







核心思想:1、MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结果,这种思想来源于日常生活与工作时的经验,同样也完全适合技术领域。
2、MapReduce作为一种分布式计算模型,它主要用于解决海量数据的计算问题。使用MapReduce操作海量数据时,每个MapReduce程序被初始化为一个工作任务,每个工作任务可以分为Map和Reduce两个阶段。
一、MapReduce编程实例——词频统计实现
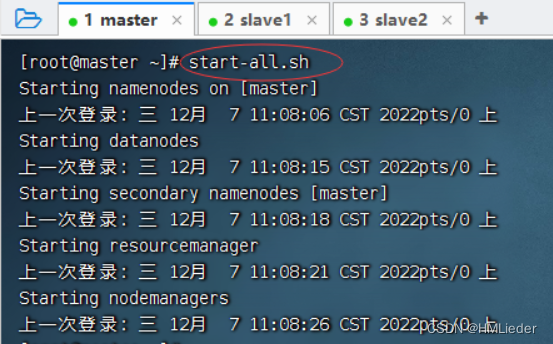
1、启动Hadoop
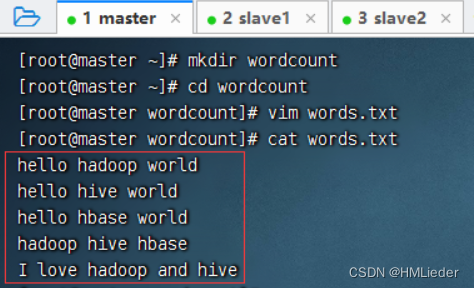
2、准备数据文件
在虚拟机上创建文本文件,创建wordcount目录,在里面创建words.txt文件。
上传文件到HDFS指定目录
创建/wordcount/input目录,执行命令:hdfs dfs -mkdir -p /wordcount/input

