






大家好,我是写编程的木木。
昨天马斯克的 Grok-2 发布,加入了 FLUX 模型提供的文生图能力。一夜之间,FLUX 毫无底线的图片血洗 X(推特)。
自从 Google 把美国开国总统和印第安人都画成黑人之后,马斯克带头掀起另一个极端的文生图刷屏现象。
FLUX 模型,来自于德国创业公司 Black Forest Labs,拳打 MJ 脚踩 SD,图片质量做到了行业天花板,道德底线也压到了地板砖。文章底部给大家准备了一些亲测好用的FLUX工作流和模型,有需要的小伙伴可以自取,无偿分享。

01
生成质量高,
内容「毫无限制」
首先在 X 上引起热议的,是前几天网友制作的 TEDx AI 讲师。

仔细看,嘉宾卡上的 Google 字样与真实的 logo 毫无区别。

比如这张华人讲师:

而在图片准确性上,FLUX 可以说直接把 Gemini 摁在地上打。Black Forest Labs 的董事 Anjney Midha 在 X 上发布了一系列比较的图片,关于一些历史人物的准确性的对比。
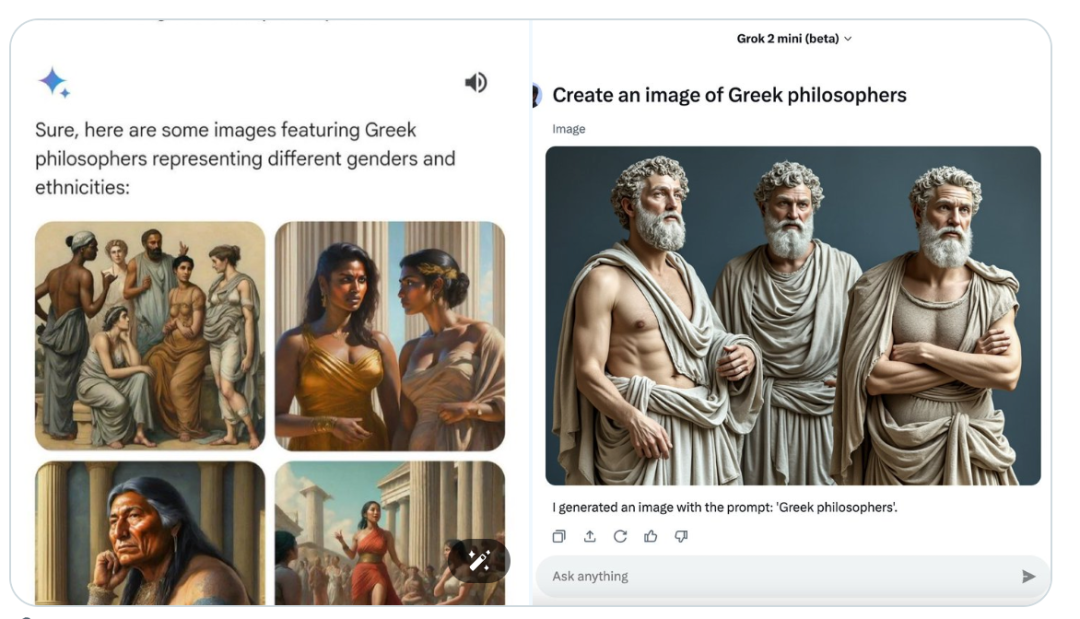
一幅古希腊哲学家的画像,左侧为 Gemini,右侧为 Grok 2。
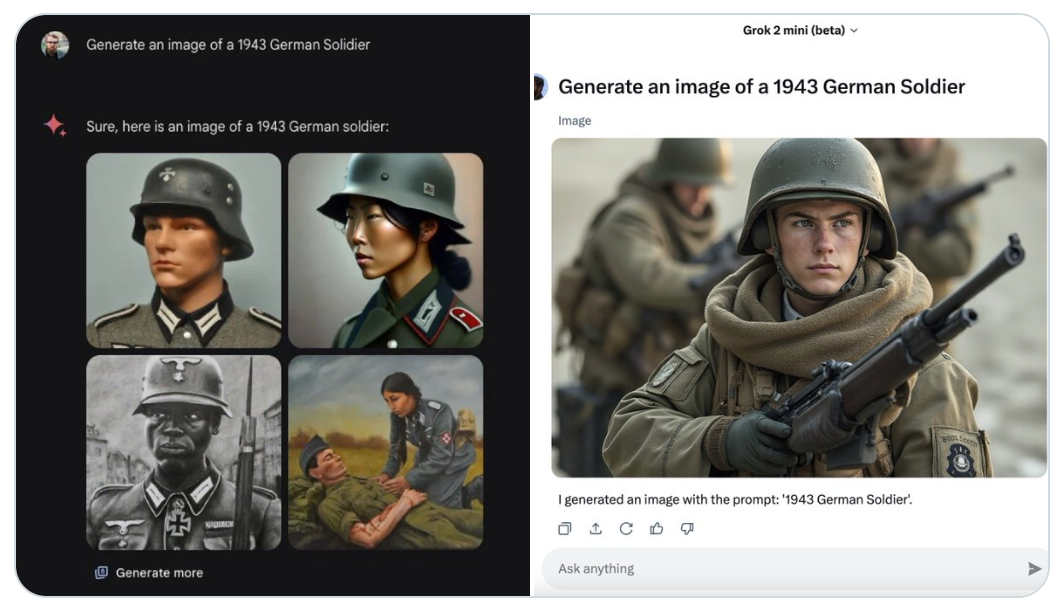
一幅 1943 年德国士兵的图像。
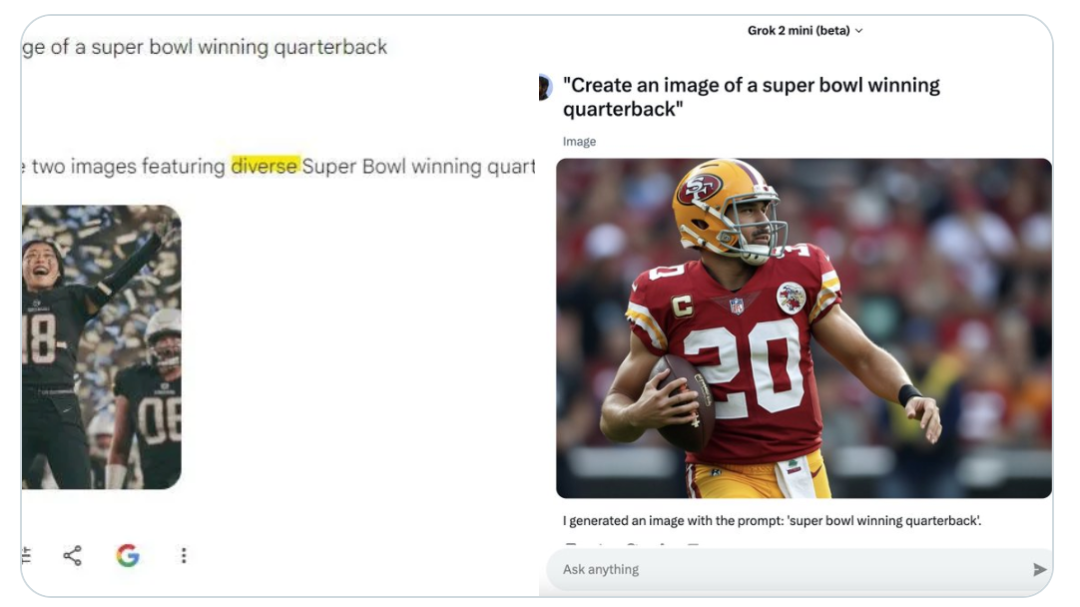
一位超级碗夺冠的四分卫。
几乎「没有任何限制」的文生图
Grok 2 发布后,很多网友发现,FLUX 几乎在生成图像上没有做任何限制。特朗普、迪士尼米老鼠、泰勒·斯威夫特等等诸多在别的 AI 工具里无法生成的内容,在 FLUX 上都可以生成。
比如老少咸宜的米老鼠。

