






目录
-
深度学习视觉应用
-
数据集与评价指标
-
算法评估相关概念
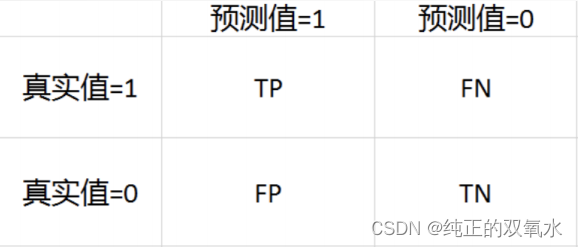
TP: 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数
FP: 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数
FN:被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数
TN: 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数
混淆矩阵:
P(精确率):
𝑇𝑃/(𝑇𝑃 + 𝐹𝑃)
,
标识“挑剔”的程度
R(召回率):
𝑇𝑃/(𝑇𝑃 + 𝐹𝑁)
。召回率越高,准确度越低
标识“通过”的程度
精度(Accuracy):
(𝑇𝑃 + 𝑇𝑁)/(𝑇𝑃 + 𝐹𝑃 + 𝑇𝑁 + 𝐹𝑁)
P-R
曲线
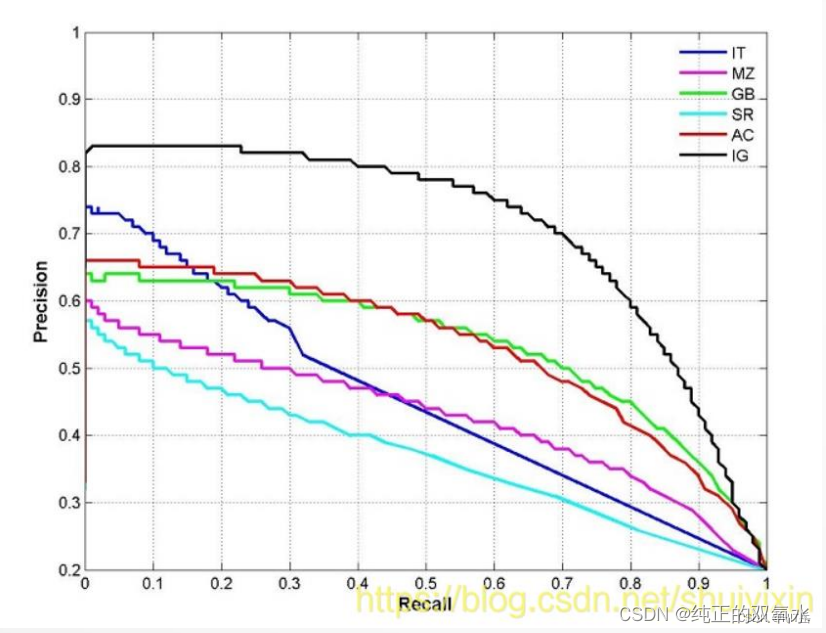
P-R的关系曲线图,表示了召回率和准确率之间的关系
精度(准确率)越高,召回率越低
置信度与准确率
调整阈值可改变准确率或召回值。
可以通过改变阈值,来选择让系统识别能出多少个图片,当然阈值的变化会导致Precision与Recall值发生变化。
P-R
曲线
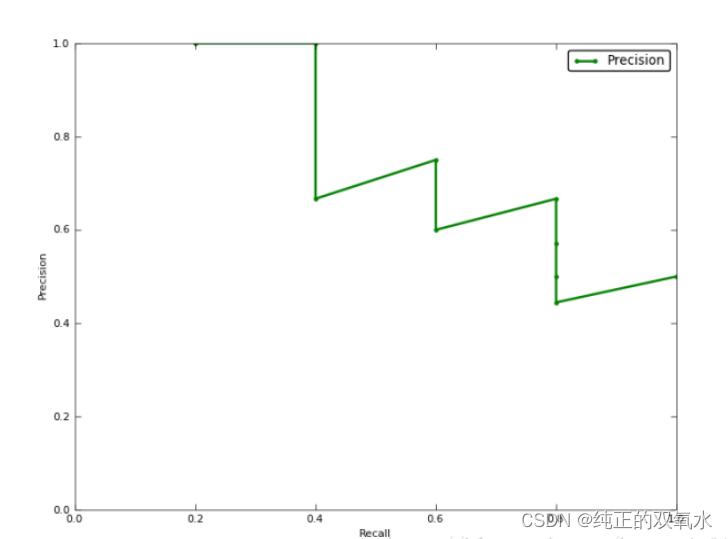
AP
计算
mAP
:均值平均准确率
其中
𝑁
代表测试集中所有图片的个数,
𝑃(𝑘)
表示在能识别出
𝑘
个图片的时候Precision的值,而 Δ𝑟(𝑘)
则表示识别图片个数从
𝑘 − 1
变化到
𝑘
时(通过调整阈 值)Recall值的变化情况。
-
目标检测与YOLO
目标检测问题
目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方,并且物体还可以是多个类别。
YOLO
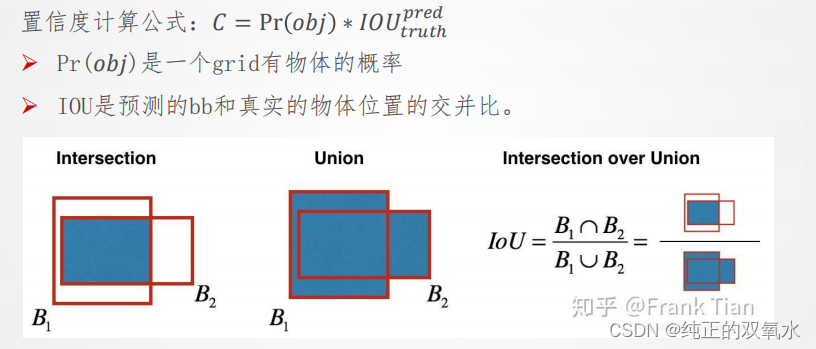
Yolo将特征图划分为S×S的格子(grid cells),每个格子负责对落入其中的目标进行检测,一次性预测所有各自所含目标的边界框、定位置信度、以及所有类别概率向量。
经过卷积网络在特征图上划分S×S的网格,通过网格的划分得到边界框(bounding box)和置信度得分(confidence)以及类别的概率图(class probability map),结合两者得到最终检测结果
从图像的特征图出发,得到物体检测出的属性(attributes),即边界框的坐标(box co-ordinates)、目标性得分(objectness score)、分类的得分。
-
损失函数
YOLO
损失函数


