






本文想对比一下多机多卡(多机之间没有采用高速网络通信设备互联仅仅采用普通的以太网网卡带宽100M/S)训练和单机多卡训练的速度对比,为将来有可能去实践多机多卡大模型训练奠定一定的基础。
一、单机多卡
采用LLaMA-Factory来进行单机多卡训练比较简单,更详细的过程就赘述了,这里仅仅给出一个训练命令和训练耗时截图,以方便和多机多卡配置进行对比。
训练命令
CUDA_VISIBLE_DEVICES=1,2,3,5 llamafactory-cli train train_lora_config/qwen2vl_lora_sft.yaml耗时截图
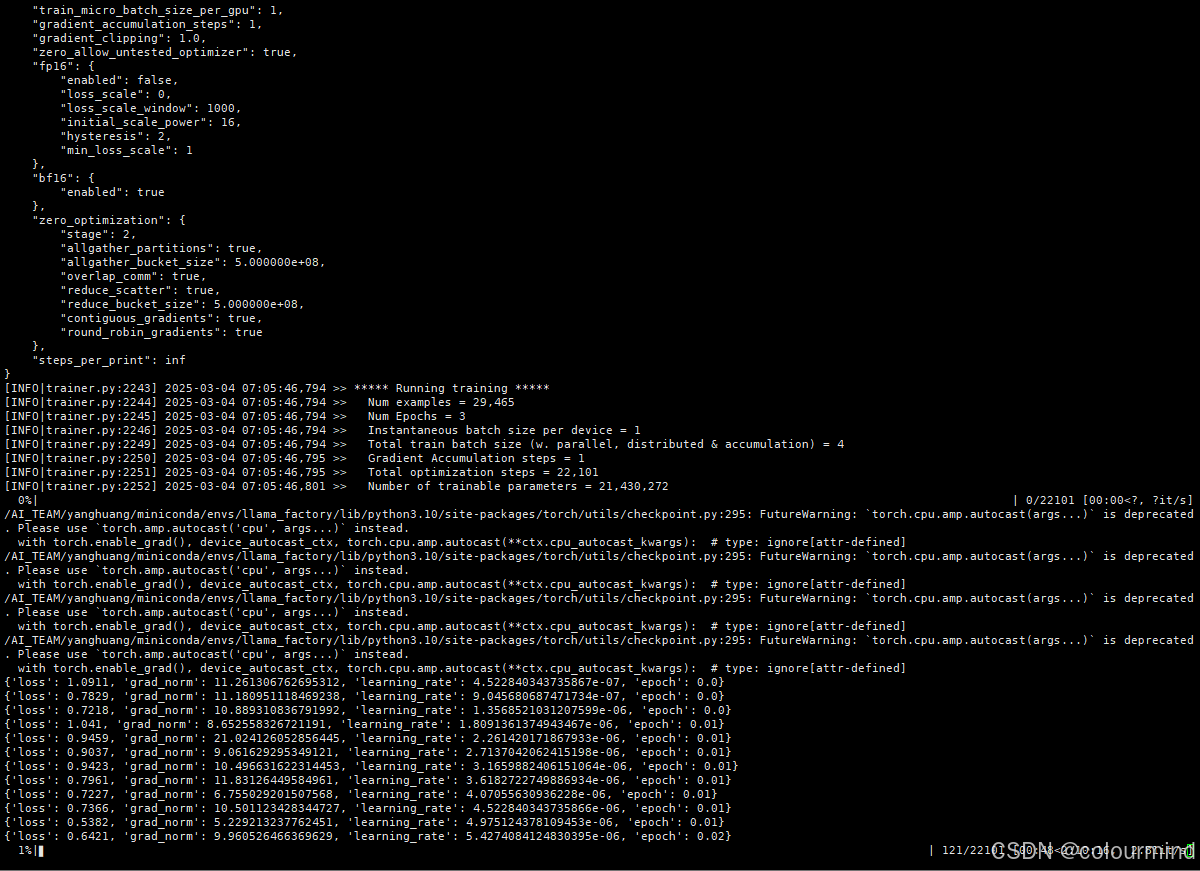
整体耗时2小时
二、多机多卡
物理机配置
两台同样配置的物理机,机器之间的网络带宽100M/s,操作系统Ubuntu 22.04.4 LTS、CPU Intel(R) Xeon(R) Silver 4314 CPU @ 2.40GHz,显卡驱动 Driver Version: 550.54.15 粗大版本cuda_12.4,都是8卡4090
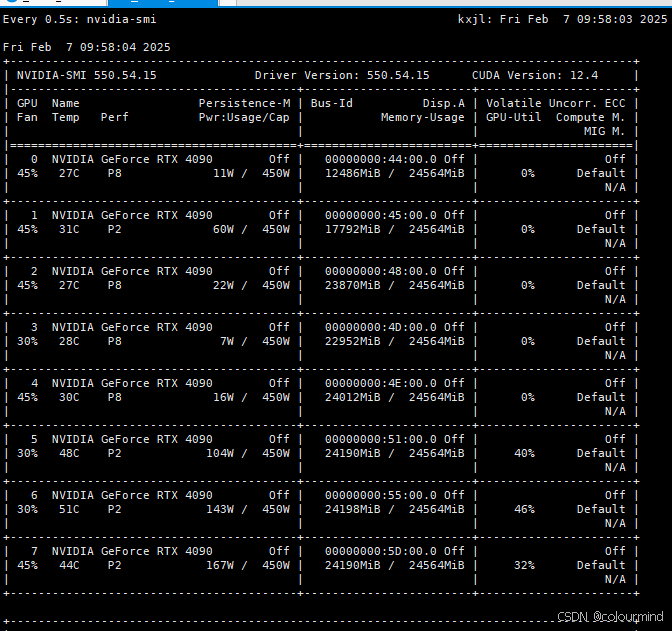
需要注意的是这两台机器之间要在一个网络集群中,保证两台服务器免密登录同时训练指定的端口也要放开不要限制,具体怎么实现这里就不详细介绍了,有很多相关资料可以参考。
训练环境构建
两台服务器上搭建完全相同的python训练环境,分布式训练采用的框架是LLaMA-Factory,可以按照官网github的教程来安装。
训练命令
这里采用的是LLaMA-Factory这个库来构建的训练环境和训练代码,因此训练的启动可以使用llamafactory-cli脚手架来启动训练,具体命令如下:
master服务器
CUDA_VISIBLE_DEVICES=6,7 NCCL_DEBUG=INFO NCCL_SOCKET_IFNAME=ens1f0 FORCE_TORCHRUN=1 NNODES=2 RANK=0 MASTER_ADDR=ip_master MASTER_PORT=29500 llamafactory-cli train train_lora_config/qwen2vl_lora_sft.yaml
slave服务器
