






6.1 CUDA 的内存组织简介
目录
现代计算机的内存中往往存在一种组织结构(hierarchy)。在这种结构中,含有多种类型的内存,每种内存分别具有不同的容量和延迟(latency)。
一般来说,延迟低(速度高)的内存容量小,延迟高(速度低)的内存容量大。当前被处理的数据一般存放与低延迟、低容量的内存中;当前没有被处理但之后将要被处理的大量数据一般存放于高延迟、高容量的内存中。相对于不用分级的内存,用这种分级的内存可以降低延迟,提高计算效率。
和 CPU 一样,GPU 中也有内存分级的设计。相对于CPU编程来说,CUDA编程模型向程序员提供更多的控制权。
下面的表和图列出了 CUDA 中的几种内存和他们的主要特征:
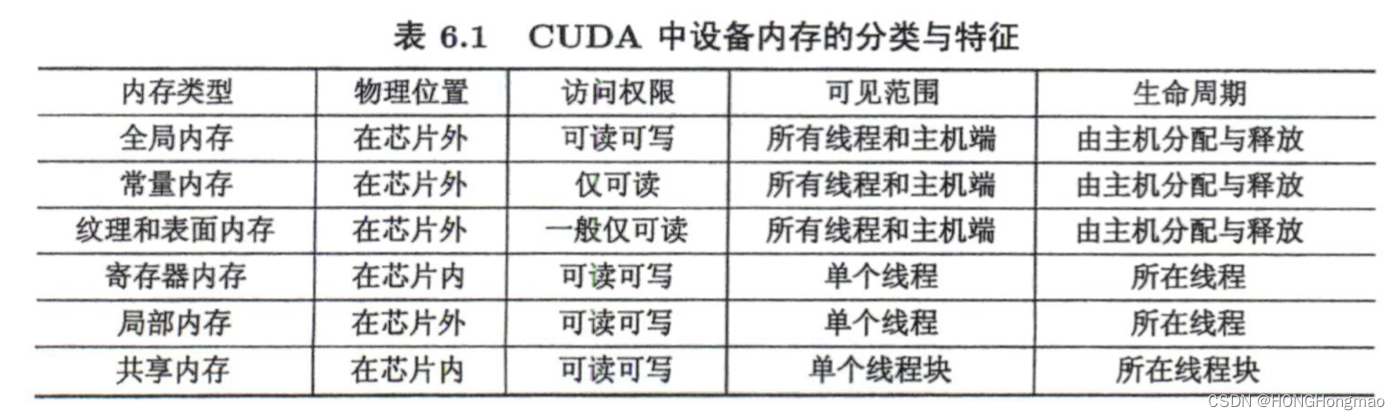
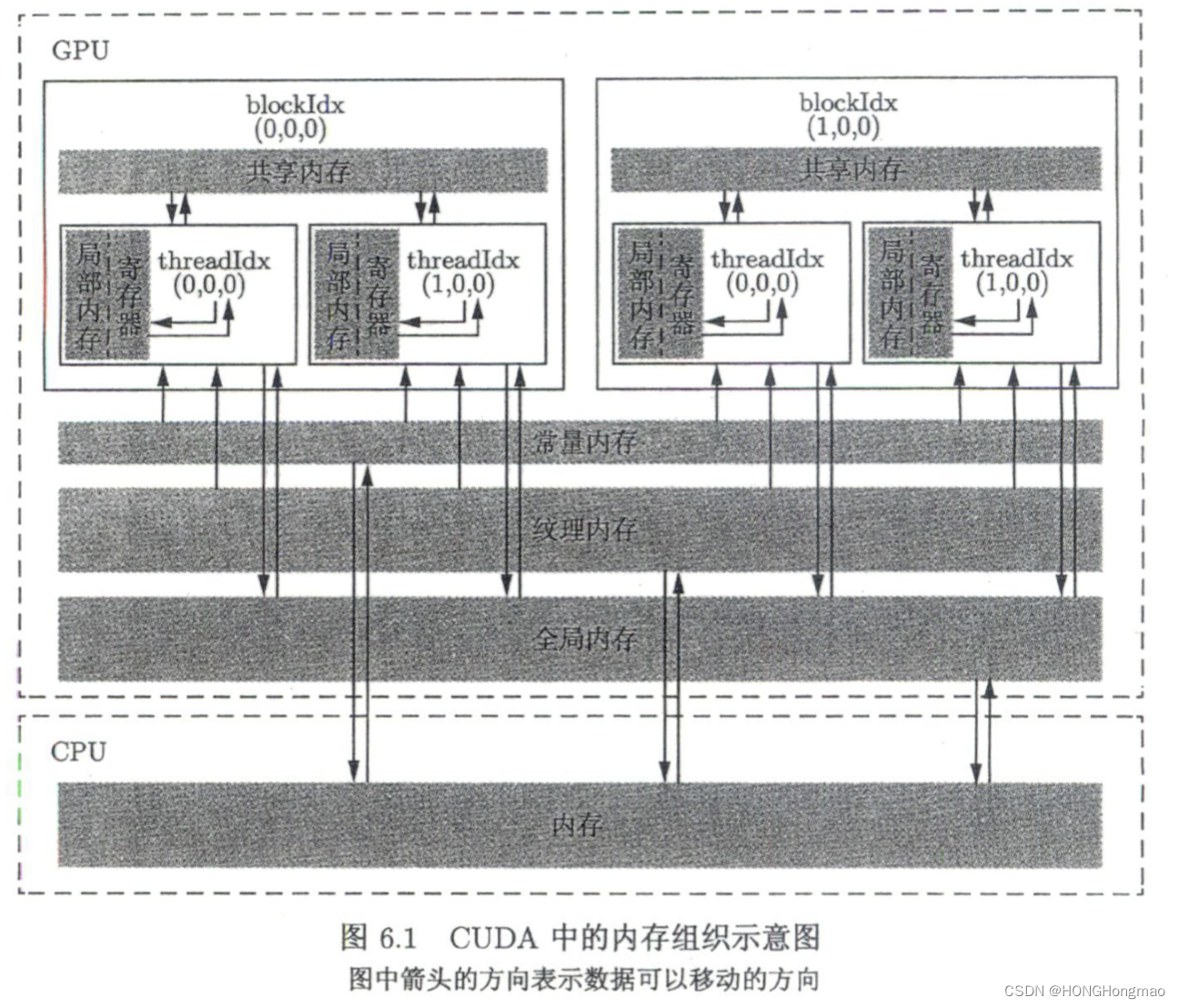
CUDA 中不同类型的内存
6.2.1 全局内存
这里“全局内存”(global memory)的含义是核函数中所有线程都能够访问其中的数据。在数组相加的例子中,指针d_x,d_y和d_z 都是指向全局内存的。由于全局内存没有存放在 GPU 芯片上,所以有较高的延迟和较低的访问速度。
全局内存的主要角色是为核函数提供数据,并在主机与设备、设备与设备之间传递数据。
我们用cudaMalloc() 函数为全局内存变量分配设备内存。然后,可以直接在核函数中访问分配的内存,改变其中的数据值。
以及全局内存的拷贝:

