








Enhancing Language Multi-Agent Learning with Multi-Agent Credit Re-Assignment for Interactive Environment Generalization
前言
一篇基于强化学习的digital多智能体框架,与之前稀疏奖励的方法不同,作者基于LLMs设计了step-wise的奖励,并对多智能体通信框架进行优化,从而提升多智能体在mobile、Web场景的性能,同时具有良好的泛化能力。| Paper | https://arxiv.org/pdf/2502.14496 |
|---|---|
| Code | https://github.com/THUNLP-MT/CollabUIAgents |
Abstract
当前,多智能体系统优于单智能体,但是受限于预定义的角色,以及语言智能体泛化策略不充分,阻碍了多智能体在浇花环境中的性能。本文提出了 CollabUIAgents 框架,利用一种新颖的多智能体奖励重分配(CR)策略,通过 LLM 分配过程奖励而非环境特定奖励,并使用合成的偏好数据进行学习,从而促进没有角色限制的智能体策略之间的协作和泛化。实验证明,该框架在性能和跨环境泛化能力方面均有所提升,且7B参数系统的表现与强大的闭源模型相当或更好。
Motivation
当前语言模型在实际交互环境中的性能提升与泛化能力之间存在难以调和的矛盾,这一问题已成为研究领域的重要挑战。具体而言,现有方法存在以下主要局限:
- 单智能体方法过度依赖特定领域(in-domain)数据,导致其在跨领域场景下的泛化性能显著受限;
- 即使在多领域数据集上进行训练,单智能体模型仍然难以取得理想的效果;
- 多智能体方法虽然在特定任务上展现出更优性能,但其泛化能力并未得到显著提升。
