






Satble Diffusion 给视觉设计带来了前所未有的可能性和机会,它为设计师提供了更多选择和工具的同时,也改变了设计师的角色和设计流程。然而,设计师与人工智能软件的协作和创新能力仍然是不可或缺的。接下来我将从三个维度来向大家分享 Satble Diffusion 在视觉设计方向的技巧应用。
一、线稿/插画秒变3D
1. 线稿秒变 3D 场景
在人工智能绘画软件之前,我们如果想将一张线稿设计图转变为一幅 3D 场景可能需要非常复杂的过程,比如:线稿填色成平面插画,然后根据画面物体的结构在 3d 软件中进行建模,最终根据配色进行打光渲染等步骤来完成。而现在我们运用 stable diffusion 甚至数秒的时间就可以完成一系列方案。
关于 stable diffusion 的使用原理网络上有许多详细的教程,在这里就不向大家赘述。接下来我将向大家分享如何运用 SD 将 midjourney 生成的线稿图转变为 3d 场景。

整个的创作过程在文生图模式下进行创作的,大模型选择的是 disneypixarcartoon_v10.safetensors,外挂 VAE 滤镜为 chilloutmix_Niprunedfp32fix.vae.ckpt;最关键的部分 controlnet,前后都选择为 canny-边缘检测或者也可以尝试 lineart-标准线稿提取(将线稿图上传其中),根据画面添加正反向具体的描述关键词,不断的去调整合适的参数,就可以得到我们想要的效果。

如果最终效果图部分视觉没有达到我们的预期,我们可以结合图生图模式下的局部重绘或者上传重绘蒙版功能,运用重绘蒙板结合关键词进行重新绘制,直达到我们的预期效果为止。当熟悉了整个创作模式后进行批量输出方案时,线稿输出 3d 画面的效率大大超出我们的想象。

2. 平面卡通 IP 秒变 3D 角色
除了上述的线稿转 3d 场景之外,我们日常的平面 IP 卡通人物也可以通过 stable diffuson 秒变 3d 人物,在实现过程上述的案例有所不同,因为我们需要更加精准的按照我们的平面插画进行 3d 人物的制作,当然我们更期望最终的 3d 形象与我们的平面效果完全吻合,因此这里我们不再使用文生图模式,而是采用图生图模式来进行更精准的控制。
以一张用 midjourney 生成的 ip 卡通平面三视图为例:根据我们卡通人物的特征,添加详细的正反向描述关键词来构建预期效果,重绘幅度数值设置为 0.5。另外,在模型的使用上还是有很大区别的,大模型选用了 revanimated_v122.safetensors,滤镜是 animevae.pt。controlnet 采用 depth-zoe 控制深度;canny 或者 lineart-anime 控制外形线稿的提取;关于 lora 模型选择了 blindbox 给予类似于盲盒有趣的 3d 效果,另外还使用了 charturnerv2:0.4 这个 lora 模型用来增强模型的塑料质感,最终就形成了如图的 3D 角色。

二、人物场景的精准控制
在互联网许多应用领域筛选出符合预期的人物场景图是一个难题,但是自从有了 stable diffusion 之后,这个难题几乎迎刃而解。通过 stable diffusion 的图生图模式,配合 controlnet 的精准控制就非常容易达到我们想要的预期效果。当然在这个过程中,为了避免版权纠纷问题,在使用图生图的底图时尽量选取我们拥有版权的图片,这样在这个基础上做衍生就规避了版权的风险。


