







2020.04.09英伟达就FasterTransformer 2.0做了一个线上的公开课分享,由于老板的要求,我也报名听课了。做了一份听课笔记,分享一下。这里的优化主要是由底层的CUDA和cuBLAS编程支撑的,这个代码我是没有去看的,也是看不懂的。听课笔记主要就宏观的原理上进行一个总结。
目录
一、FasterTransformer 1.0版关于encoder的优化
2.1 FasterTransformer 2.0 新增加功能介绍
2.4 Decoder和decoding能够带来什么样的加速效果
一、FasterTransformer 1.0版关于encoder的优化
英伟达开源的 FasterTransformer 1.0版本中,针对BERT中的 Transformer Encoder进行了优化和加速,经过高度优化之后,降低了用户使用transformer编码的时延。主要做的工作是:
- 为了减少kernel调用次数,将除了矩阵乘法的kernel都尽可能合并
- 针对大batch单独进行了kernel优化
- 支持选择最优的矩阵乘法
- 在使用FP16时使用half2类型,达到half两倍的访存带宽和计算吞吐
- 优化gelu、softmax、layernorm的实现以及选用rsqrt等
这里的kernel定义主要是指在tensorflow里的概念是operation的计算实现,在cuda里是执行一个线程的函数,也是一次计算,只不过tensorflow的更加宏观些。每次tensorflow执行一个operation,都要调用对应的OpKernel,试想一个通过TF实现的transformer,有将近60个operation,计算一次要执行60次上述过程,进行频繁的GPU调度和显存读写。
优化原理:
Faster Transformer只用了14个kernel就完成了原来将近60个kernel的计算逻辑。这其中8个kernel是通过调用cuBLAS接口计算矩阵乘法(绿色框),其余6个是自定义kernel (蓝色框),把kernel合并减少了。。
Faster Transformer还优化了前向计算中耗时较高的GELU激活函数,Layer Normalization以及SoftMax等操作。比如利用warp shuffle实现高效的矩阵按行求和操作, 将1/sqrtf计算替换为rsqrtf函数,以及power (x, 3.0) 替换为x * x * x等。
计算流程图:
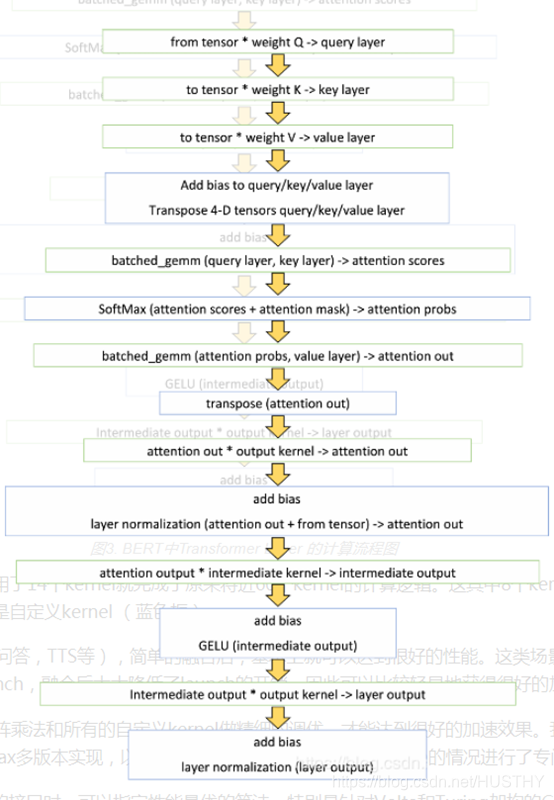
二、FasterTransformer 2.0版相关优化
2.1 FasterTransformer 2.0 新增加功能介绍
Transformer的计算量很大,推理的时延是不太适合工业界的需求的。Bert中使用了很多层的Transformer结构。Transformer结构由encoder和decoder。单纯的encoder架构优化后性能很好了。下图中encoder和decoder的一些对比,在encoder-decoder的架构中,decoder使用了大概90%的时间。

另外Decoder解码的过程一次只能解码一个字,因此做解码的过程中就需要多次使用到decoder,这过程就对GPU就不是很友善。
经过测试后,发现仅仅优化decoder,效果是不太好的。因此提出了一个更大的模块就是decoding,对decoding也做优化,可以进一步提高效率。


decoding的流程中,会在while循环中多次调用decoder。首先就需要对decoder进行优化,然后对其他的例如beamsearch等进行优化。
2.2如何针对decoder和decoding进行优化