将文本文件words.txt,上传到HDFS的/wordcount/input目录

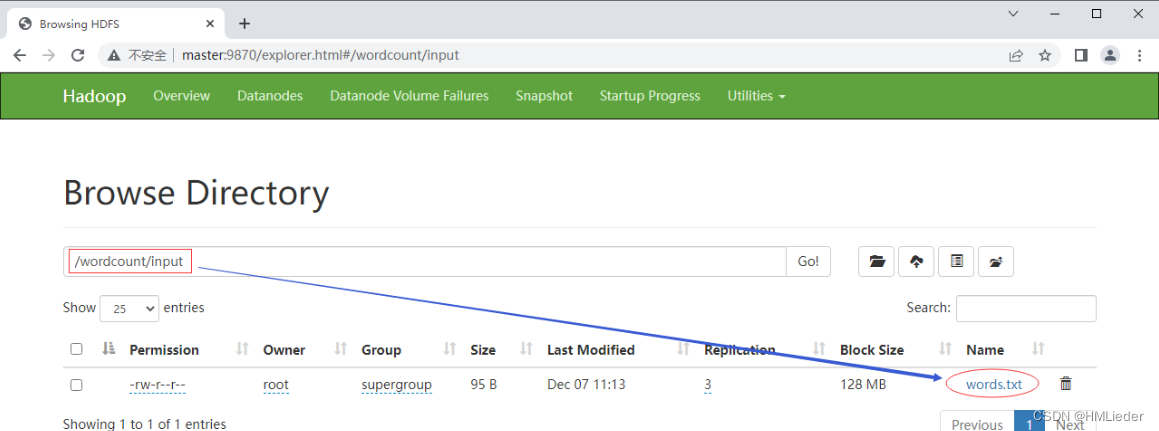
在Hadoop WebUI界面上查看上传的文件
二、创建Maven项目
创建Maven项目 - MRWordCount
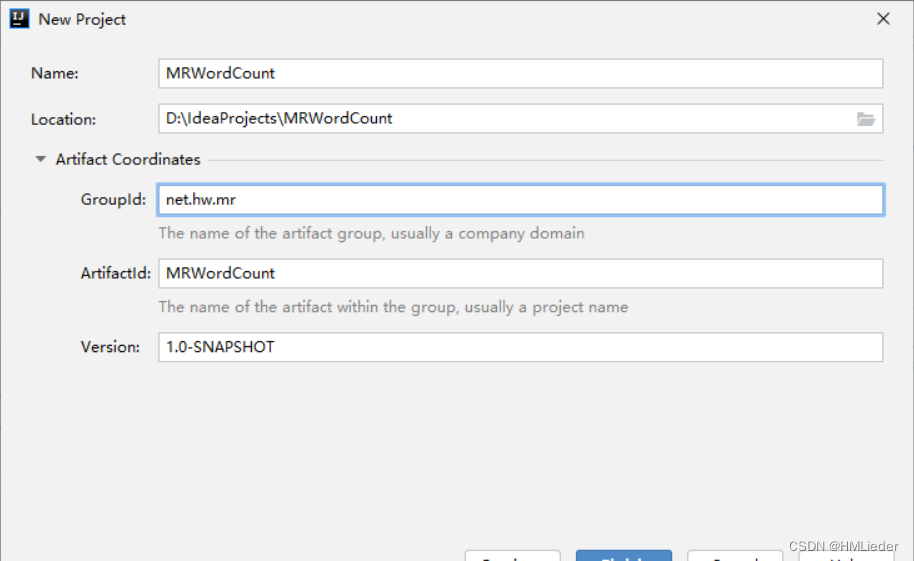
注:该截图来自授课老师。
单击【Finish】按钮
添加相关依赖
在pom.xml文件里添加hadoop和junit依赖
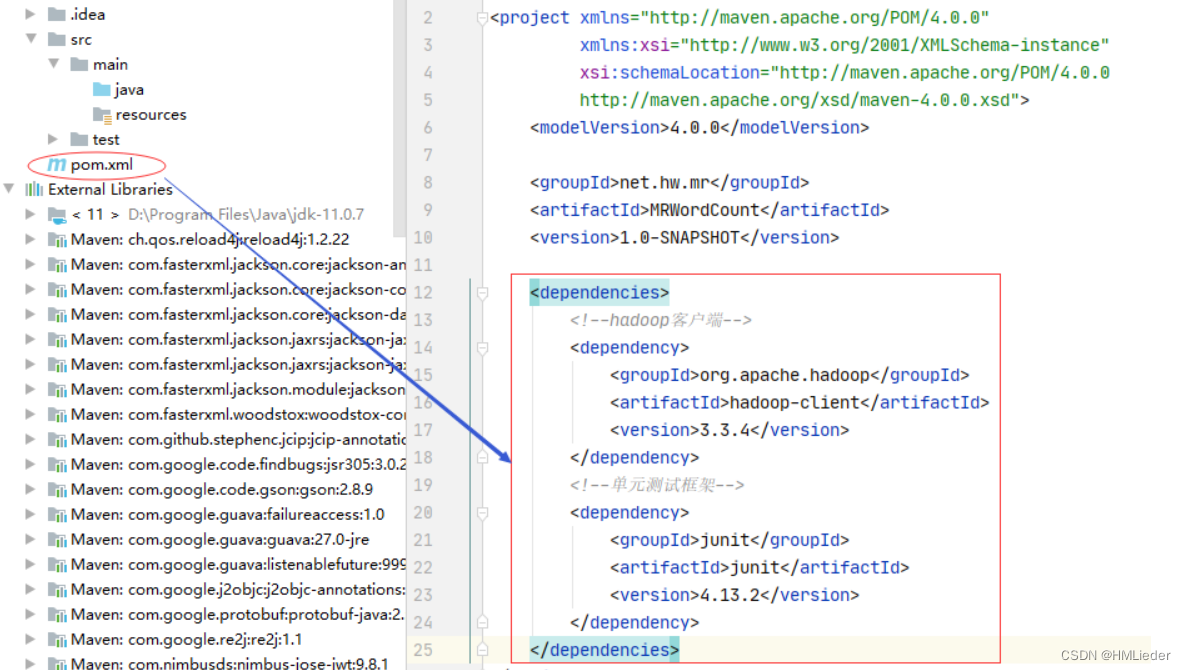
代码:<dependencies>
<!--hadoop客户端-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.4</version>
</dependency>
<!--单元测试框架-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
</dependency>
</dependencies>
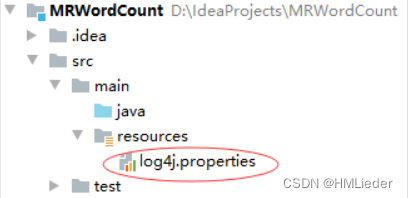
三、创建日志属性文件
在resources目录里创建log4j.properties文件
代码:log4j.rootLogger=INFO, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/wordcount.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
四、创建词频统计映射器类
创建net.hw.mr包,在包里创建W
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3921
3921











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