比如,现在我想要一张(如下图)同样姿势的工作人员不是站在空调旁边,而是想让他站在微波炉旁边的场景,那么我们可以将原图放在图生图模式下,大模型同样选用 relisticv20,滤镜选择 animevae.pt。lora 模型选择 filmvelvia2 类似于胶片质感来烘托真实的场景氛围;controlnet 运用的是 openpose_full 用其来控制人物的姿势状态,配合重绘幅度参数的调节以及正反关键词的描述来达到想要的效果。本案例的正反关键词描述如下:
正向关键词:A handsome smiling Chinese repairman is standing under the microwave oven, wearing a green T-shirt. There are some white furniture in the scene, dramatic lighting,
一位面带微笑的中国修理工站在微波炉下,身穿绿色 T 恤。场景中置放了一些白色的家具,引人注目的灯光。
反向关键词:EasyNegative ,GS-DeMasculate-neg,bhands-neg, lowres Unreasonable view (worst quality:2), (low quality:2),
前 3 个英文单词是调用的 embeddings 文件名称,低分辨率的,不合理的视图(最差质量:2),(低质量:2)

另外在真实人物场景的输出过程中,很多时候人物的手部、脸部会出现问题,我们可以通过 SD 的进阶模型 embeddings 在一定程度上去修复画面手部的问题,例如调节手部的模型 bhands-neg.pt;对于人物脸部扭曲的问题,我们可以运用 face editor 插件,通过调整参数来使人物的表情更加真实自然。

三、SD设计创意字体
Stable diffusion 除了可以创作上述的 3d、真实场景图之外,当然也可以完成创意风格字体的设计。对于创意风格字体我们可以通过文生图的形式,给予 sd 更多的创作空间可以产出多样风格的字体样式,接下来继续和大家分享如何将白底黑字转变为我们想要的创意风格的创作过程。


以上图冰块文字为案例:整个过程是在文生图模式下进行的,在大模型上需要选择是:realisticVision,滤镜选择的是:VAE 模型 vae-ft-mse-840000-ema-pruned.safetensors,如果没有的话可以前往 c 站去下载。采样方法在这个案例中选择了 DPM++ 2M Karras,Controlnet 预处理器运用的是 lineart(标准线稿提取),模型运用的是 lineart。然后在里面导入我们的白底黑字图片,在正反向描述语里描述我们想要的效果,经过多次尝试就会遇到意想不到的惊喜。最后为了更好地提高视觉效果细节,我们可以将最终图片导入到图生图模式下(描述同文生图),Controlnet 预处理器选择 tile_resample,模型选择 control_v11f1e_sd15_tile,经过二次处理后会发现视觉效果更加惊艳细致。当然在这里主要是向大家介绍制作创意风格字体的一个思路,具体的参数和模型大家可以根据具体情况去调节。

以下为本案例使用的关键词:
正向关键词:high quality, masterpiece, ((Transparent ice cubes)), glacier background,
高品质,杰作,(( 透明的冰块 )),冰川背景。
反向关键词:EasyNegative, BadArtist, BadPrompt, BadImages, poor anatomical structure, low quality, text errors, extra numbers, fewer numbers, jpeg artifacts, signatures, watermarks, username, blurring, cropped,
前 4 个英文单词是调用的 embeddings 文件名称,解剖结构差,低质量,文本错误,多余的数字,缺少的数字,jpeg 伪影,签名,水印,用户名,模糊,被裁剪的。
如何运用Stable Diffusion完成运营设计海报

一、制作前期构思与参考
这次需求是制作一张活动推送图,推送给玩家增加活动热度以及获取更多流量。
需求方希望画面中主要体现 IP、信件相关的元素,能给人一种在书写信件的画面感。按照需求方所给到的信息,我们找了批参考图供给需求方确认画面大致感觉。

通过参考图与需求方的沟通后,我们大致确认画面是一张信纸在桌面上,信纸上写着本次活动的相关内容。
二、确定风格&AI 运用
视觉风格上,通过讨论以及参考图的视觉效果,最终还是决定倾向于三维质感,不过这次我们打算尝试运用 AI 辅助制作整体的画面基调。
因为之前做过一版类似的推送图,所以本次就相当于做一次画面迭代,而用 AI 来进行画面的迭代也正好是非常合适的。