Kernels太小了,又需要很多次kernel操作,导致GPU有很多时间限制的。
CPU启动Kernels、GPU计算Kernels。
图中的蓝色方块就是GPU计算的耗时,白色方块就是闲置时间。
TensorFlow中的LayerNorm就需要很多个kernel来完成,如下图:
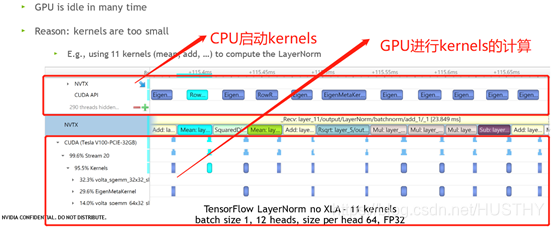
怎么来优化呢?优化思路如下:
- 矩阵计算单独拿出来,因为矩阵运算使用了cuBLAS——高度优化的库,很高效。
- 把非矩阵计算的部分kernels尽可能的合并在一起。
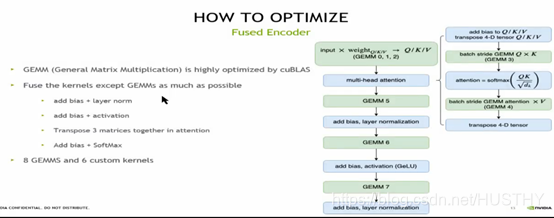
24个kernel减少到14个kernel;单层的Transformer就优化了。
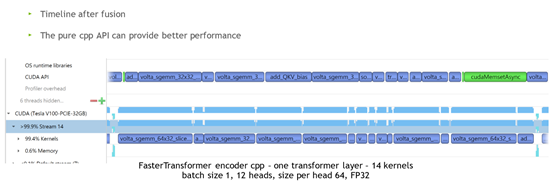
上图结果显示,kernel是变大了,但是GPU还是有一些闲置,但是已经得到了很好的优化了,闲置明显减少了。
Decoder的优化同样的是和上述思想类似
需要70个kernels——优化后减少到16个
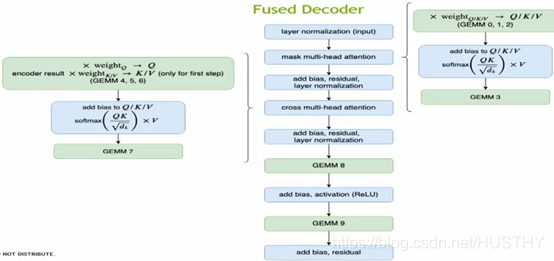
其他的一些优化:
Decoding中需要使用beam search,针对这个优化——topk——GPU并行计算,Fuse the “add bias” and “SoftMax” in beam search。

Half2 使得每次读写2个FP16这样就是的速度加快
特定的kernels,比如softMax FP32和FP16是不一样的要单独拿出。
2.3如何使用decoder和decoding
源码中有具体的例子和指导,详情略。
2.4 Decoder和decoding能够带来什么样的加速效果
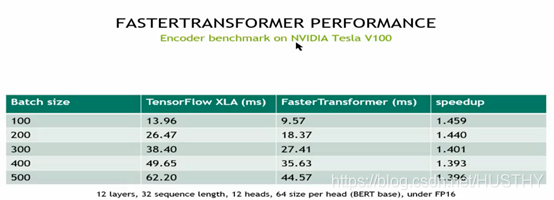
仅仅使用encoder的优化。。提速1.5倍。当然还有一个规律也就是batch_size越小,提升效果越好。
Decoder翻译任务
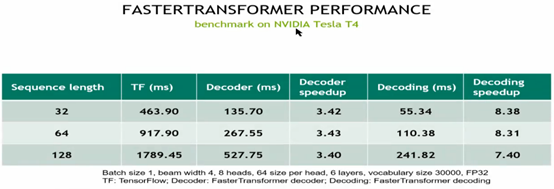
首先batch_size =1,效果如上:单独使用decoder和decoding,提速分别为3.5倍和8.3倍
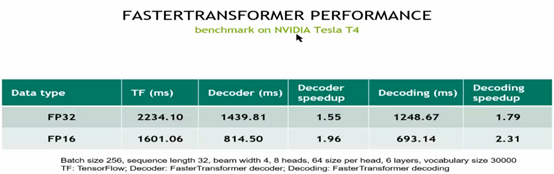
FP32数据类型比FP16加速更好!F16可能会丢失一点精度。
总结:
优化原理——Kernels融合
也就是batch_size小的时候,kernel变小了,kernel的数量变多了。主要的耗时就是CPU启动——CPU调用一个函数——而等待的时间导致效率很慢,启动以后,GPU然后再计算;另外GPU的计算不是很长。当kernels很多的时候,CPU启动的时间就很多了,导致整体的时间变长;所以融合后就减少CPU启动kernels的时间,从而提升了效率。
Kernels的大小一般都是和batch_size的大小正相关的,batch_size越小kernel就越小,反之就越大。
目前fastTransformer都是基于TensorFlow来进行优化的,未来是支持pytorch OP的 ,也就是说pytorch中以后也可以使用这个优化的。

















 1239
1239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









