







1.1 高效公式
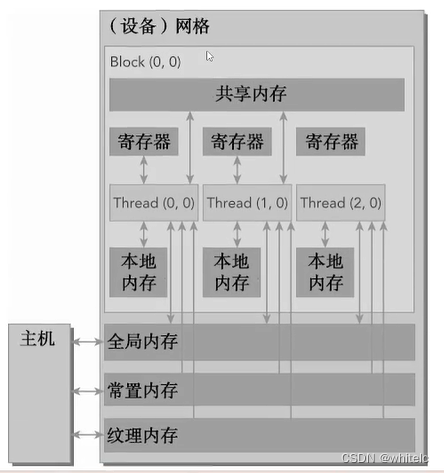
 要么增大数据量,要么减少每个线程的内存(每个线程读取的数据量变少,每个线程的读取数据的速度变快(转变存储方式,对读取慢的地方做优化–合并全局内存))
要么增大数据量,要么减少每个线程的内存(每个线程读取的数据量变少,每个线程的读取数据的速度变快(转变存储方式,对读取慢的地方做优化–合并全局内存))
1.2 合并全局内存
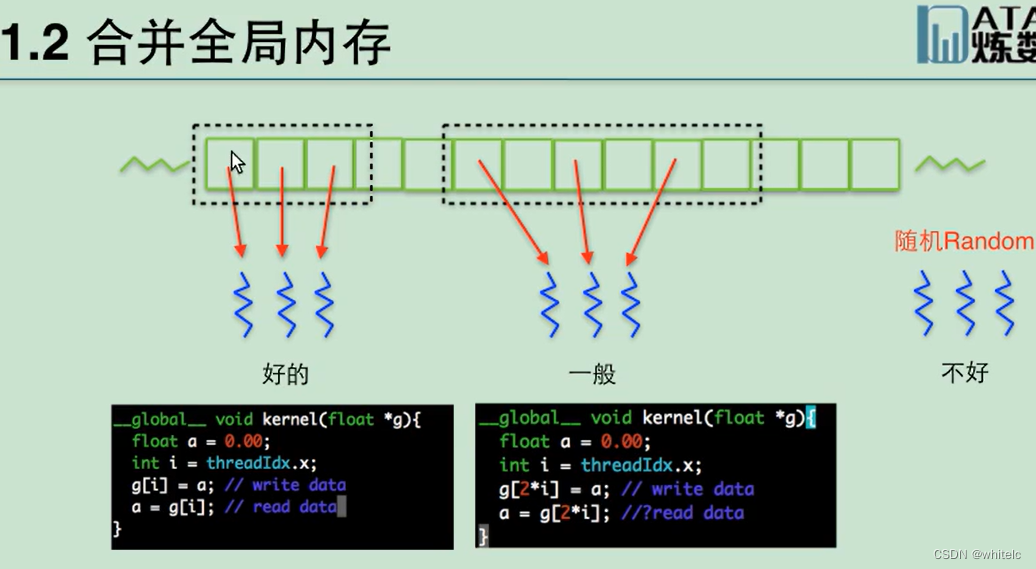 一个线程读取一个数据,读取数据的方式有三种
一个线程读取一个数据,读取数据的方式有三种
- 数组是连续的,按照顺序读----
- 固定步长读取,比如每隔两个读一个
- 随机读取,在任意位置开始获取数据
下面代码显示,假设g是全局内存,threadIdx.x是当前的线程号,意思是,当前线程号是多少就读取这个对应的数组,线程号连续所以读取的数据是连续的。
尽量让总的数据量和线程号挂钩去读取
1.3 避免线程发散
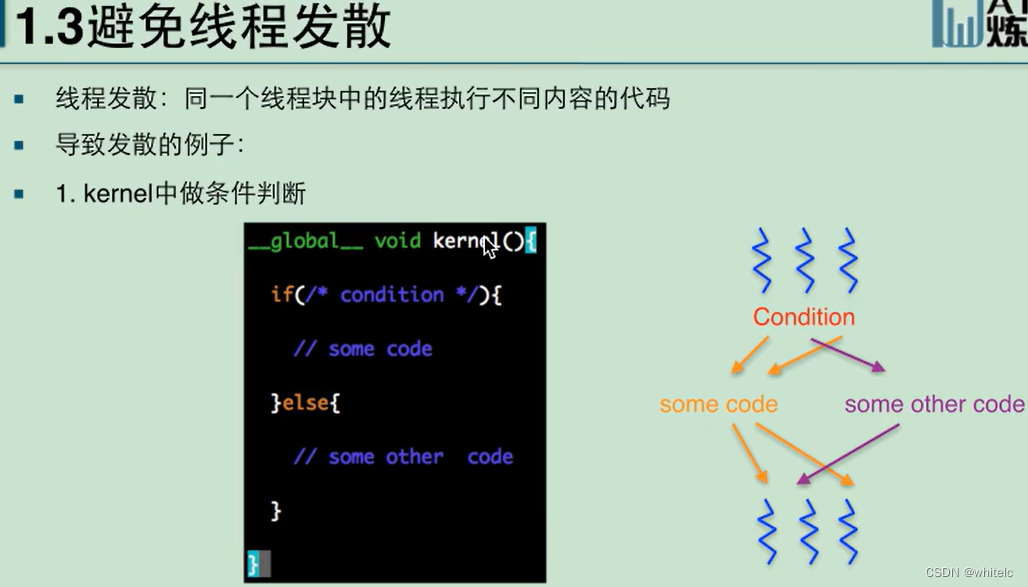
一个kernel中的所有线程都跑完才叫做运行结束,决定最后速度的是,执行时间最慢的那个