话不多说,我们先进入到 Stable diffusion。首先,我们进入到图生图界面,将垫图素材拖入图生图的图片区域。输入好关键词并调节好参数开始炼图。

关键词如下:The center of the image is a piece of paper on the table, The image is a close-up shot, showing the details of the paper, The image is taken from a bird’s-eye view angle, Close-up view, indoors, the scene is bright, The overall picture is bright, The picture is a 3D modeling, C4D, Octane renderer, masterpiece, best quality, highres, original, reflection, unreal engine rendered, body shadow, extremely detailed CG unity 8k wallpaper, minimalist
(在这里我们使用了 toon2 和 COOLKIDS 这两个 lora 模型。模型不唯一,可根据自己需求在 C 站上自行选择下载。)
反向关键词:(worst quality:2), (low quality:2), (normal quality:2), lowres, ((monochrome)), ((greyscale))
反向关键词就使用一些通用的即可。
参数内容如下:

其中要注意下,在一开始炼图时,重绘幅度需要大概控制在 0.5-0.7 范围内,避免变化过大破坏构图,也要避免变化过小达不到画面迭代的效果。
接着就可以开始炼图了,这个环节对比 Midjourney 来说,可以避免花费过多时间炼图,Stable Diffusion 的可控制参数比较多,也因此可以更快的炼出接近自己想要的图片。

以上是筛选出的几张图,接着再选出一张图作为本次需求的底图,并开始进行下一环节的操作。
三、SD 放大&重绘功能的使用
我们选择用第二张图作为底图,但是放大后不难发现,它的分辨率低,不清晰。有很多细节也存在缺失的问题。这个时候我们可以对他进行 SD 放大操作。

1. SD Upscale 介绍
SD Upscale 也被叫为 SD 放大,简单理解可以把它看作是图生图中的高清修复。它的工作原理是将要放大的图片均匀的分成多块,分别进行重新绘制,并最终拼回一张图,以此来进行高清放大的效果,于此同时还能为画面添加不少细节。
我们可以在图生图界面中滑至最下方,点击脚本这一栏展开,里面有一个使用 SD 放大(SD Upscale),点击选择即可开启。(注意,只有图生图才能使用该脚本)

2. SD Upscale 的使用
首先,我们将底图拖入图生图的图片区域,然后打开 SD 放大,其中放大倍数以及图块重叠像素可以不做变化,放大算法可以选择 R-ESRGAN 4X+ 或者 R-ESRGAN 4x+ Anime6B(这个偏向二次元一些)。其它也可以尝试,这两个放大算法是我们比较常用的。
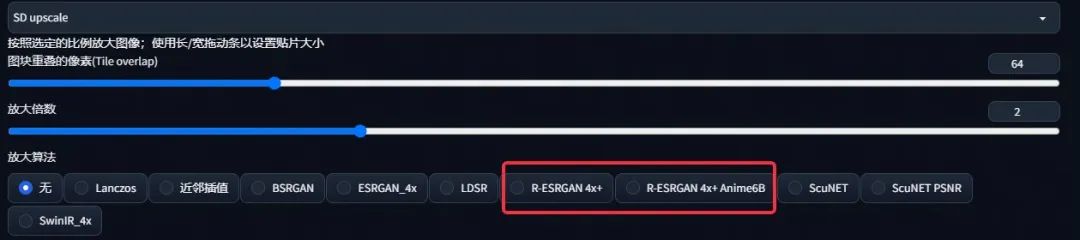
接着我们在画面尺寸这里,宽度高度分别在原来的基础上加上图块重叠的像素数值,也就是分别加 64。对应着现在的宽度为 902,高度为 512,加上 64 后宽度就变为 966,高度变为 576。

也许很多人疑惑为什么要加上这 64 像素呢,这里简单解释下。因为 SD 放大的原理是将一张图分成均匀的多块重新渲染,然后再重新将这几块图片拼回一张图。而为了使拼接部分不会出现断层,割裂等不和谐的感觉,在这四块图片的贴合处增加了一部分区域,算法会利用这部分区域去处理拼接处,使得拼接位置过度的更加自然,整体。
回到正题,设置好后,将重绘幅度调低至 0.3-0.35(因为只是用于高清修复,并不想画面内容发生变化,所以此时要保持低重绘幅度),设置好后就可以开始生成图片了。

