目录
循环神经网络与NLP
序列模型
文本处理与词嵌入
RNN模型
RNN误差反传
深度神经网络展望
生成对抗网络
神经辐射场(NeRF)
Transformer
语言-图像模型
分类问题与预测问题
图像分类
:当前输入
−>
当前输出
时间序列预测
:当前
+
过去输入
−>
当前输出
自回归模型
假设一个交易员想在当日的股市中表现良好,于是通过以下途径
预测 :
:
随着观测,时间序列越来越长,过去太久的数据不必要,因此:
保留一些对过去观测的总结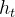 , 并且同时更新预测。
, 并且同时更新预测。
这就产生了基于
估计
,以及
更新的模型。
文本预处理
一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。 我们将
解析文本的常见预处理步骤。 这些步骤通常包括:
1.将文本作为字符串加载到内存中。
2.将字符串切分为词元(如单词和字符)。
3.建立一个字典,将拆分的词元映射到数字索引。
4.将文本转换为数字索引序列,方便模型操作
第一步:读取数据集
第二步:词汇切分
第三步:构建词索引表
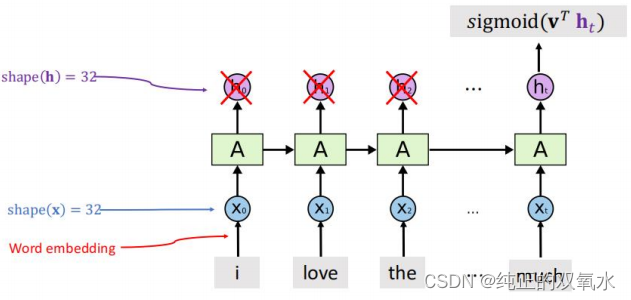
词嵌入(
word embedding)
将独热向量映射为低维向量
原始向量:
𝑣
维;映射后:
𝑑
维,
𝑑 ≪ 𝑣
;
映射矩阵:
𝑑 × 𝑣
,
根据训练数据学习得到
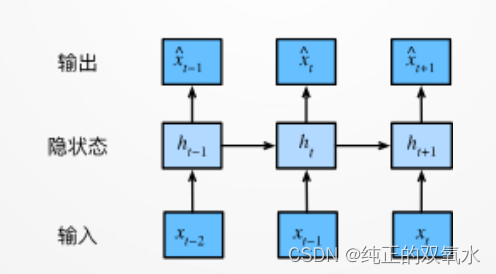
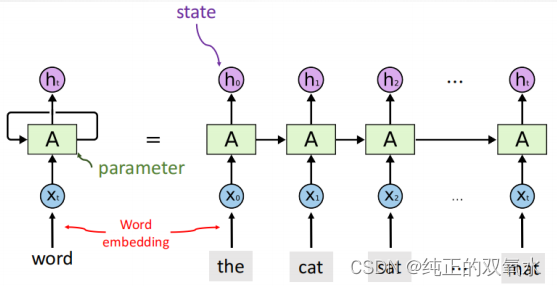
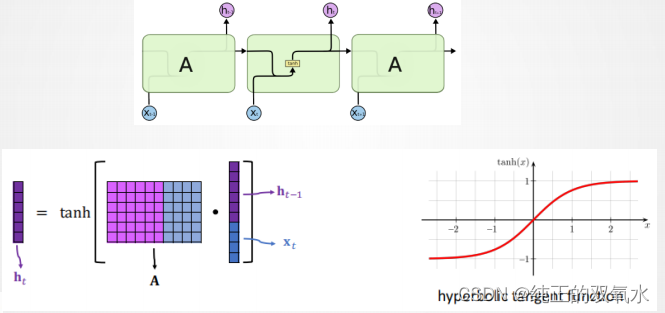
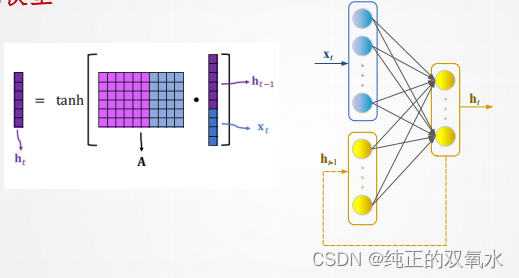
用
RNN
建模序列数据
生成对抗网络(GANs, generative adversarial networks)是由Ian Goodfellow等 人在2014年的Generative Adversarial Networks一文中提出。
模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别 模型(Discriminative Model)的互相博弈学习产生相当好的输出。 原始 GAN 理论中,并不要求 G 和 D 都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实用中一般均使用深度神经网络作为 G 和 D 。一个优秀的GAN应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
生成对抗网络其整体结构如下:
生成对抗网络(GAN)的初始原理十分容易理解,即构造两个神经网络,一个生成器,一个鉴别器,二者互相竞争训练,最后达到一种平衡(纳什平衡)。
GAN 启发自博弈论中的二人零和博弈(two-player game),GAN 模型中
的两位博弈方分别由生成式模型(generativemodel,G)和判别式模型(
discriminative model,D)充当。
生成模型 G 捕捉样本数据的分布,用服从某一分布(均匀分布,高斯
分布等)的噪声 z 生成一个类似真实训练数据的样本,追求效果是越
像真实样本越好。
判别模型 D 是一个二分类器,估计一个样本来自于训练数据(而非生
成数据)的概率,如果样本来自于真实的训练数据,D 输出大概率,
否则,D 输出小概率。
NeRF(Neural Radiance Fields)最早在2020年ECCV会议上发表,作为Best Paper,其将隐式表达推上了一个新的高度,仅用 2D 的 posed images 作为监督,即可表示复杂的三维场景。NeRF迅速发展起来,被应用到多个技术方向上,例如新视点合成、三维重建等等,并取得非常好的效果。
NeRF其输入稀疏的多角度带pose的图像训练得到一个神经辐射场模型,根据这个模型可以渲染出任意视角下的清晰的照片,也可以简要概括为用一个MLP神经网络去隐式地学习一个三维场景。
将
Transformer
模型看成是一个黑箱操作。
在机器翻译中,就是输入一种语言,输出另一种语言。
由编码组件、解码组件和它们之间的连接组成。
编码组件部分由
6
个编码器(
encoder
)叠在一起构成。解码组件部
