasets/train'
data = readtxt(path)
# 遍历文件夹中的所有csv文件
for i, file_name in enumerate(os.listdir(folder_path)):
if file_name.endswith('.csv'):
# csv文件路径
file_path = os.path.join(folder_path, file_name)
# 如果data数组中对应的数为0,则将文件复制到新的路径下
if data[i] == 0:
folder_path_num = os.path.join(new_folder_path, str(data[i]))
new_file_name = wenjianname+file_name
new_file_path = os.path.join(folder_path_num, new_file_name)
shutil.copyfile(file_path, new_file_path)
elif data[i] == 1:
folder_path_num = os.path.join(new_folder_path, str(data[i]))
new_file_name = wenjianname+file_name
new_file_path = os.path.join(folder_path_num, new_file_name)
shutil.copyfile(file_path, new_file_path)
elif data[i] == 2:
folder_path_num = os.path.join(new_folder_path, str(data[i]))
new_file_name = wenjianname+file_name
new_file_path = os.path.join(folder_path_num, new_file_name)
shutil.copyfile(file_path, new_file_path)
elif data[i] == 3:
folder_path_num = os.path.join(new_folder_path, str(data[i]))
new_file_name = wenjianname+file_name
new_file_path = os.path.join(folder_path_num, new_file_name)
shutil.copyfile(file_path, new_file_path)
程序完成后是这样的:
五、把csv文件处理为npy格式
这里直接代码,不做讲解
import RSSI
import numpy as np
import pickle
import time
import os
import csv
import math
from scipy.interpolate import interp1d
from sklearn.decomposition import PCA
from scipy.signal import savgol_filter
import pywt
import os
from scipy.signal import savgol_filter
from scipy.signal import savgol_filter, butter, filtfilt, stft
from sklearn.model_selection import train_test_split
'''
@author:韩明辰 2023/9/16
@function:从CSI数据文件中读取数据,转换为相应矩阵,并写入文件夹中
'''
def dbinv(x):
return math.pow(10, x / 10)
def db(X):
R = 1
X = math.pow(abs(X), 2) / R
return (10 * math.log10(X) + 300) - 300
def RSSI_dealwith(rw1,rw2,rw3,rw4,db1,db2,db3,db4):
'''RSSI处理函数'''
rssi_mag = 0
if rw1 != 0:
rssi_mag = rssi_mag + dbinv(rw1)
if rw2 != 0:
rssi_mag = rssi_mag + dbinv(rw2)
if rw3 != 0:
rssi_mag = rssi_mag + dbinv(rw3)
if rw4 != 0:
rssi_mag = rssi_mag + dbinv(rw4)
agc = 10 * math.log10((db1**2 + db2**2 + db3**2 + db4**2)/4)-44
return db(rssi_mag) - agc
def matrix_create(file_path,file_names,folder_path_1):
'''# 从CSI数据文件中读取数据
@input:file_path:CSI数据文件路径
@output:file_names:文件名
@output:folder_path_1:CSI矩阵保存路径'''
noise_db = -92
for file_name in file_names:#检查整个目录
file_path2 = os.path.join(file_path, file_name)
if file_name.endswith('.csv'):#发现csv文件
npy_filename = file_name.replace('.csv', '.npy')
# csv文件路径
folder_path_2 = os.path.join(folder_path_1, npy_filename)
# 打开csv文件
with open(file_path2, 'r') as f:
# 创建csv读取器
reader = csv.reader(f)
# 读取所有数据
data = list(reader)
lists = []
for row in data:# 按行处理
# 处理rssi
rssi = RSSI_dealwith(float(row[0]),float(row[1]),float(row[2]),float(row[3]),float(row[5]),float(row[6]),float(row[7]),float(row[8]))
rssi_pwr = dbinv(rssi)
## 处理csi矩阵
csi = np.zeros((64,4,1),dtype=np.complex128)
kk = 0
for i in range(9, len(row), 64):
k = 0
for j in range(i,i+64):
csi[k][kk][0] = complex(row[j])#一行的子载波数据
k+=1
kk+=1
csi_sq = np.multiply(csi, np.conj(csi)).real
csi_pwr = np.sum(csi_sq, axis=0)
csi_pwr = csi_pwr.reshape(1, csi_pwr.shape[0], -1)
scale = rssi_pwr / (csi_pwr / 30)
thermal_noise_pwr = dbinv(noise_db)
quant_error_pwr = scale * (4*1)
total_noise_pwr = thermal_noise_pwr + quant_error_pwr
ret = csi * np.sqrt(scale / total_noise_pwr)
ret = ret * math.sqrt(dbinv(8))
row_data = []
for j in range(len(ret)):
row_data.append(ret[j][0])
row_data.append(ret[j][1])
row_data.append(ret[j][2])
row_data.append(ret[j][3])
lists.append(row_data)
matrix = np.array(lists)
np.save(folder_path_2, matrix)
print(matrix.shape)
调用
folder_path = 'F:/CSI/CSIproject/dataset/dataset/datasets/train/3'
folder_path_1 = 'F:/CSI/CSIproject/dataset/dataset/datasets/test/3'
# 创建空列表
file_names = []
# 遍历文件夹中的所有csv文件
for file_name in os.listdir(folder_path):
if file_name.endswith('.csv'):
# 将文件名添加到列表中
file_names.append(file_name)
matrix_create(folder_path,file_names,folder_path_1)
这样,数据处理的批处理就做好了。后续可以用数据集来做滤波等处理了。















 687
687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