以上是高清修复后的图,可看到画面的清晰度肉眼可见地提高了,画面的细节也丰富了不少。但是也存在着一个问题,画面有许多奇怪的物体,以及一些 bug 存在,这时候就可以开始用到 Stable Diffusion 的重绘功能了。
3. 重绘功能的使用
首先,我们想去掉纸上的内容,并且把桌子上一些杂乱的东西都去掉,我们可以选择把图片导入 ps 里进行简单的 p 图处理,然后再导回 Stable Diffusion 中的图生图,将重绘幅度调低再生成一次即可。(一般重新用图生图输出的图片分辨率都会变低,需要重新用 Stable Diffusion 放大高清修复一下,然后再在此基础上进行重绘)

紧接着我们开始对画面个别元素进行调整。首先,我们想把右上角的黄色卡纸换成信封,这时候我们就可以运用涂鸦重绘功能。点击涂鸦重绘,进入涂鸦重绘版面。

因为我们想把卡纸换成黄色的信封,点击右上角的色盘 icon,选择黄色,调整画笔大小,在卡纸的位置涂上一层,示意这里要换成一封信(注意涂鸦的造型尽量和想生成的物体的造型接近,这样有利于算法识别)。然后在关键词后加上一个黄色的信封,并给上一些权重。(a yellow envelope:1.3)
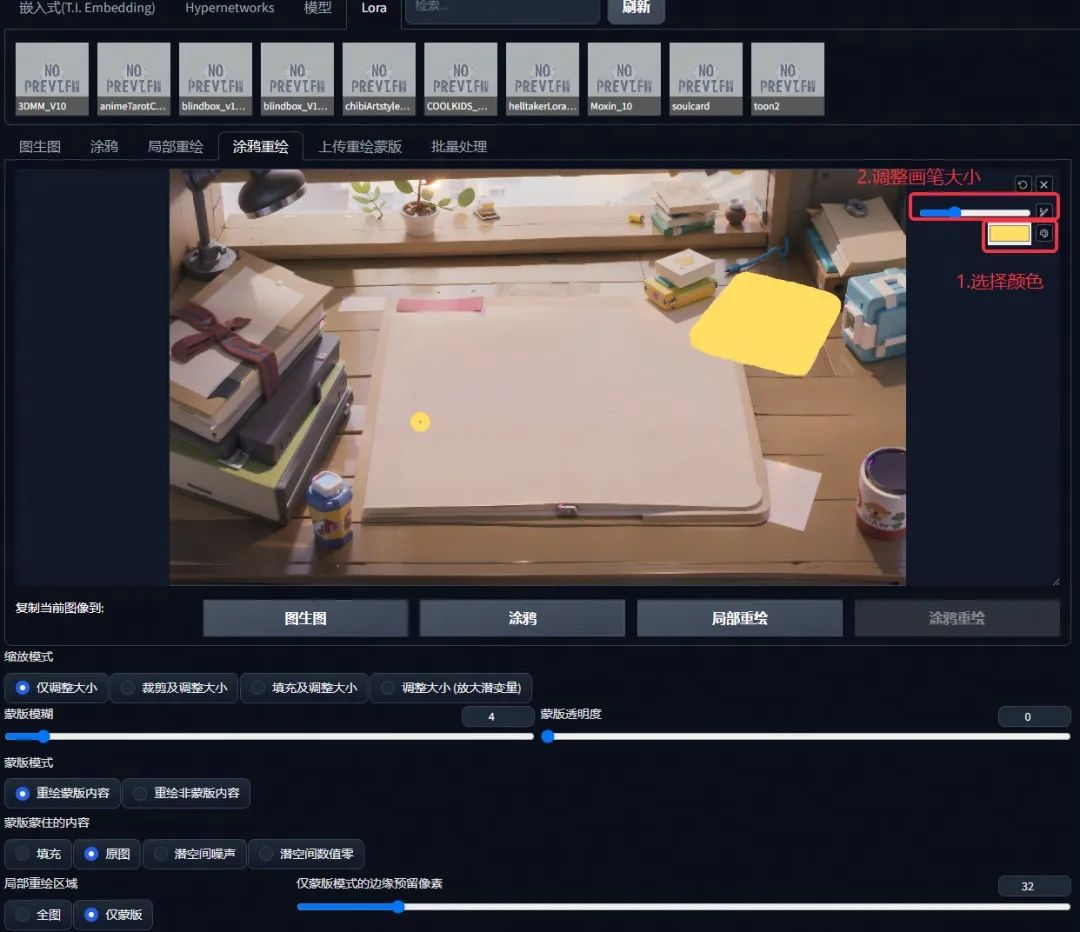