分也是由相同数量的解码器(
decoder
)组成的。
从编码器输入的句子首先会经过一个自注意力(
self-attention
)层
,这层帮助编码器在对每个单词编码时关注输入句子的其他单词。
自注意力层的输出会传递到前馈神经网络中。每个位置的单词对应
的前馈神经网络都完全一样。
解码器中也有编码器的自注意力层和前馈层。除此之外,这两个层之
间还有一个注意力层,用来关注输入句子的相关部分。
词嵌入
在
NLP
中,将每个输入单词通过词嵌入算法转换为词向量。
每个单词都被嵌入为
512
维的向量,我们使用方框格子来表示这些
向量。
Part
2
2.2 编码
13
编码
编码器接收向量列表作为输入,接着将向量列表中的向量传递到自注意
力层进行处理,然后传递到前馈神经网络层中,将输出结果传递到下一
个编码器中。
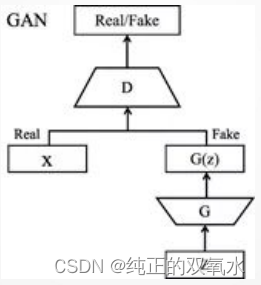
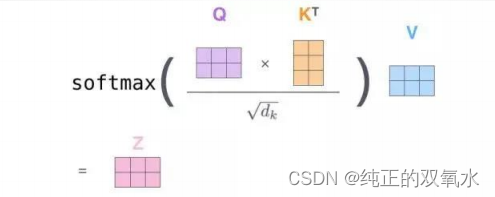
查询、键与值向量
计算自注意力的
第一步
就是从每个编码器的输入向量(每个单词的词向量)中生成三个向量。也就是说对于每个单词,我们创造一个查询向量、一个键向量 和一个值向量。这三个向量是通过词嵌入与三个权重矩阵后相乘创建的。
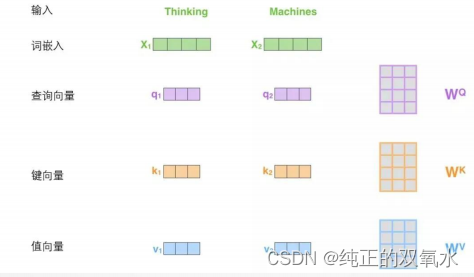
Part 3 3.1 如何使用向量
计算自注意力的
第二步
是计算得分。为这个例子中的第一个词“
Thinking”
计算自注意力向量,需要拿输入句子中的每个单词对“Thinking”
打分。这些分数决定了在编码单词“Thinking”
的过程中有多重视句子的其它部分。
使用向量计算注意力
第三步和第四步
是将分数除以
8(8
是论文中使用的键向量的维数
64
的平方根,这会让梯度更稳定。这里也可以使用其它值,8
只是默认值
)
,然后通过
softmax
传递结果,使得到的分数都是正值且和为1
。
第五步
是将每个值向量乘以
softmax
分数
(
为了准备之后求和
)
。这里的直觉是希望关注语义上相关的单词,并弱化不相关的单词(
例如,让它们乘以
0.001
这样的小数)
。
第六步
是对加权值向量求和然后即得到自注意力层在该位置的输出
(
在我们的例子中是对于第一个单词)
。
总结:
所有步骤合并为以下公式:
定义
大语言模型 (简写是LLM) 是基于海量文本数据训练的深度学习模型。它不仅能够生成自然语言文本,还能够深入理解文本含义,处理各种自然语言任务,如文本摘要、问答、翻译等。
大模型是如何进行训练的
阶段一:无监督学习给模型海量的学习资料让模型自学,让它掌握语言的表达规律.
无监督预训练技术分为两个阶段,分别是语言模型预训练和掩码语言模型预训练。语言模型预训练的目标是预测下一个单词的概率,掩码语言模型预训练的目标是根据输入的部分文本预测掩码位置上的单词。
阶段二:有监督学习
让模型学习人类整理好的规范问答,让它掌握如何回答一个问题.
微调技术是ChatGPT实现对话生成的关键技术之一,它可以通过在 有标注数据上进行有监督训练(人为问题回答),从而使模型适应 特定任务和场景。微调技术通常采用基于梯度下降的优化算法,不 断地调整模型的权重和偏置,以最小化损失函数,从而提高模型表现能力。
阶段三:强化学习
不断给模型反馈同一问题的不同回答的好坏排序来不断优化模型的问答水平
一个奖励模型(RM)的目标是刻画 模型的输出是否在人类看来表现不 错。即,输入 [提示(prompt),模 型生成的文本] ,输出一个刻画文本质量的标量数字。 用于训练奖励模型的Prompt数据一般来自于一个预先富集的数据集,比如Anthropic的Prompt数据主要 来自Amazon Mechanical Turk上面的一个聊天工具;OpenAI的Prompt 数据则主要来自那些调用GPT API 的用户。
“
基于前面提到的预先富集的数据,从里面采样prompt输入,同时丢给 初始的语言模型和我们当前训练中的语言模型(policy),得到俩模型的输出文本y1,y2。然后用奖励模型RM对y1、y2打分,判断谁更优秀。打分的差值便可以作为训练策略模型参数的信号。有了这个reward,可以使用PPO)算法更新模型参数。
























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