每个线程执行的次数不一样,一号线程执行一次loop,二号线程执行两次loop.
2 cuda各种内存的代码使用
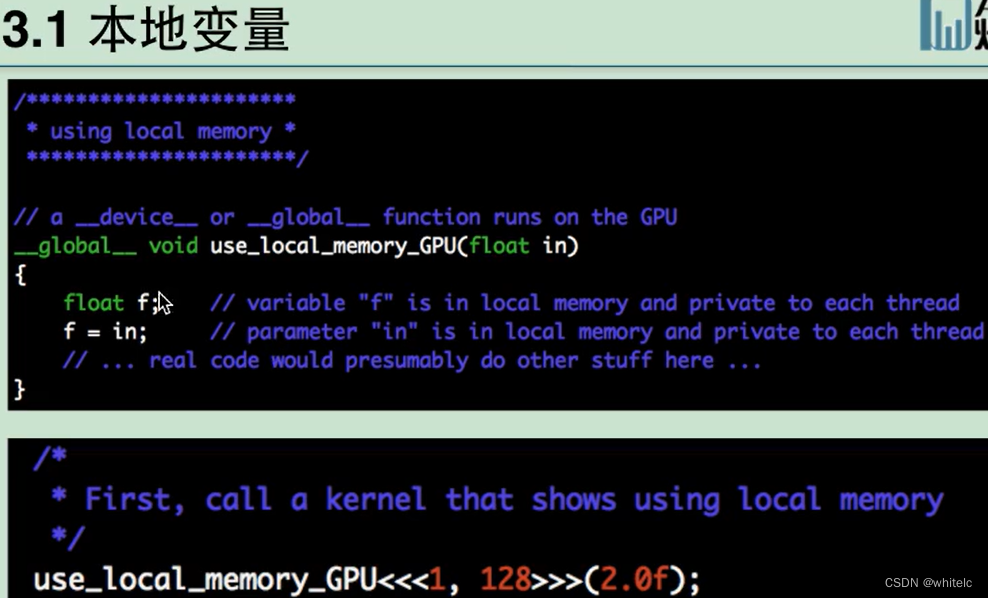
本地变量,直接在kernel里面定义初始化,使用
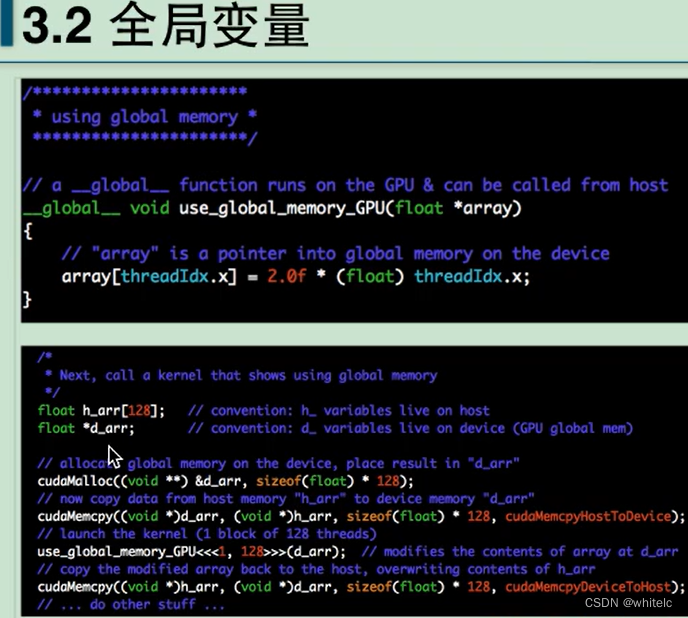
全局变量都是使用指针去执行的,必须进行数据copy