点击生成后,多生成几次图,挑选较为满意的一张后,先不着急细化修改,继续把画面其它想要替换的物品调整好。替换的方式也可以像信封一样,使用涂鸦重绘即可。

不过像重叠的书本,或者玩具这类,造型轮廓不规则的,AI 在计算过程可能不能很好地识别。这个时候我们也可以直接使用局部重绘功能,在要重新绘制的区域涂上一层蒙版,然后在关键词后补充上想要替换的内容。例如一叠书本,就在关键词后补充上(A stack of books:1.4),记得加一点权重。


通过这种方式,我们可以把画面里想要替换的元素都替换掉,并且风格也能保持一致,实现“指哪打哪”。(当然,这也避免不了需要多次炼图,尽管 Stable Diffusion 可控性好,但 AI 始终是 AI,想要直接渲出自己想要的图片还是很难的。)

到最后,我想在桌面上加一支笔和一个闹钟,但是在涂鸦重绘过程中,始终渲不出我想要的效果。这个时候我们可以找一个笔和闹钟的 png 素材在 ps 里简单处理下放在画面中,然后再把它放回到 Stable Diffusion 的图生图中,调整好低重绘幅度然后重新生成,最后筛选出较为满意的进行后期细化即可。

到了最后阶段,我们就可以回到 ps 里去增加一些画面的细节和内容了。

最后的最后,给画面加一些后期氛围处理后得到最终版本。
总结
在这个案例中我们也没有使用较为新颖的功能,主要就是 Stable Diffusion 放大和重绘功能,这两功能在 Stable Diffusion 也算是比较基础的。学习新的技能固然重要,但去探索如何运用这些技能去实现项目落地的方法思路更为关键。
三步搞定场景定制化

随着人工智能的逐渐发展,越来越多的 AI 工具也一窝蜂的涌现出来。
在众多的 AI 利器当中 Midjourney(简称 MJ)和 Stable diffusion(简称 SD)两款软件在图片的效果呈现上表现尤为突出,虽然 MJ 能够通过描述关键词来对图像进行调整,但总觉得跟脑海里设想的那张图还差一点意思,不能完全的符合心里预期。
迫于这个原因我们将经历投入到 SD 的学习当中,在学习的过程中发现 SD 的操作界面对设计师来说比较友好,操作界面更类似于一款软件的操作界面,感觉是在学习一门技术(可能是总用绘图软件做图留下的后遗症)。
在实际操作 SD 这款软件时有两点是强于 MJ 的:1.它可以精准控制画面的构图及布局。2.它也可以定制画面的输出风格。在工作上能将所设想的草图通过 control net 插件进行百分之百的还原,可以说大大的提高了出图质量及数量。
本次分享将结合平时工作中,应用到 SD 软件进行出图的实操经验,通过对 SD 的运用输出行业场景图来给大家做一些示范。在日常的工作中,为了保证视觉构图还有画面风格的一致性,有意去搭建了属于赶集行业特征的运营场景素材库,目的是为了让设计师能灵活调用,随做随取,节省时间提高效率。

