






利用paddleocr字符识别模块,做字符检测,以下是paddleocr提供的示例代码:
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')这段代码运用paddle内置的权重,对示例图片进行检测,显示结果为原图和生成图片的拼接,图例如下:

在原图上,对检测字符加上选中框,在生成图片上排练打印出检测得到字符以及置信度。
但由于项目应用时,GUI界面显示有限,会对拼接图片压缩,以至于看不出识别信息,所以想把输出改一下,不要原图,只要检测输出字符。

代码改动如下:
from pathlib import Path
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
# os.environ["OMP_NUM_THREADS"] = 1
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
"""改进图片显示,不显示原图,只显示检测字符"""
file = Path(__file__).resolve()
root = file.parents[1]
def ximing_ocr():
image_folder_path = os.path.join(root, 'sm', 'data_image')
# save_path=os.path.join(root, 'sm', 'result')
for file in os.listdir(image_folder_path):
if file.endswith((".jpg", ".jpeg", ".png", "bmp")):
image_path = os.path.join(image_folder_path, file)
print(image_path)
# 读取图像大小
image = Image.open(image_path)
Width, Height = image.size
blank_image = Image.new('RGB', (20, Height), color='white')
# img = image_path[]
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
result = ocr.ocr(image_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
global txts
# 显示结果
# 如果本地没有simfang.ttf,可以在doc/fonts目录下下载
result = result[0]
image = blank_image
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
return txts
ximing_ocr()用image.new生成一块新的画布,颜色设置为白色,宽度为20(可根据个人喜好),代替原图位置与后续生成的字符画布拼接,结果如下:


此时,字符信息可以清晰看出。
但是忽觉太丑,为什么不利用一些工具,去做一做美化显示呢!
优化一:改进图片显示,在原图上显示框,和字符

代码实例:
def ximing_ocr():
global txt
image_folder_path = os.path.join(root, 'sm', 'data_image')
save_path = os.path.join(root, 'sm', 'result')
for file in os.listdir(image_folder_path):
if file.endswith((".jpg", ".jpeg", ".png", "bmp")):
image_path = os.path.join(image_folder_path, file)
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
result = ocr.ocr(image_path, cls=True)
# Load the image
image = Image.open(image_path).convert('RGB')
draw = ImageDraw.Draw(image)
for idx in range(len(result)):
res = result[idx]
for line in res:
# Extract information
box, (txt, score) = line[0], line[1]
# Draw bounding box
box = [tuple(point) for point in box]
draw.polygon(box, outline=(0, 255, 0), width=10)
# Draw text and score
font = ImageFont.truetype("./Gidole-Regular.ttf", size=200) # You can use other fonts if needed
draw.text((50, 50), f"{txt} ({score:.2f})", fill=(0, 255, 0), font=font)
# print(txt)
# print(score)
# Save the image with annotations
save_path = os.path.join(save_path, f"annotated_result.jpg")
image.save(save_path)加入一个for循环嵌套用于取用字符信息, box框固定值为10,字符显示大小固定值200
ImageFont有一个要提的点,若是用默认字符,不可更改大小,这里用了truetype字符显示
找到.ttf结尾的即为字体包,放到项目文件夹下,引用路径即可使用。
如果这里使用,图片像素值还不错,那么应该不会有啥大问题,若是比较低(低于400像素),就会:
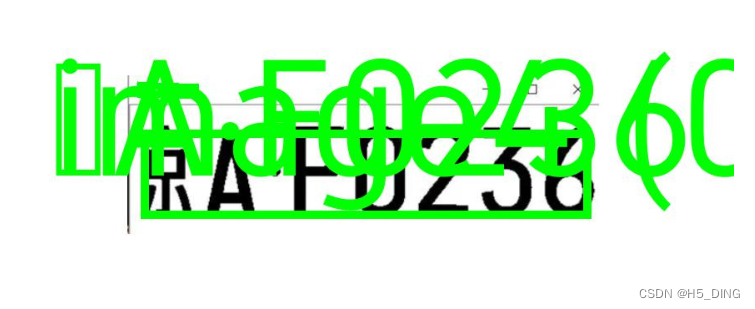
哈哈哈,固定字符值显然不能兼容不同大小图片。
优化二:改进字符显示兼容性问题,字符大小根据图片长宽显示
代码:
"""改进字符显示兼容性问题,字符大小根据图片长宽显示"""
def ximing_ocr():
global txt
image_folder_path = os.path.join(root, 'sm', 'data_image')
save_path = os.path.join(root, 'sm', 'result')
for file in os.listdir(image_folder_path):
if file.endswith((".jpg", ".jpeg", ".png", "bmp")):
image_path = os.path.join(image_folder_path, file)
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
result = ocr.ocr(image_path, cls=True)
# Load the image
image = Image.open(image_path).convert('RGB')
draw = ImageDraw.Draw(image)
# Calculate font size based on image size
image_width, image_height = image.size
font_size = int(min(image_width, image_height) * 0.10)
font = ImageFont.truetype("./Gidole-Regular.ttf", size=font_size)
for idx in range(len(result)):
res = result[idx]
for line in res:
# Extract information
box, (txt, score) = line[0], line[1]
# Draw bounding box
box = [tuple(point) for point in box]
draw.polygon(box, outline=(0, 255, 0), width=10)
# # Draw text and score
# font = ImageFont.truetype("./Gidole-Regular.ttf", size=20) # You can use other fonts if needed
draw.text((50, 50), f"{txt} ({score:.2f})", fill=(0, 255, 0), font=font)
# print(txt)
# print(score)
# Save the image with annotations
save_path = os.path.join(save_path, f"annotated_result.jpg")
image.save(save_path)
效果:

文字检测,可能是受字体包的影响。
加入优化:"""改进框宽度自适应显示"""
"""改进字符显示兼容性问题,多字符识别时显示字符往下兼容"""
"""改进单个图片检测问题,可以兼容检测整个文件夹"""

















 977
977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