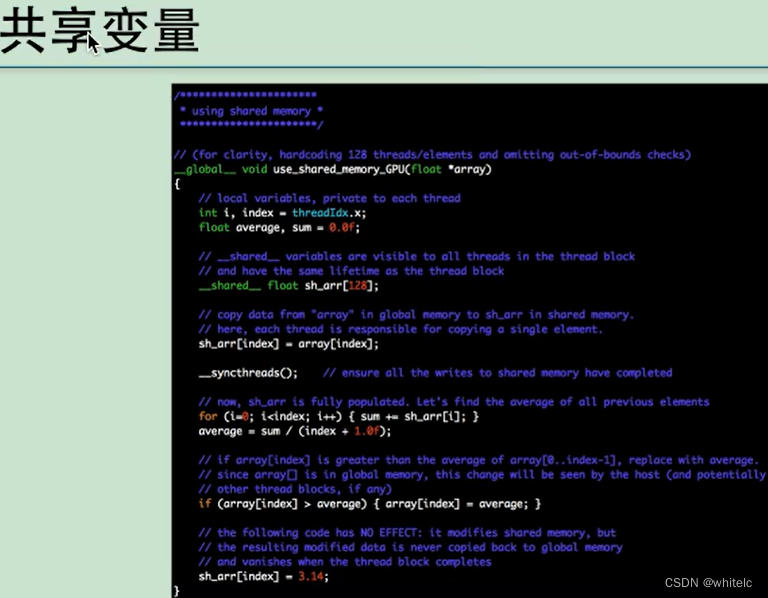
共享变量,大家都往里面写或者读就会有时间差的问题,must要进行同步,大家都往里面写,写完了以后加同步,在这里kernel的加载可以有三个参数,第三个参数是共享内存的大小
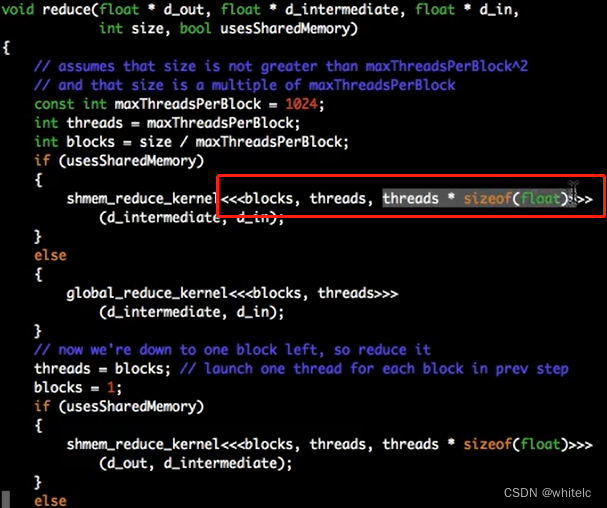
同步操作
4.1 原子操作