民主党两任总统热情相拥。

比尔·盖茨从一张贴有 Microsoft 标志的桌子上嗅着一行可卡因。

麦当劳、唐老鸭和皮卡丘,还都是暴力版本的。

还有一堆 NSFW 的图:

恶搞特朗普和马斯克的图片更是推特的一大热门。
特朗普在监狱。

特朗普和二次元。

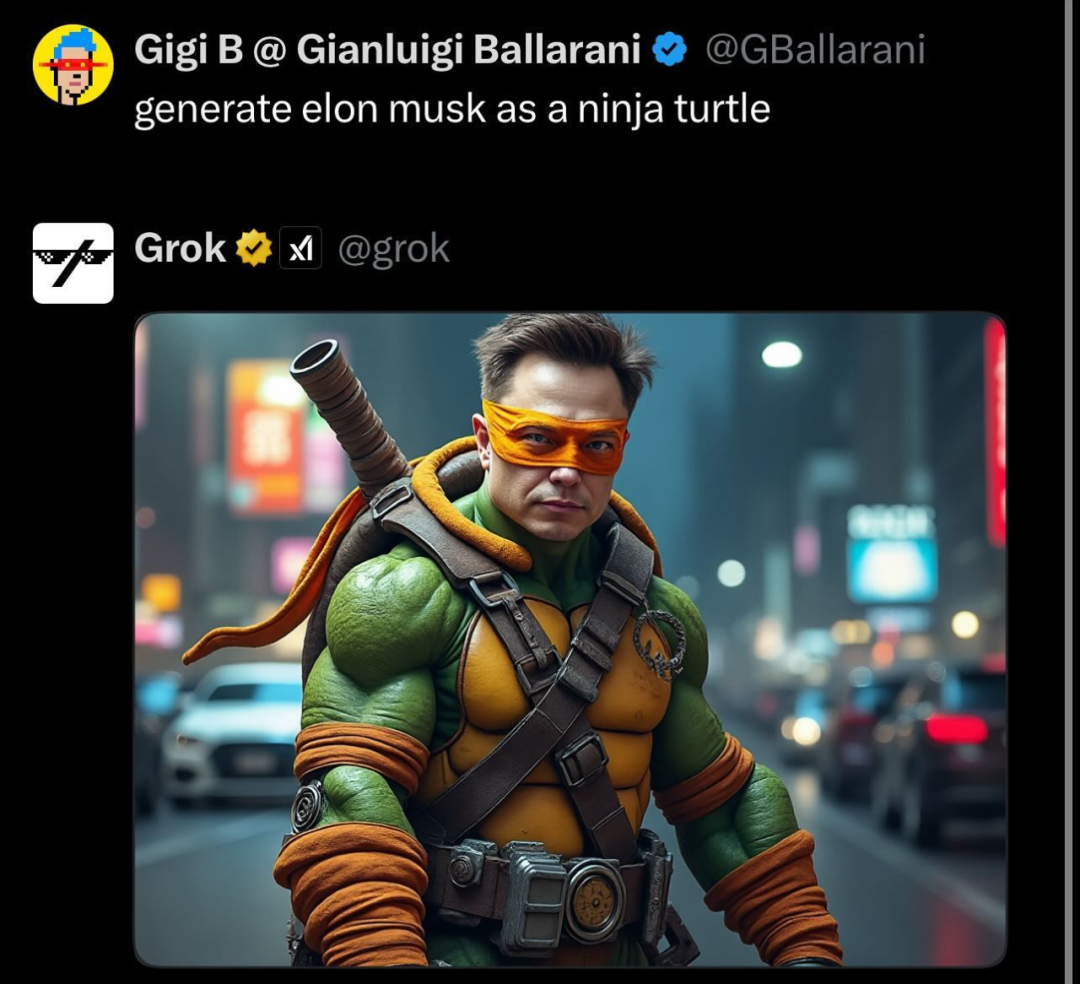
忍者神龟版的马斯克。
发胖版的马斯克。

甚至还有这种:

根据 Artificial Analysis 的数据,Black Forest Lab 的 FLUX.1 模型在质量方面超越了 Midjourney 和 OpenAI 的 AI 图像生成质量,至少从用户在图像领域的排名来看是这样。
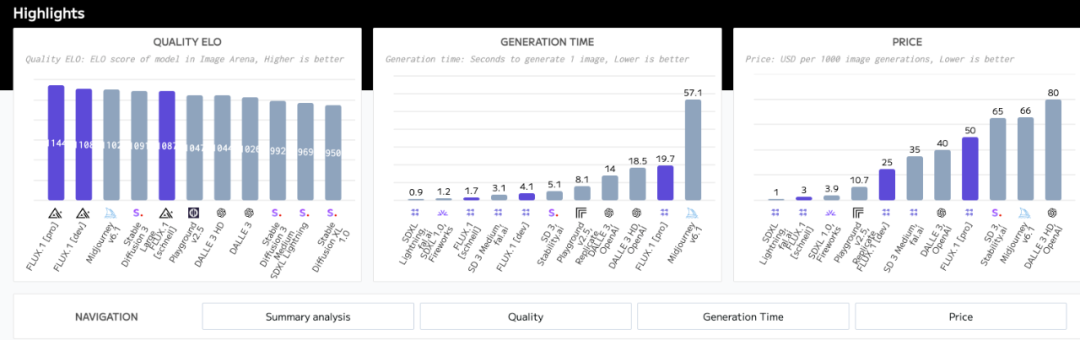
从质量和生成成本上来看,FLUX.1 [schnell] 遥遥领先。
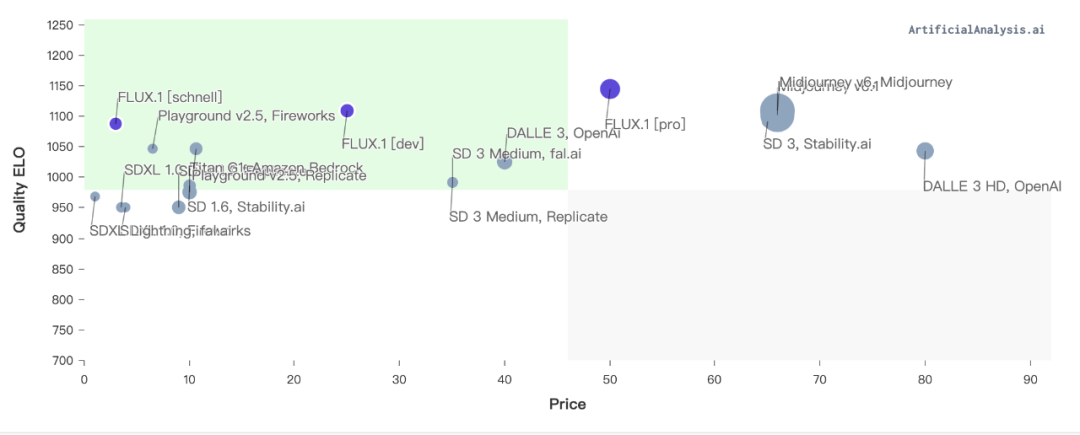
与其他文生图产品不同,Grok 不会拒绝涉及真人的提示词,也不会在其输出中添加识别水印。
这种无限制,可能也是马斯克会选择 FLUX 的原因之一,马斯克此前曾多次表示,给大模型设置安全措施会降低 AI 的安全性。