这一困境表明,当前模型在强性能与良好泛化能力之间尚未找到有效的平衡点,实现两者的有机统一仍是一个待解决的难题。
Solution
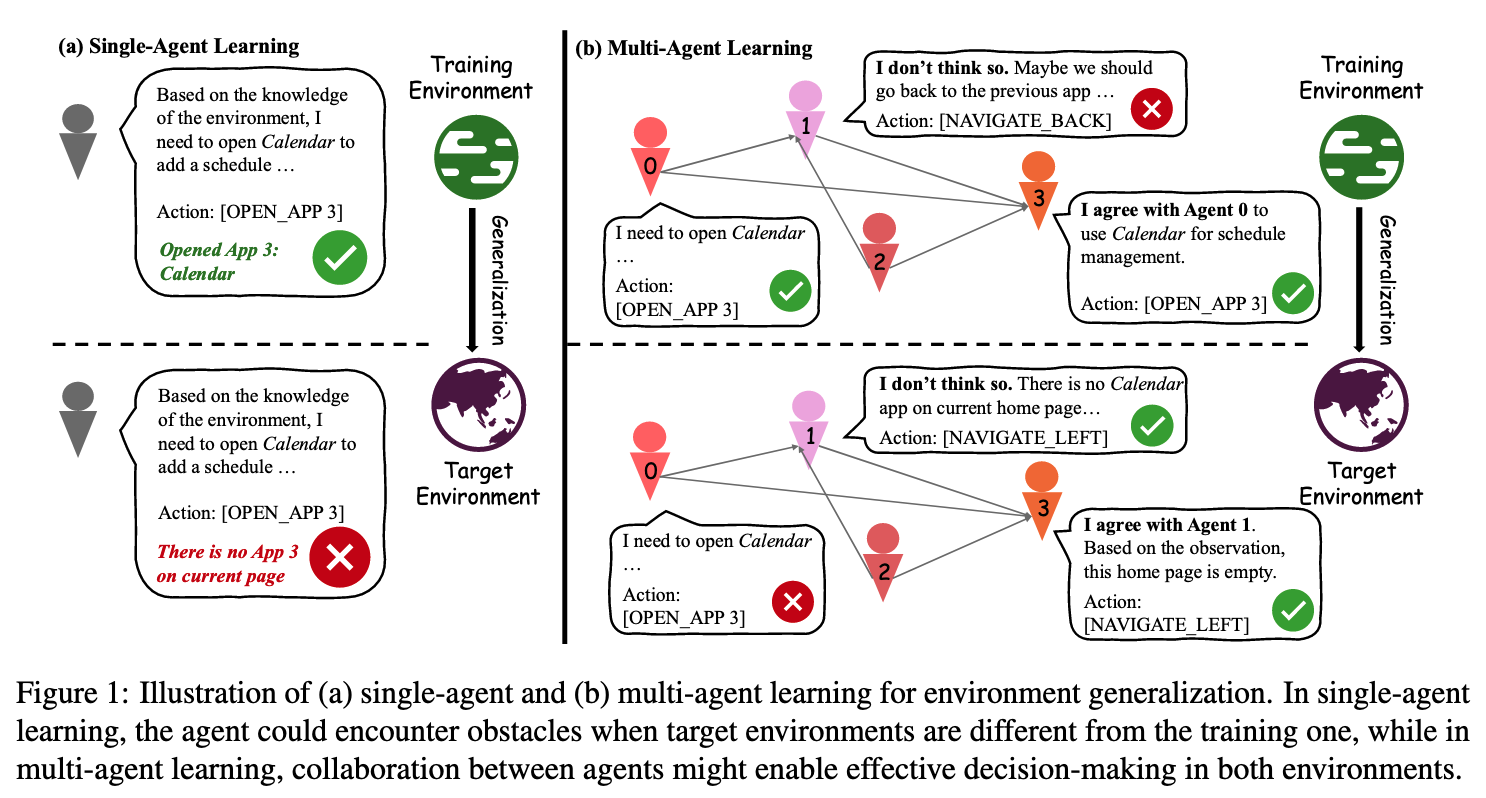
受传统多智能体强化学习(MARL)中合作过程模拟的启发,智能体间的协作机制可能为不同环境下的泛化能力提供有益补充(如图一所示)。与现有的多智能体奖励分配(credit assignment)方法不同,本文在丰富稀疏奖励信号方面取得了创新性突破,致力于提升智能体的泛化性能并有效缓解错误奖励分配问题。所提出的多智能体奖励重分配策略通过LLM进行过程奖励分配,而非依赖于环境特定奖励,并借助合成偏好数据进行学习。这种设计有助于实现无角色约束的智能体策略协作,同时显著提升其泛化性能。
具体流程如下:
- 利用agentic微调的模型作为基座,初始化多智能体系统。
- 当智能体系统采取动作时,判别智能体根据环境和动作的理解,为每个智能体和每轮对话分配奖励。这样奖励更精细,同时从失败中恢复的轨迹又扩大了数据的规模。
- 为了防止判别智能体可能会误导智能体,会利用对抗性智能体合成的偏好数据来优化策略,从而确保智能体得到正确的引导。
- 经过偏好优化后,多智能体系统不仅会更新模型的参数,还会优化智能体之间的通信结构。
CollabUIAgents适用于跨环境UI系统,支持手机和web环境。
CollabUIAgents
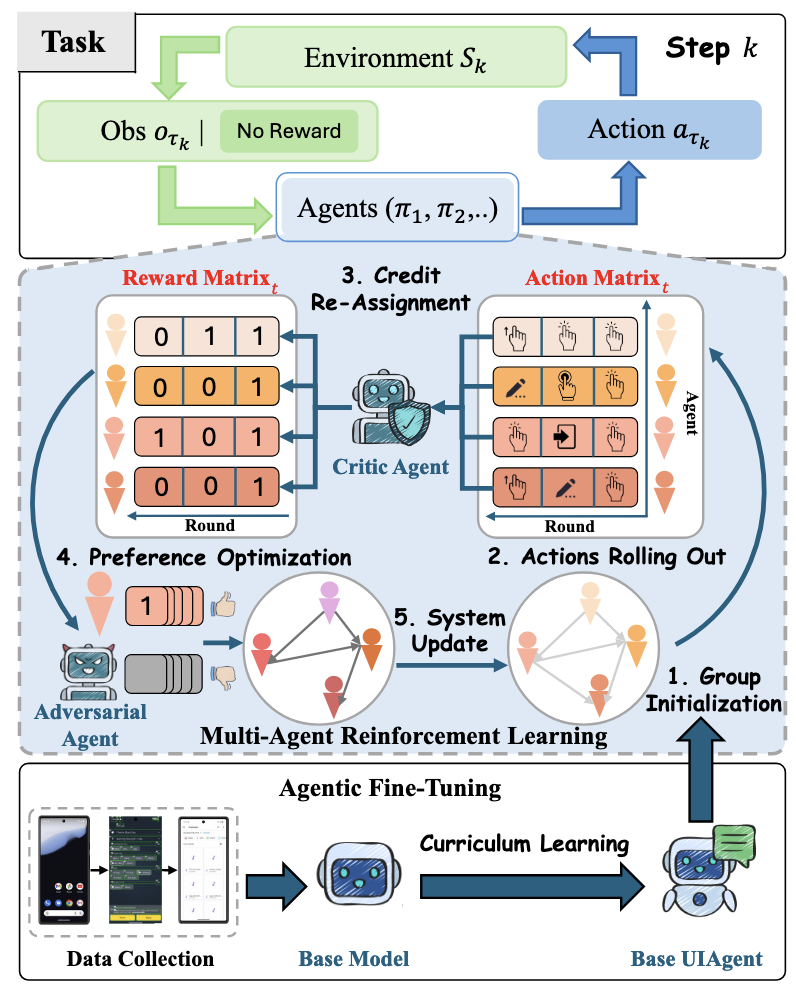
本系统采用了基于有向无环图的多智能体架构。在每一轮对话中,所有智能体均按照预定义的网络拓扑顺序依次输出动作和相关信息。为了确保决策的高效性和可解释性,每个智能体仅接收上一轮对话的输出结果作为当前决策依据,从而有效避免了上下文过长可能引发的计算复杂度问题。最终,在每个时间步t,系统采用多数投票机制来确定最终决策结果,如下面公式所示:
$ a_t=f_{\operatorname{agg}}\left(\boldsymbol{A}t\right)=\operatorname{argmax}a \sum{i=1}^n \sum{j=1}^m \mathbf{1}_{a_t^{i, j}=a}, $
该系统的关键创新点在于其多智能体强化学习(MARL)模块,该模块分为三个部分:
- 奖励重分配策略
- 基于对手智能体合成数据的偏好优化机制
- 边缘更新技术
Credit Re-Assignment
传统的MARL系统奖励稀疏,为此现有的工作为每个智能体提供奖励,但为每个智能体训练判别模型会带来巨大的开销,同时降低泛化能力。本文的方法采用基于LLM的判别智能体,为每轮对话每个智能体带来过程奖励。判别智能体会根据当前环境的观测、交互的历史(上一轮)以及任务,从而生成0/1的奖励矩阵,表示如下:
$ \boldsymbol{R}t=\left\lceil\pi{\text {critic }}\left(o_t, H_{t-1}, \boldsymbol{A}_t, q\right)-0.5\right\rceil, $
为了克服错误的奖励,作者引入了对抗智能体,通过合成偏好数据来代替策略优化的学习。具体来说,对抗智能体基于正确的动作生成低质量的回复:
$ a_t^{i, j,-}=\pi_{\mathrm{adv}}\left(o_t, H_{t-1}, C_t^{i, j}, q\right), \text { if } r_t^{i, j}=1
$
这样的设计的理由如下:
- 判别智能体可以为每个智能体生成详细的奖励信号,无需对每个智能体单独训练。
- 判别智能体基于LLMs,可以通过对失败轨迹进行恢复来扩大数据量,提升性能。
- CR中错误不可避免,但是合成的偏好数据可以为模型提供有意义的偏好信号。