会拖慢整体的速度,原本是并行的程序,突然使用原子操作使得其中某一种步骤,变成了串行的,在读取或者写入某些线程的时候是需要排队的,因为同一时间只能有一个线程进行操作
 某一个在往里面写的时候,别的可能在往里面读,就会出错
某一个在往里面写的时候,别的可能在往里面读,就会出错
- 自己设置同步,大家都写完了然后再进行下一步
- 原子操作,就是把加法的地方,写成,atomicAdd(& g[i], 1); 函数去做加法
4.1 同步函数


跨block的数据读取的时候,需要用到。
4.3 cpu/gpu同步

在host去调用
并行化高效策略(1)
5.1 归约 Reduce–多个输入一个输出
实例:求和:1+2+3+4+……
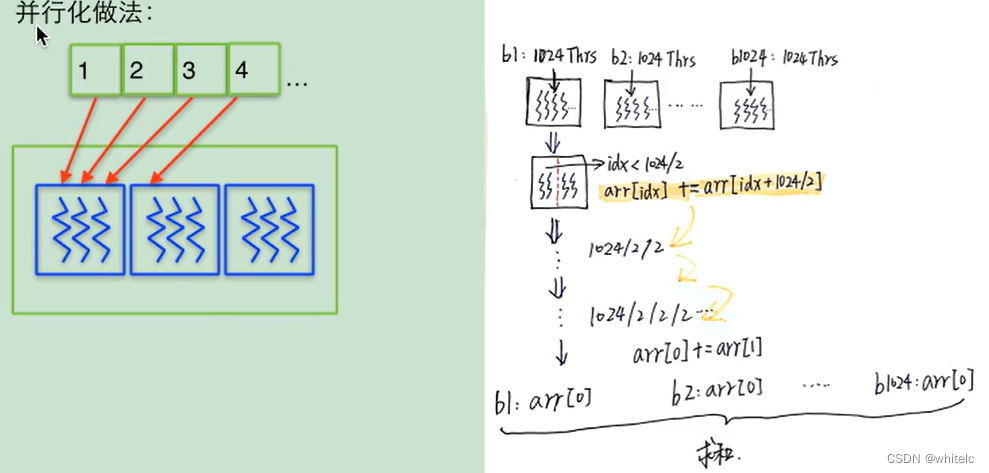
多个数据(输入)放在长度为n的数组里面,把内存中的每一个数都分配到一条线程里面去计算,
比如有1024个线程块,每个线程块里有1024个线程,
- 每个块里面的线程 都对应读取数字
- 随机抽取一个线程块,获取每个线程在块里面的编号,idx
- 1024个线程进入循环,循环中if idx<1024/2
Arr[idx]=arr[idx]+arr[idx+1024/2]
Arr[idx]+=arr[idx+1024/2]
就相当于 线程块在做对折,第0 个线程数值加第512个线程数值,1+513,2+514……
全部做完以后 if idx<1024/2/2
继续做对折,一直到 arr[0]+=arr[1];
循环时,线程号大于if条件内的不产生加法运算。 - 把所有线程块的结果,存放在一个线程块的1024条线程里面去,再进行对折相加
1. 假设有1024个block,每个block里面有1024条线程,每条线程读取对应的一条数据
2. 对于其中的一个块,就是每个线程要进入一个循环,每条线程在这个块里面对应的idx(索引),二分,1024个数据进行对折,第0个跟第512个加起来,1+513,2+514……
3. 512个数据进行对折,第0个跟第256个加起来,1+257,2+258……
4. 重复操作,最后会得到,第0个数据加第一个数据
5. 这样得到一个1024大小块的求和结果,把所有的块的做同样操作,得到1024个和
6. 把这1024个和放在一个大小为1024的块里重复2-4
数据以成倍的方式,把另外一半的数据加过来
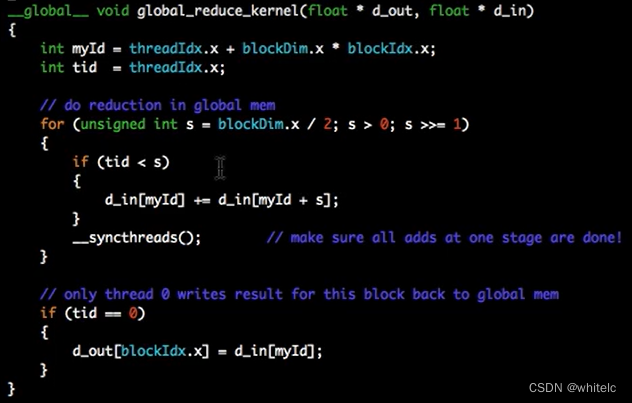
myId-----1024个block,每个block里面有1024条线程,所有的线程里面,对应的线程号,为了读取对应全局内存
tid---------当前线程块的线程号,为了判断,二分,越小循环的次数会越多,s会取到512,256,128……
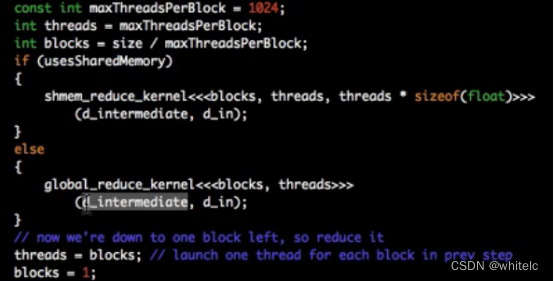
这一步即我得到了一个中间值,有每一个block的结果,再放进去1个块(block=1)的线程里面(threads=blocks);
最后得到输出结果 d_out

