







DOM解析具体介绍:
JAXP 开发 进行 xml解析 :
javax.xml.parsers 存放 DOM 和 SAX 解析器
javax.xml.stream 存放 STAX 解析相关类
org.w3c.dom 存放DOM解析时 数据节点类
org.xml.sax 存放SAX解析相关工具类
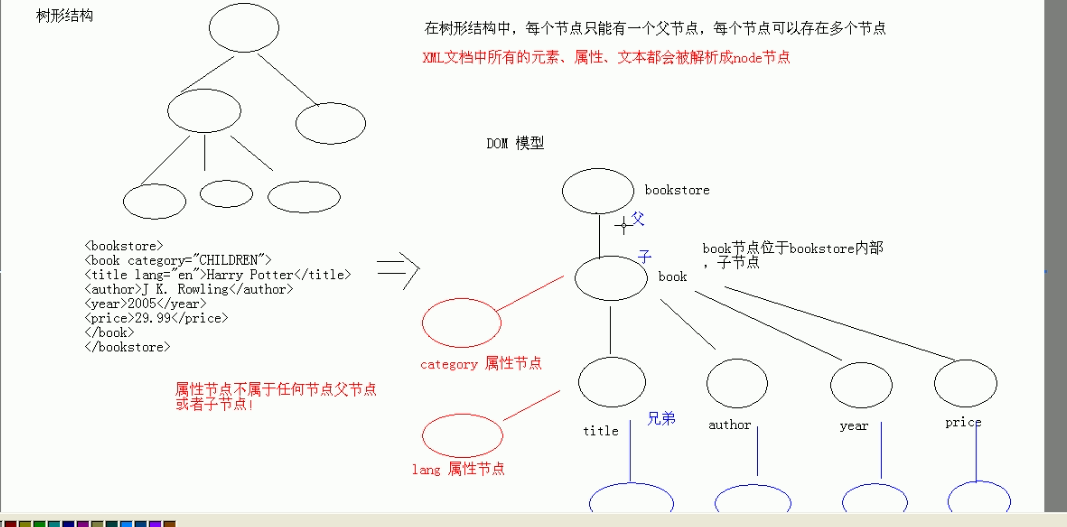
DOM 解析快速入门
1、创建 xml 文档 books.xml
在企业实际开发中,为了简化xml 生成和解析 ---- xml 数据文件通常不使用约束的
2、使用DOM解析xml
将整个xml文档加载到内存中 : 工厂 --- 解析器 --- 解析加载
3、Document通过 getElementsByTagName 获得 节点集合 NodeList
通过 NodeList 提供 getLength 和 item 遍历 节点集合
遍历ArrayList
for (int i=0;i<arraylist.size();i++){
arraylist.get(i);
}
遍历NodeList
for (int i=0;i<nodelist.getLength();i++){
nodelist.item(i); ----- 将遍历每个节点转换子接口类型
}
什么是 Node? 对于xml 来说,xml所有数据都是node节点 (元素节点、属性节点、文本节点、注释节点、CDATA节点、文档节点)
Element Attr Text Comment CDATASection Document ----- 都是 Node 子接口
node有三个通用API :
getNodeName():返回节点的名称
getNodeType():返回节点的类型
getNodeValue():返回节点的值 ---- 所有元素节点value都是 null
----------------------------------------------------------------------------------------
DOM 编程思路小结
1、装载XML文档 ---- Document
2、Document 获得指定元素 ----- getElementsByTagName (返回 NodeList)
3、遍历NodeList 获得 每个 Node
4、将每个Node 强制转换 Element
5、通过元素节点API 操作属性和文本内容
getAttribute 获得属性值
getTextContent 获得元素内部文本内容
package day02;
import java.io.IOException;
import javax.xml.parsers.*;
import org.junit.Test;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class Domtext {
@Test
public void text() throws Exception{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();//工厂
DocumentBuilder DBuilder=factory.newDocumentBuilder();//解析
Document document=DBuilder.parse("Books.xml");//装载
NodeList nodelist=document.getElementsByTagName("name");//获得节点集合
System.out.println(nodelist.getLength());
for(int i=0;i<nodelist.getLength();i++){//遍历
Node node=nodelist.item(i);
Element e=(Element)node;
System.out.println(e.getNodeName());
System.out.println(e.getNodeType());
System.out.println(e.getNodeValue());
System.out.println(e.getFirstChild().getNodeValue());
System.out.println(e.getTextContent());
System.out.println("----------------");
}
}
}先用全局查找锁定范围,再用相对关系查找 得到需要数据
getElementById 方法 必须用于带有约束 xml文档中 !!!!!!!
所以开发语言默认支持DTD,当使用Schema时,单独编程导入schema !
XML DOM 增加 、修改 和 删除操作 —— 操作 内存中文档对象
XML的回写代码示例:(也是三步走,工厂-解析-回写)
@Test
//回写
public void huixie() throws Exception{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse("Books.xml");
TransformerFactory TFactory=TransformerFactory.newInstance();
Transformer transformer=TFactory.newTransformer();
DOMSource domsource=new DOMSource(document);
StreamResult result=new StreamResult(new File("books.xml"));
transformer.transform(domsource, result);
}XML元素添加 : 1、创建节点元素 2、将节点元素加入指定位置
代码示例:
@Test
public void addnode() throws Exception{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse("Books.xml");
Element root=document.getDocumentElement();
Element newbook=document.createElement("book");
newbook.setAttribute("id", "b001");
Element name=document.createElement("name");
name.setTextContent("jsp");
newbook.appendChild(name);
root.appendChild(newbook);
TransformerFactory Tfactory=TransformerFactory.newInstance();
Transformer transformer =Tfactory.newTransformer();
DOMSource domsource=new DOMSource(document);
StreamResult result=new StreamResult(new File("book_bat.xml"));
transformer.transform(domsource, result);
}XML元素修改 : 查询到指定元素 1、修改属性 setAttribute 2、修改元素文本内容 setTextContent
代码参考上个代码
XML元素删除 :删除节点.getParentNode().removeChild(删除节点)
@Test
public void delete() throws Exception{
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse("Books.xml");
NodeList nodelist=document.getElementsByTagName("name");
for(int i=0;i<nodelist.getLength();i++){
Element name=(Element) nodelist.item(i);
if(name.getTextContent().contains("java")){
Element book=(Element) name.getParentNode();
book.getParentNode().removeChild(book);
}
}
TransformerFactory Tfactory=TransformerFactory.newInstance();
Transformer transformer =Tfactory.newTransformer();
DOMSource domsource=new DOMSource(document);
StreamResult result=new StreamResult(new File("book_bat.xml"));
transformer.transform(domsource, result);
}














 5590
5590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