MARL with Edge Updates
与传统的MARL不同,CollabUIAgents的智能体可以互相交流,并且这些通信的结构也是优化的一部分。但是如果对所有通信方式(边的组合)进行优化,计算资源消耗会特别大。因此作者提出了一种“边更新”的技巧,通过随机对边进行更新来形成一个有向无环图的通信网络,该过程更新与模型参数的更新分隔,不会相互干扰。该过程可以让智能体适应不同的网络通信结构,提高智能体之间的协作能力。每个智能体的学习目标如下式所示:
$ \begin{aligned}
& \mathcal{L}{\mathrm{MARL}}\left(\pi_i\right)=-\mathbb{E}{\mathcal{E}{\mathcal{G}}^{\prime} \sim K{|\mathcal{G}|}} \mathbb{E}{\left(s_t, a_t^{i, j}, \hat{H}t^i\right) \sim \mathcal{P}\left(\mathcal{G}, \mathcal{E}{\mathcal{G}}^{\prime}\right)} \
& \sum{t=0}^{T_{\max }} \sum_{j=1}^m\left[\operatorname { l o g } \sigma \left(\beta \left(\frac{\log \pi_{\theta_i}\left(a_t^{i, j} \mid o_t, \hat{H}t^i\right)}{\log \pi{\operatorname{ref}_i}\left(a_t^{i, j} \mid o_t, \hat{H}t^i\right)}\right.\right.\right. \