对应上面操作的5 6 两步
11. 这样得到一个1024大小块的求和结果,把所有的块的做同样操作,得到1024个和
12. 把这1024个和放在一个大小为1024的块里重复2-4

共享内存数据 速度快
首先定义共享内存,就是在每一个block里面设置一个共享内存(线程),不断往共享内存中读、写数据

当前定义了共享内存数组
全局内存d_in对应的线程块赋值给共享内存(sdata[tid]=d_in[myid])
再也不需要读取全局内存了 所以才快了 最后再复制回结果即可。
5.2 扫描 Scan–多对多,多少个输入就有多少个输出
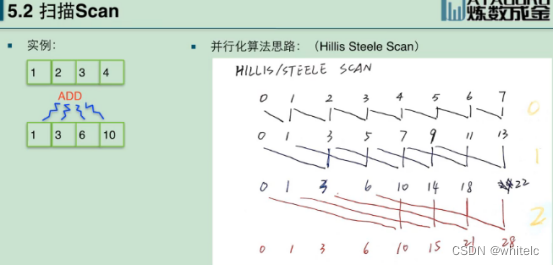
前面的数据不断进行累加时候
分为3步,
- 把与自身 间隔为1(2的0次方)的数 与自身相加,结果记录下来
- 对第一次的结果 与自身 间隔为2(2的1次方)的数 与自身相加,没有对应项 相加的,就直接写下来放在原来位置
- 对第二次的结果,与自身 间隔为4(2的2次方)的数 与自身相加,没有对应项的 ,写在原来位置 得到最后的输出结果。
把每一个数据看作一个线程,每一个数值经历了三次循环。当它不符合一定条件时,循环并不增加(不做加法),横向作为,横向数组全部循环完毕(用上一次的结果),所以需要设置同步屏障
不断的更新输出的,所以可以把第一次的初始值,作为输出值 d-out=d-in,先做一次同步屏蔽,
接下来循环(以间隔为标准)大于0,表示有东西可加,
比如11+7数组的第7个位置+第5个位置,要保证第5个是7,而不能是更新之后的,所以会先赋值给out

https://www.bilibili.com/video/BV15Y4y1F7tE?p=15&spm_id_from=pageDriver&vd_source=fa871d85ec6ff3a94c2b3af862650e05
看的这个课做的笔记















 613
613











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









