






文章使用的AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。
当我们使用Stable-Diffusion生成图片后,若是想要修改或新增某些细节,如果使用文生图或图生图去抽卡生成图片,那么能生成出满意图片的概率就比较小了。但我们可以使用图生图种的局部重绘功能,通过这个功能我们可以轻松的调整画面中部分画面内容和细节。
我们启动Stable-Diffusion-WebUI界面,点击图生图就可以看到局部重绘功能。
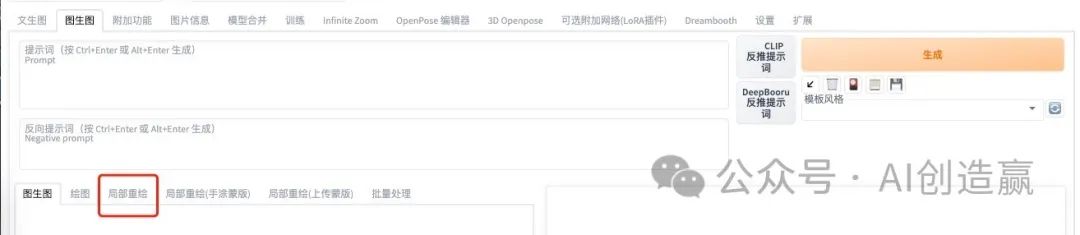
首先介绍一下局部重绘中的功能和使用:
1、缩放方式:若原图与设置尺寸不一致时,选择拉伸、裁切、填充会有不同的效果。
2、蒙版模糊:重绘蒙版内容就是重新画被涂掉的部分、重绘非蒙版内容就是重新画没有涂掉的部分
3、蒙版蒙住的内容:这4个选项差异不大,但是不同原图有不同效果,生成图片时需要自行尝试。
4、重绘区域:仅画蒙版(涂黑的区域)或是整个图片;(这里根据不同的重绘内容尝试选择)
5、仅蒙版模式的边缘预留像素:蒙版边缘与原图交接处的像素,可以让新生成的内容与原图更好的融合在一起(一般25-35就行)
其他设置基于与文生图内操作一致,选择采样方式、迭代步数等,这里建议在使用局部重绘时,要选择与原图一致的设置,从而可以确保重绘效果。

我们点击上传图片后,会看到在图片右上边显示3个功能项,叉叉是删除图像;圆形是撤回涂抹的步骤;画笔可以调整粗细,然后使用画笔在图片上把需要重新绘制的区域涂上;
这里特别说明一下,画笔涂抹后会显示黑色,黑色遮盖的区域是蒙版内容;未被黑色遮盖的就是非蒙版内容;