& \left.\left.\left.\quad-\frac{\log \pi{\theta_i}\left(a_t^{i, j,-} \mid o_t, \hat{H}t^i\right)}{\log \pi{\operatorname{ref}_i}\left(a_t^{i, j,-} \mid o_t, \hat{H}t^i\right)}\right)\right)\right] \cdot \mathbf{1}{r_t^{i, j}=1},
\end{aligned} $
CollabUIAgents最大的优势之一是具有泛化到不同交互环境的能力,该框架有两个方法对泛化进行支持:
- 直接迁移。相似的场景可以直接迁移。
- 持续MARL。即使场景有很大不同,可以在新环境对CR策略的MARL进行持续的训练。
Experiment
实验在Mobile端选用动态环境AndroidWorld、MobileMiniWoB++,指标为SR(success rate)。在Web端选用Mind2Web、AutoWebBench,指标为SSR(单步SR)。
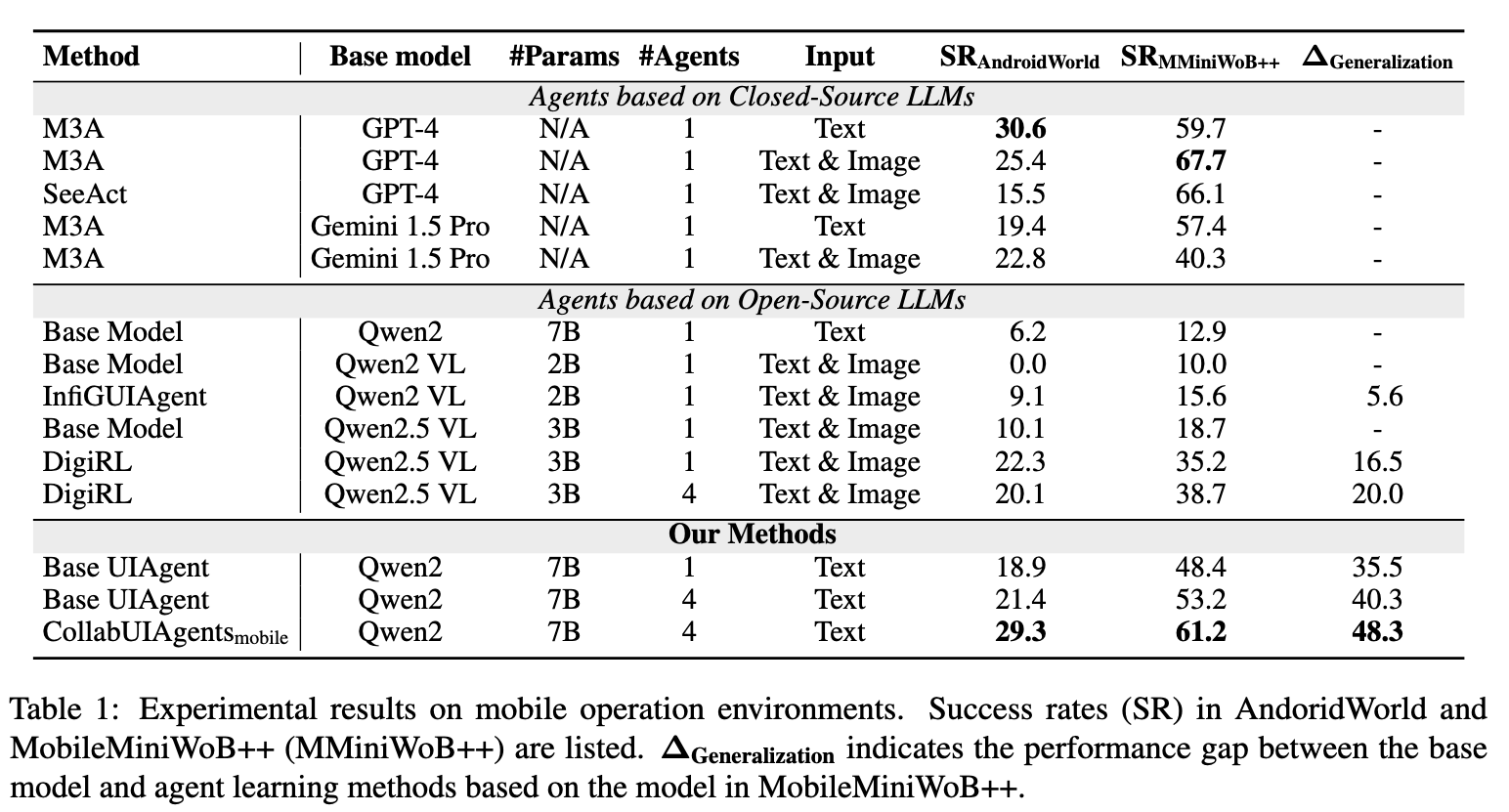
Mobile的结果表明:
- agentic fine-tuning对开源模型提点明显,甚至超过多智能体系统。
- CollabUIAgents在开源模型中表现最好,在闭源模型中甚至超过GPT-4。
- InfiGUIAgent训练数据量虽然大,但是表现不佳。
- DigiRL表现不错,但是泛化性不好。
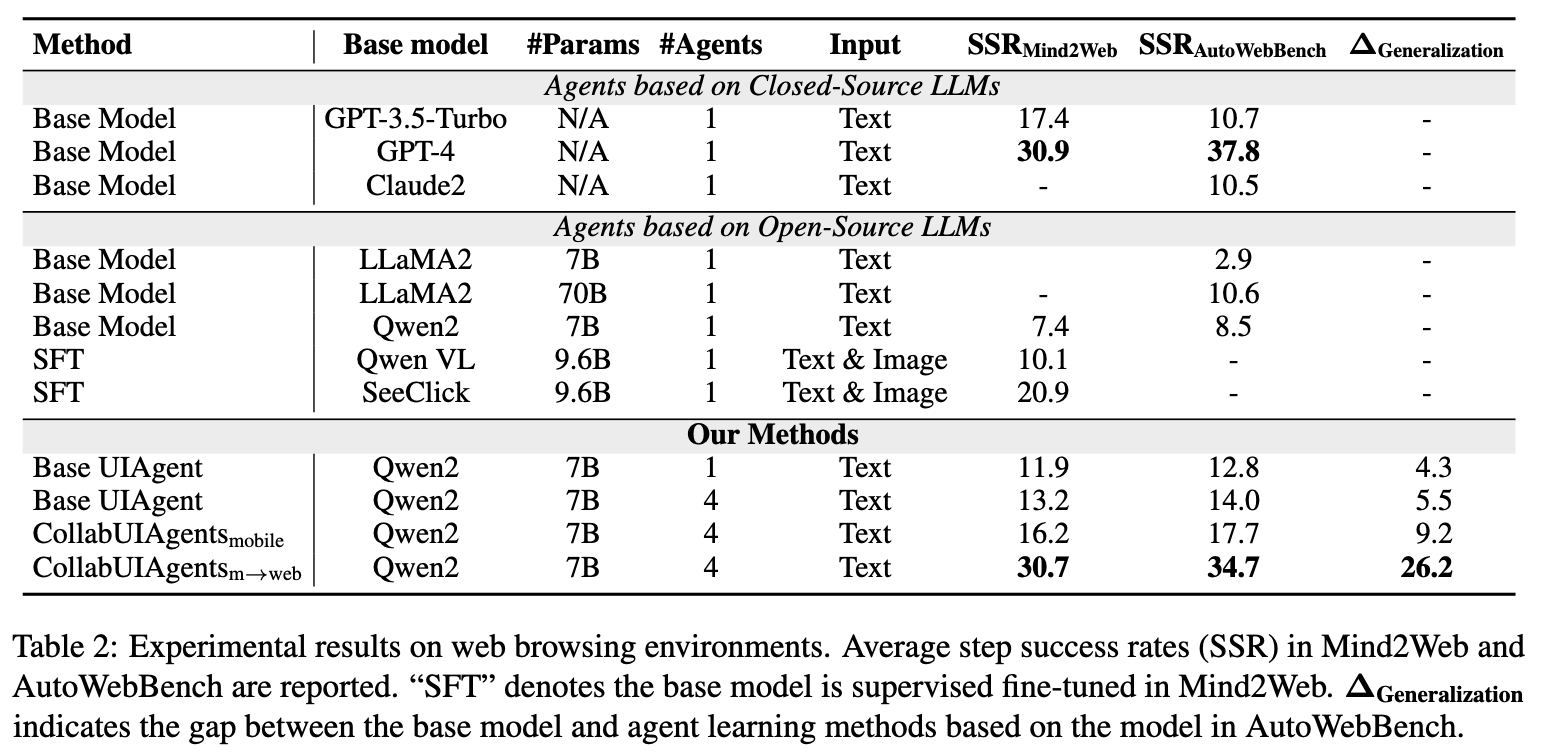
Web端的实验表明,持续的MARL可以显著提升模型跨环境的泛化能力。
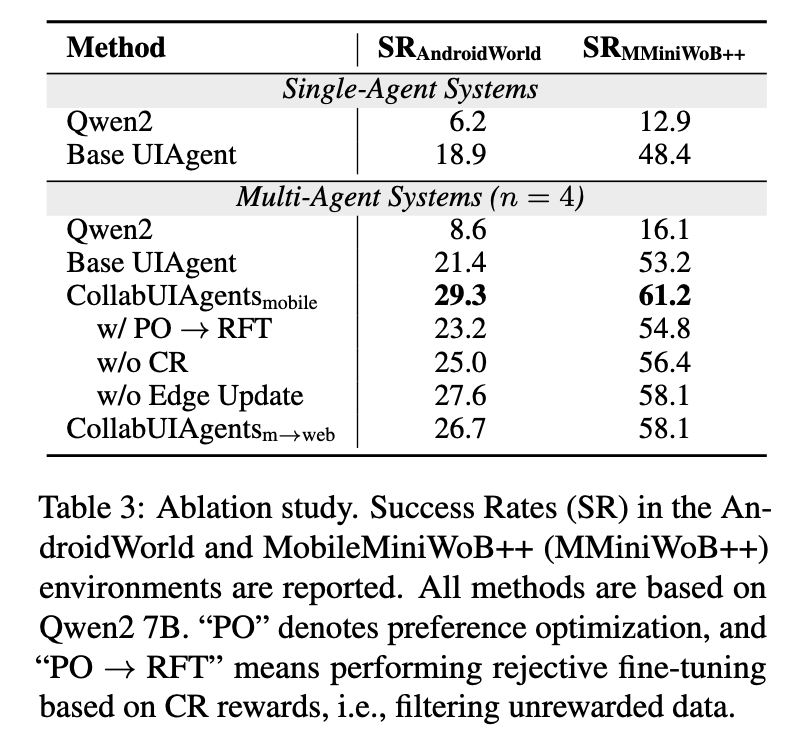
消融实验的结果表明:
- SFT和DPO对性能都能有提升,但是SFT只学习正确的动作,而DPO还可以学习错误的动作,带来进一步的性能提升。