在开始实操之前,先来说下 SD 的工作流程:1.前期需要在脑子里构想一个场景图,并借用绘图软件勾勒出大概的草图轮廓线。2.通过 SEG 图表找到对应材质的色值(SEG 色表大家可以网上搜索自行下载),实现对画面中摆放物体的材质进行精准调节。3.将文生图得到的图片转到图生图中借助 control net 插件中 tile_resample 模型对图片里的细节进行处理于此同时使用脚本中的 UItemate SD upscale 模型将已得到的图片进行人为放大(这样做是为了在图生图的放大过程中同时修补画面细节)

一、线稿生成图
好的废话不多说,咱们开始演示:
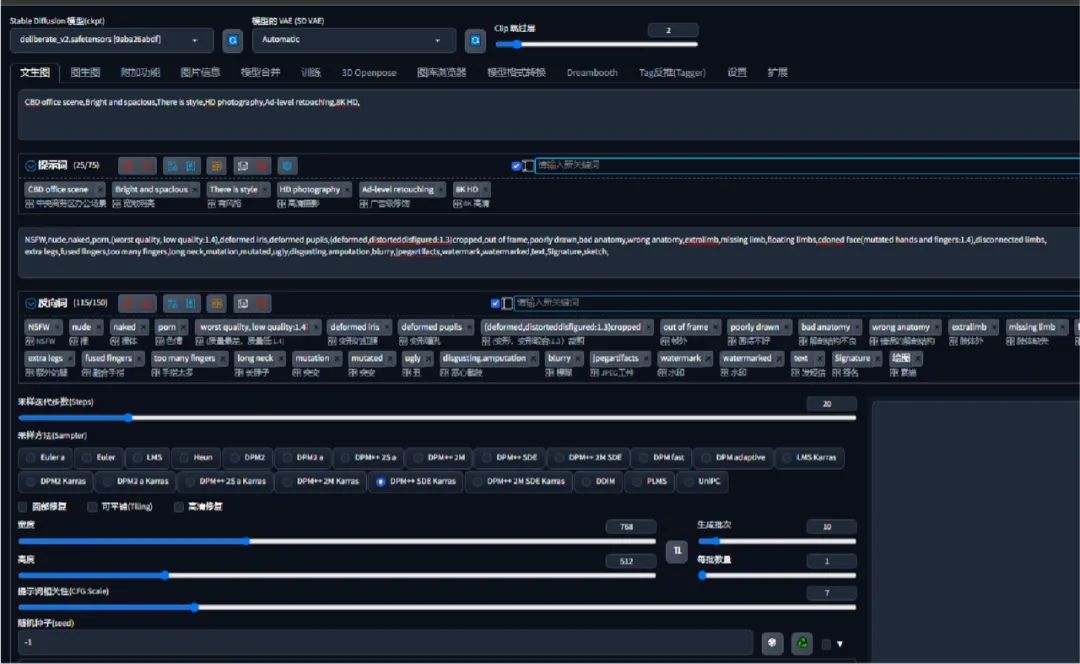
第一步输入正向关键词:CBD 办公场景,宽敞明亮,有格调,高清摄影,广告级修图,8K 高清,CBD office scene,Bright and spacious,There is style,HD photography,Ad-level retouching,8K HD,
反向关键词:
NSFW,nude,naked,porn,(worst quality, low quality:1.4),deformed iris,deformed pupils,(deformed,distorteddisfigured:1.3)cropped,out of frame,
poorlydrawn,badanatomy,wronganatomy,extralimb,missinglimb,floatinglimbs,cdonedface(mutatedhandsandfingers:1.4),
disconnectedlimbs,extralegs,fusedfingers,toomanyfingers,longneck,mutation,mutated,ugly,
disgusting.amputation,blurry,jpegartifacts,watermark,watermarked,text,Signature,sketch,
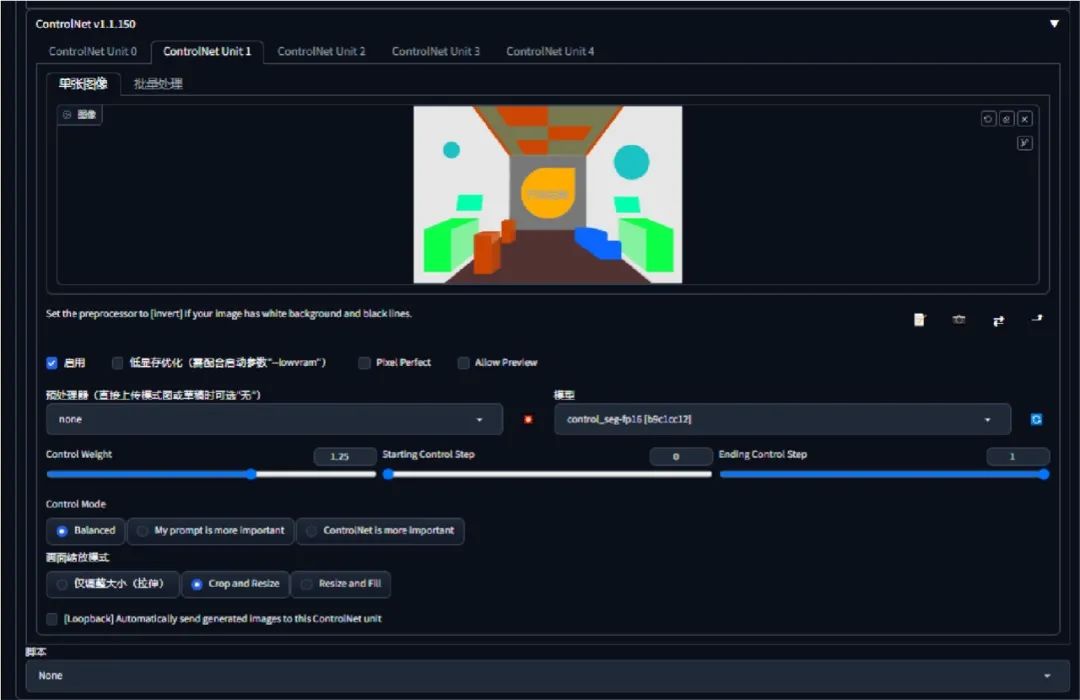
输入关键词的同时将脑子里的想法通过绘图软件绘制成线稿图(这个线稿的布局及外形决定了出图的结构及布局),将绘制好的草图上传至 control net 插件里选择 scribble 模型(实际操作界面如下)。

