







禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者!
文章目录
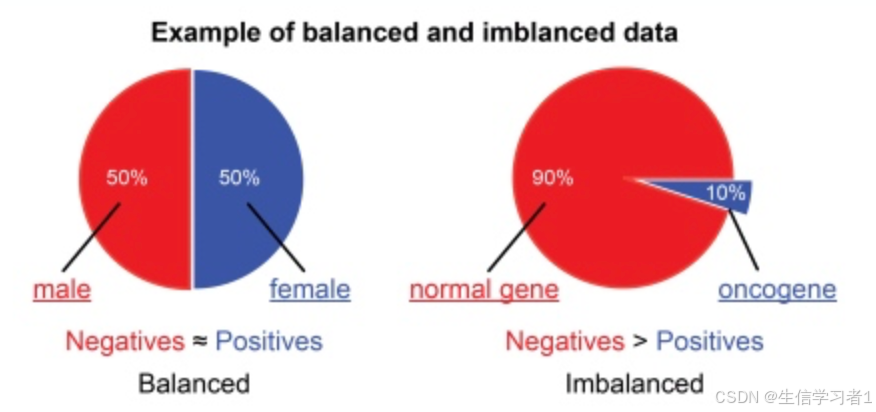
介绍
数据不平衡(Class Imbalance)是指在分类问题中,不同类别的样本数量存在显著差异的现象。例如,在一个二分类问题中,正类样本数量远多于负类样本,或者反之。这种不平衡现象在许多实际应用场景中非常常见,如医疗诊断(疾病患者与健康人群的比例)、金融欺诈检测(欺诈交易与正常交易的比例)等。
数据不平衡对模型性能的影响
在应用机器学习算法构建分类器时,数据不平衡会对模型的性能产生较大影响,主要原因如下:
-
模型偏向多数类:数据不平衡时,多数类样本数量远多于少数类样本。大多数机器学习算法在训练过程中会假设数据是均匀分布的,因此模型会倾向于预测多数类,以获得更高的整体准确率。例如,在一个二分类问题中,如果多数类占 90%,即使模型将所有样本都预测为多数类,其准确率也

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