- 但是二者都面临奖励稀疏问题,改进程度不够显著。
- 奖励重分配为每一步提供更细粒度的反馈,有利于智能体在庞大的动作空间中探索。
- 合成的偏好数据也有利于提升泛化性能。
- 基于Base Model的多智能体系统会有适度的改进,同时agentic fine-tuning很重要。
- 边缘更新有助于让LLMs在多智能体系统中更好融入。
- 迁移过程不会让模型在原始环境的表现有太大的损失。
Conclusion
本文提出一种新颖的基于RL的多智能体框架,用于解决在交互环境中性能表现和泛化能力权衡的挑战。该框架采用CR策略,利用LLM的先验知识来分配奖励,并利用合成数据优化策略。实验表明该框架在高性能表现的同时,又具有很好的泛化性能。该方法为当前智能体有限的学习方法提供了更灵活、数据高效和可推广的方案。
但是这篇文章通读下来,我个人还是有很多疑惑的地方:
- 文章方法部分写的晦涩难懂,RL的训练细节不清晰。抛开细节来看,本文的工作似乎就是利用step-wise的reward来优化多智能体协作,本质上也是投票机制?
- Base UIAgent用的什么数据训练的呢?AndroidWorld本身是不提供任何in-domian数据的。
- 不同方法之间的比较不公平,模型大小不同,模态不同,直接混为一谈没有说服力。
- 为啥Web端的实验没有基于Mind2Web数据SFT的Qwen2?很好奇从mobile端到web端的迁移能不能超过in-domain数据SFT的效果。
- 多智能体一定是最优解吗?在GUI场景,多智能体效率太低,用户不可能为了极致的性能而为一个动作等待太久时间(比如10s),更何况,现在的单智能体表现已经很好了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