生成效果如下:

二、SEG色值生成
第二步:根据画面需要对场景内的物体进行材质更换(这一步需要配合关键词即画面中出现的材质需要在关键词中也对应提及,关键词的重要程度要用()强调,同样也借助 control net 插件里选择 seg 模型,配合第一步的操作双开 control net 模型,SEG 权重的大小数值,决定最终呈现的效果。

生成效果如下:


三、放大图片调整细节
第三步:选择一张自己心仪的图片然后转到图生图模式,将图片结合 control net 插件中的 tile_resample 进行细节丰富,同时使用脚本中的 UItemate SD upscale 模型将其放大至自己想要的图片大小。


好啦,现在你已经得到了一张定制化的场景图片了,是不是还是蛮精准的,按照我们上述的操作路径,我们分别对餐饮场景、销售办公场景、美容美发场景进行了批量生成,效果图片如下。
生成餐饮场景效果如下:

生成美业场景效果如下:

生成销售场景效果如下:

总结:AI 自我的学习能力非常强大,每一刻都在迭代,可能身处这个时代的我们能做的就是不断的拥抱变化,学习如何去驾驭 AI,学会用 AI 为工作提效,希望能从不断的学习探索中找到新突破。
文章使用的AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。
写在最后
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

若有侵权,请联系删除















 7370
7370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