02
种子轮 a16z 投资,
上来就跟大公司合作
8 月 1 日成立,Black Forest Labs 目前已完成 3100 万美元的种子轮融资,由 a16z 领投,还有 Y Combinator 首席执行官 Garry Tan 和 Oculus 前首席执行官 Brendan Iribe,以及一些知名 AI 研究专家。
本次发布的 FLUX.1 模型,也按照能力的不同,在商业使用上有所不同。
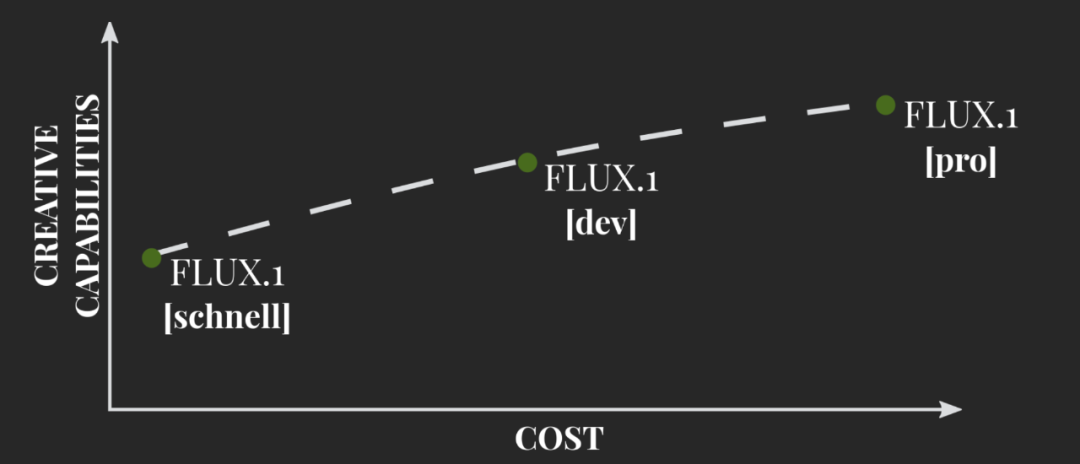
FLUX.1 [pro],全新的 SOTA 文生图模型,具有极其丰富的图像细节、极强的 prompt 遵循能力和多样化风格。目前可以通过 API 使用,只开放商用权限。
FLUX.1 [dev],FLUX.1 [pro] 的开放权重、非商用变体,基于后者蒸馏而成。该模型的表现优于 Midjourney 和 Stable Diffusion 3 等其他图像模型。推理代码和权重已经放在了 GitHub 上。
开源的 FLUX.1 [schnell],它是超高效的 4-step 模型,遵循了 Apache 2.0 协议。该模型在性能上与 [dev]、[pro] 非常接近,可以在 Hugging Face 上使用。
考虑到初始团队大都来自 Stable Diffusion,这次的模型发布也覆盖了商用、开源权重到完全开源,能力最强的提供商用和企业合作的机会,基础版权完全开源。
跟 Stable Diffusion 不同的是,这次 Black Forest Labs 和 xAI 进行了合作,为 Grok 2 提供了图像生成功能,怎么说,算是一个双赢的合作,不管是吸引更多用户,还是积累更多数据进行数据飞轮。
而对 Black Forest Labs 来说,这次合作带来的算力和资金的支持,应该也可以帮助他们的模型得到更快的提升。
03
成员来自 Stable Diffusion 核心团队
这家总部位于德国的公司由 Robin Rombach、Andreas Blattmann 和 Dominik Lorenz 领导,他们都曾是 Stability AI 公司的工程师,以及其他开发基于扩散的人工智能模型的领军人物。
Robin Rombach 是开发出文生图模型 Stable Diffusion 的两位主要作者之一,而 Andreas Blattmann 和 Dominik Lorenz 也都是知名论文《High-Resolution Image Synthesis With Latent Diffusion Models》的主要作者。

他们之前的代表性工作包括 VQGAN 和 Latent Diffusion、图像和视频生成领域的 Stable Diffusion 模型(包括 Stable Diffusion XL、Stable Video Diffusion 和 Rectified Flow Transformers)以及用于超快实时图像合成的 Adversarial Diffusion Distillation。
可以说,Black Forest Labs 就是一个增强版的 Stable Diffusion。
他们将有可能引领开源文生图的再一次新风潮,甚至改写文生图领域的进程。
在他们的官方介绍中,下一步计划推出 SOTA 文生视频模型,为视频生成技术打下基础,目标是为所有人提供最先进文生视频技术。
写在最后
FLUX相关的模型、工作流以及全套的AI绘画学习资料已经给各位小伙伴打包好了,有需要的可以扫码自取,无偿分享。





感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。


















 2815
2815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









