






一、 线性分类与感知机
-
线性回归
1、定义:利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法
2、线性回归要素:训练集、输出数据、模型、训练数据的数目
3、学习过程如下所示:

4、问题解决:
假设原有问题和n个因素有关,令
则有:
假设给定样本,
构造代价(误差、损失)函数:
求解:令,即可得到:
-
线性二分类问题
1、定义:线性分类器则透过特征的线性组合来做出分类决定,以达到此种目的。
2、线性分类器输入:特征向量
输出:若为二分类问题,则为0和1,或者是属于某类的概率,即0-1之间的数。
3、线性分类与线性回归的区别主要有:
(1)输出意义不同:前者属于某类的概率,后者回归具体值
(2)参数意义不同:前者最佳分类直线,后者最佳拟合直线
(3)维度不同:前者是二维的分类,而后者算是一维的回归
对于构造这条二分类的“分界直线”,考虑代入直线方程的值,因为我们最终需要概率,结果在0-1之间,需要对值做一个变换,因此,引入Sigmoid函数:,其中
,其大致形状如下所示:

性质:𝑦′ = 𝑦(1 − 𝑦)
-
对数回归与多分类回归
二分类问题可使用条件概率描述:
因为是二分类,可假设输出为{0,1}。
-
神经元模型
Spiking模型、Integrate-and-fire模型、M-P模型 、单神经元模型
-
感知机模型
感知机从输入到输出的模型如下:
其中sign为符号函数。可表示为下图:

二、 多层前馈网络与误差反传算法
-
多层感知机
1、在输入和输出层间加一或多层隐单元,构成多层感知器(多层 前馈神经网络)。
2、加一层隐节点(单元)为三层网络,可解决异或(XOR)问题
由输入得到两个隐节点、一个输出层节点的输出:

可得到

多层感知器网络,有如下定理:
定理1
若隐层节点(单元)可任意设置,用三层阈值节点的网络,可以实现任意的二值逻辑函数。
定理2
若隐层节点(单元)可任意设置,用三层S型非线性特性节点的网络,可以一致逼近紧集上的连续函数或按范数逼近紧集上的平方可积函数。
-
BP算法
1、BP
学习算法由正向传播和反向传播组成:
①
正向传播是输入信号从输入层经隐层,传向输出层,若输出层得到了期望的输出,则学习算法结束;否则,转至反向传播。
②
反向传播是将误差
(
样本输出与网络输出之差)按原联接通路反向计算,由梯度下降法调整各层节点的权值和阈值,使误差减小。
2、BP算法的基本思想是梯度下降算法,计算过程如下:
①设置初始权系数
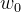 为较小的随机非零值;
为较小的随机非零值;
②给定输入/输出样本对,计算网络输出,完成前向传播;
③计算目标函数
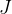 。如果
。如果
 ,训练成功并退出;否则转入④;
,训练成功并退出;否则转入④;
④反向传播计算。由输出层按梯度下降法将误差反向传播,逐层调整权值。
3、假设网络共有L层,其中输入层为第0层,输出层位第L层。记:
①网络中第i层输出:
![a^{[i]}=f(z^{[i]})](https://latex.csdn.net/eq?a%5E%7B%5Bi%5D%7D%3Df%28z%5E%7B%5Bi%5D%7D%29) ,其中
,其中
![z^{[i]}](https://latex.csdn.net/eq?z%5E%7B%5Bi%5D%7D) 为该层的线性输出;
为该层的线性输出;
②第i层第j个节点线性输出:
![z_j^{[i]}=\sum_kw_{jk}^{[i]}a_{k}^{i-1}](https://latex.csdn.net/eq?z_j%5E%7B%5Bi%5D%7D%3D%5Csum_kw_%7Bjk%7D%5E%7B%5Bi%5D%7Da_%7Bk%7D%5E%7Bi-1%7D) ,其中
,其中
![w_{jk}^{[i]}](https://latex.csdn.net/eq?w_%7Bjk%7D%5E%7B%5Bi%5D%7D) 为连接第i层第j个节点和第k个节点的权值;
为连接第i层第j个节点和第k个节点的权值;
③网络中第i层线性输出:
![z^{[i]}=W^{[i]}a^{[i-1]}](https://latex.csdn.net/eq?z%5E%7B%5Bi%5D%7D%3DW%5E%7B%5Bi%5D%7Da%5E%7B%5Bi-1%5D%7D) ,其中W为全矩阵,列数为上层神经元数目,行数为本层神经元数目;
,其中W为全矩阵,列数为上层神经元数目,行数为本层神经元数目;
④算法输入输出样本对:
 ,共N个样本。
,共N个样本。
4、考虑含一层隐含层的二层神经网络,对于第i层第j个神经元,其输出为:
其中,f可选取Log Sigmoid 函数
 。接着需要计算
。接着需要计算
 。
。

①初始化:
 ;
;
②如果
,则
![\delta_j^{[i]}=a_j(1-a_j)e_j](https://latex.csdn.net/eq?%5Cdelta_j%5E%7B%5Bi%5D%7D%3Da_j%281-a_j%29e_j) ;否则,
;否则,
![\delta_j^{[i]}=[\sum_{k=1}^m w_{kj}^{[i+1]}\delta_k^{[i+1]}]a_j^{[i]}](https://latex.csdn.net/eq?%5Cdelta_j%5E%7B%5Bi%5D%7D%3D%5B%5Csum_%7Bk%3D1%7D%5Em%20w_%7Bkj%7D%5E%7B%5Bi+1%5D%7D%5Cdelta_k%5E%7B%5Bi+1%5D%7D%5Da_j%5E%7B%5Bi%5D%7D) .
.
③权值更新:
④如果,则
,返回步骤2,进行前一层更新。对应输入层:
。















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