说了这么多的介绍,我们通过实操来看看局部重绘到底是什么效果;
我们上传原图后可以使用Stable-Diffusion-WebUI的图片信息功能读取图片的关键词等信息,然后发送到图生图-
局部重绘里即可;这里原图的关键词是:a girl, blue hair, Pink eyes, white shirt with green tie,
red Pleated skirt, white leather boots
这次我们想要把人物的衣服进行修改,那么就把衣服部分涂抹掉。把提示词中的white shirt修改为sailor
suit,其他提示词不做改变。采样方式、尺寸都与原图保持一致,蒙版模式选择重绘蒙版内容,蒙版蒙住的内容选择原图,重绘区域选择仅蒙版
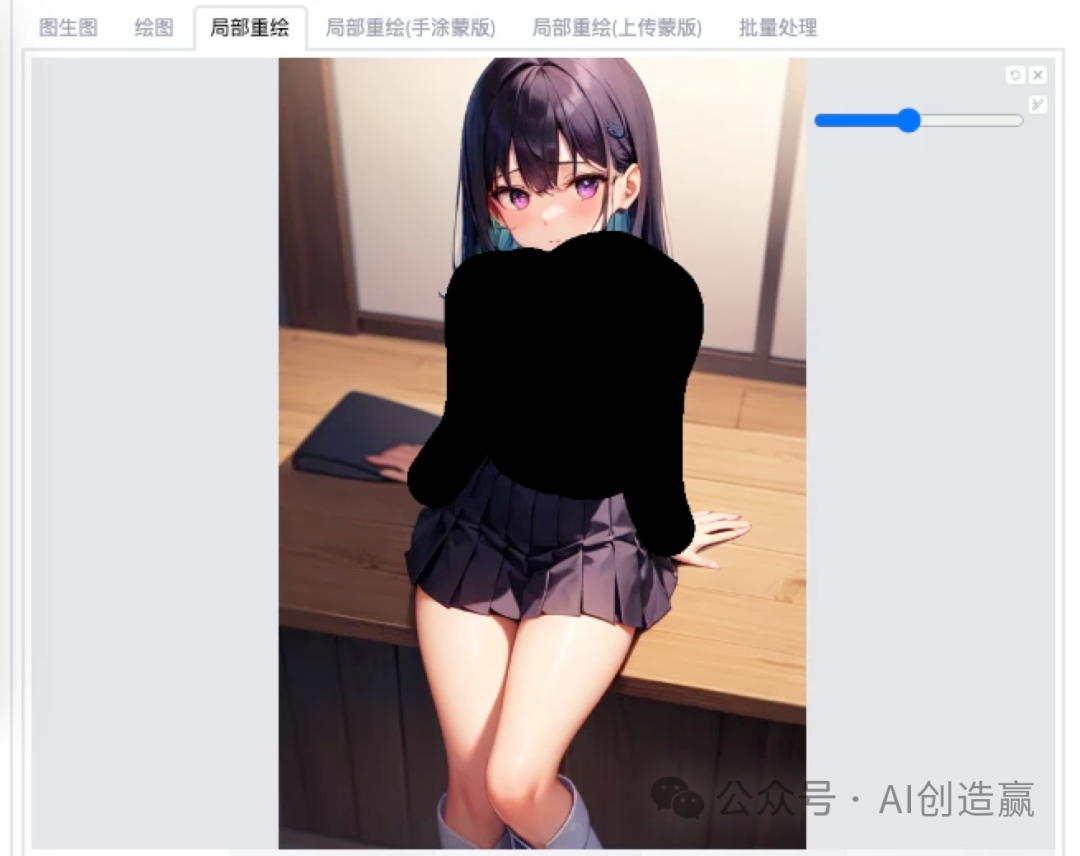
重绘后可以看到人物的衣服确实发生的改变,而且人物其余的部分并未有变化;

当然不仅仅可以换衣服,我们也可以通过局部重绘让人物有异瞳的画面。只需要用画笔遮盖住一只眼睛,然后把pink eyes修改为yellow
eyes。这里重绘区域可以考虑选择全图,由于眼睛占比小,局部重绘可能会让眼睛与原画面不匹配。

可以看到,局部重绘后,我们获得了异瞳的人物,并且画面其余部分并未有任何异常的变化。

除开改变画面中原有内容之外,也可以添加一些新的元素到图片中,例如我们人物有一个猫耳朵,那么用画笔把希望有猫耳朵的区域涂抹一下,然后在关键词里输入“Cat
ears”,点击生成图片。

OK,我们得到了有猫耳朵的人物了。

局部重绘可以帮助大家不断对画作进行迭代和修改,最终达到理想的画面效果。
最后
如果你是真正有耐心想花功夫学一门技术去改变现状,我可以把这套AI教程无偿分享给你,包含了AIGC资料包括AIGC入门学习思维导图、AIGC工具安装包、精品AIGC学习书籍手册、AI绘画视频教程、AIGC实战学习等。
这份完整版的AIGC资料我已经打包好,长按下方二维码,即可免费领取!

【AIGC所有方向的学习路线思维导图】
【AIGC工具库】

【精品AIGC学习书籍手册】
【AI绘画视频合集】
这份完整版的AIGC资料我已经打包好,长按下方二维码,即可免费领取!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