全局内存对整个网格的所有线程可见。也就是说,—个网格的所有线程都可以访问(读或写)传入核函数的设备指针所指向的全局内存中的全部数据。
全局内存的生命周期(lifetime)不是由核函数决定的,而是由主机端决定的。在数组相加的例子中,指针d_x,d_y和d_z 所指向的全局内存缓冲区的生命周期就是从主机端用cudaMalloc() 对它们分配内存开始,到主机端用 cudaFree() 释放他们的内存结束。
静态全局内存变量:

6.2.2 常量内存
常量内存是有常量缓存的全局内存,数量有限,仅有 64KB。它的可见范围和生命周期与全局内存一样。不同的是,常量内存仅可读、不可写。由于有缓存,常量内存的访问速度比全局内存高,但得到高访问速度的前提是一个线程束中的线程(一个线程块中相邻的 32 个线程)要读取相同的常量内存数据。
6.2.3 纹理内存和表面内存
纹理内存(texturememory)和表面内存(surfacememory)类似于常量内存,也是一种具有缓存的全局内存,有相同的可见范围和生命周期,而且一般仅可读 (表面内存也可写)。
6.2.4 寄存器
在核函数中定义的不加任何限定符的变量一般来说就存放与寄存器(register)中。核函数中定义的不加任何限定符的数组有可能存放与寄存器中,但也有可能存放于局部内存中。另外,以前提到过的各种内建变量,如gridDim、blockDim、blockIdx、threadIdx 及 warpSize 都保存在特殊的寄存器中。在核函数中访问这些内建变量是很高效的。
寄存器变量仅仅被—个线程可见。也就是说,每一个线程都有一个变量 n 的副本。虽然在核函数的代码中用了同一个变量名,但是不同的线程中该寄存器变量的值是可以不同的。每个线程都只能对它的副本进行读写。寄存器的生命周期也与所属线程的生命周期一致,从定义它开始,到线程消失时结束。
寄存器内存在芯片上(on-chip),是所有内存中访问速度最高的,但是其数量很有限。下表是几个不同计算能力的 GPU 中与寄存器和后面要介绍的共享内存有关的技术指标:

6.2.5 局部内存
我们还没有用过局部内存(local memory),但从用法上看,局部内存和寄存器几乎一样。核函数中定义的不加任何限定符的变量有可能在寄存器中,也有可能在局部内存中。寄存器中放不下的变量,以及索引值不能在编译时就确定的数组,都有可能放在局部内存中。这种判断是由编译器自动做的。
虽然局部内存在用法上类似于寄存器,但从硬件来看,局部内存只是全局内存的一部分。所以,局部内存的延迟也很高。每个线程最多能使用高达512KB的局部内存,但使用过多会降低程序的性能。
6.2.6 共享内存
共享内存和寄存器类似,存在于芯片上,具有仅次于寄存器的读写速度,数量也有限。见上面那张图。
同于寄存器的是,共享内存对整个线程块可见,其生命周期也与整个线程块一致。
也就是说,每个线程块拥有一个共享内存变量的副本。共享内存变量的值在不同的线程块中可以不同。一个线程块中的所有线程都可以访问该线程块的共享内存变量副本,但是不能访问其他线程块的共享内存变量副本。共享内存的主要作用是减少对全局内存的访问,或者改善对全局内存的访问模式。
6.2.7 L1 和 L2 缓存
6.3 SM 及其占有率
6.3.1 SM 的构成
—个GPU是由多个SM构成的。—个SM包含如下资源:

6.3.2 SM 的占有率
因为 SM 中的各种计算资源是有限的,那么有些情况下一个 SM 中驻留的线程数目就有可能达不到理想的最大值。此时,我们说该SM的占有率小于100%。获得100%的占有率并不是获得高性能的必要或充分条件,但一般来说,要尽量让 SM的占有率不小于某个值,如25%,才有可能获得较高的性能。
要分析 SM 的理论占有率(theoretical occupancy),还需要知道两个指标:
- 一个 SM 中最多能拥有的线程块的个数为 N b = 16 N_b =16 Nb=16 (开普勒架构和图灵架构) 或者 N b = 32 N_b=32 Nb=32(麦克斯韦架构、帕斯卡架构和伏特架构)。
- 一个 SM 中最多能拥有的线程个数为 N t = 2048 N_t=2048 Nt=2048(从开普勒架构到伏特架构)或者 N t = 1024 N_t=1024 Nt=1024(图灵架构)。
下面,在并行规模足够大(即核函数执行配置中定义的总线程数足够多)的前提下分几种情况来分析SM的理论占有率:
- 寄存器和共享内存使用量很少的情况。此时,SM 的占有率完全由执行配置中的线程块大小决定。关于线程块大小,读者也许注意到我们之前总是用128。 这是因为,SM中线程的执行是以线程束为单位的,所以最好将线程块大小取为线 程束大小(32个线程)的整数倍。例如,假设将线程块大小定义为100,那么一个线程块中将有3个完整的线程束(一共96个线程)和一个不完整的线程束(只有 4个线程)。在执行核函数中的指令时,不完整的线程束花的时间和完整的线程束花的时间一样,这就无形中浪费了计算资源。所以,建议将线程块大小取为32的整数倍。在该前提下,任何不小于 N t / N b N_t/N_b Nt/Nb 而且能整除 N t N_t Nt 的线程块大小都能得到 100% 的占有率。
- 有限的寄存器数量对占有率的约束情况。我们只针对表6.2(上面那个表)中列出的几个计算能力进行分析,读者可类似地分析其他未列出的计算能力。对于表6.2中列出的所有计算能力,一个SM最多能使用的寄存器个数为64K(64×1024)。除图灵架构外,如果我们希望在一个SM中驻留最多的线程(2048个),核函数中的每个线程最多只能用32个寄存器。当每个线程所用寄存器个数大于64时,SM的占有率将小于50%;当每个线程所用寄存器个数大于128时,SM的占有率将小于 25%。对于图灵架构,同样的占有率允许使用更多的寄存器。
- 有限的共享内存对占有率的约束情况。因为共享内存的数量随着计算能力的上升没有显著的变化规律,所以我们这里仅针对计算能力 3.5 进行分析,对其他计算能力可以类似地分析。如果线程块大小为 128,那么每个 SM 要激活 16 个线程块才能有 2048 个线程,达到100% 的占有率。此时,一个线程块最多能使用 3KB 的共享内存。在不改变线程块大小的情况下,要达到 50% 的占有率,一个线 程块最多能使用 6KB 的共享内存;要达到 25% 的占有率,一个线程块最多能使用 12KB 的共享内存。如果一个线程块使用了超过 48KB 的共享内存,会直接导致核函数无法运行。对其他线程块大小可类似地分析。
以上单独分析了三种情况。一般情况下,需要综合以上三点分析。
6.4 用 CUDA 运行时 API 函数查询设备
略















 2393
2393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