𝝀
取值

-
训练与NMS
NMS
算法要点
1.
首先丢弃概率小于预定IOU阈值(例如0.5)的所有边界框;对于剩余的边界框:
2.
选择具有最高概率的边界框并将其作为输出预测;
3.
计算 “作为输出预测的边界框”,与其他边界框的相关联IoU值;舍去IoU大于阈值的边界框;其实就是舍弃与“作为输出预测的边界框” 很相近的框框。
4.
重复步骤2,直到所有边界框都被视为输出预测或被舍弃
-
语义分割与FCN
语义分割问题
语义分割:找到同一画面中的不同类型目标区域
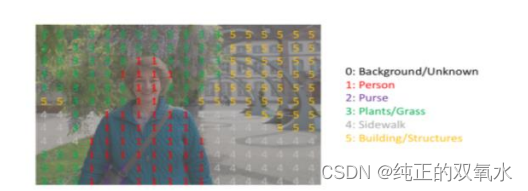
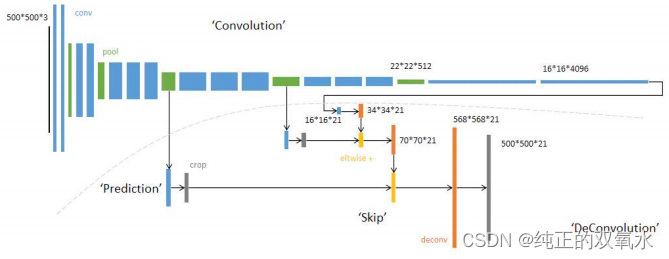
网络结构分为两个部分:全卷积部分和反卷积部分。全卷积部分借用了一些经典的CNN网络,并把最后的全连接层换成卷积,用于提取特征,形成热点图;反卷积部分则是将小尺寸的热点图上采样得到原尺寸的语义分割图像。















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