CUDA_VISIBLE_DEVICES=1,6 NCCL_DEBUG=INFO NCCL_SOCKET_IFNAME=ens1f0 FORCE_TORCHRUN=1 NNODES=2 RANK=1 MASTER_ADDR=ip_master MASTER_PORT=29500 llamafactory-cli train train_lora_config/qwen2vl_lora_sft.yaml注意两个启动命令不同的部分就只有RANK,主服务器rank=0,从服务器rank=1;由于我们的物理机上没有安装高速网卡进行通信,只能使用以太网来进行低速通信,启动命令中NCCL_SOCKET_IFNAME参数的值是ens1f0,否则就会报错ncll代码默认机器之间使用高速网卡通信,没有安装通信就不能成功,训练就启动不了。做实验的时候每台机器只有6、7号这两台卡可以使用,CUDA_VISIBLE_DEVICES=6,7设置每台机器上使用的显卡。
qwen2vl_lora_sft.yaml文件中是训练超参,简单看看
### model
model_name_or_path: /data02/yanghuang/huge_models/Qwen2-VL-7B-Instruct
### method
stage: sft
do_train: true
finetuning_type: lora
lora_rank: 8
lora_alpha: 16
lora_target: k_proj,up_proj,o_proj,v_proj,q_proj,gate_proj,down_proj,embed_tokens
#lora_target: k_proj,up_proj,o_proj,v_proj,q_proj,gate_proj,down_proj,
#lora_target: all
deepspeed: examples/deepspeed/ds_z2_config.json
### dataset
dataset: meisu_img_recognize
dataset_dir: data/20250106_visionocr_meisutrain
template: qwen2_vl
cutoff_len: 1024
#max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: output/20250106_visionocr_meisutrain
logging_steps: 10
save_steps: 2000
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 1
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
### eval
#val_size: 0.1
#per_device_eval_batch_size: 1
#eval_strategy: steps
#eval_steps: 500
训练结果
以下是多机多卡的训练日志
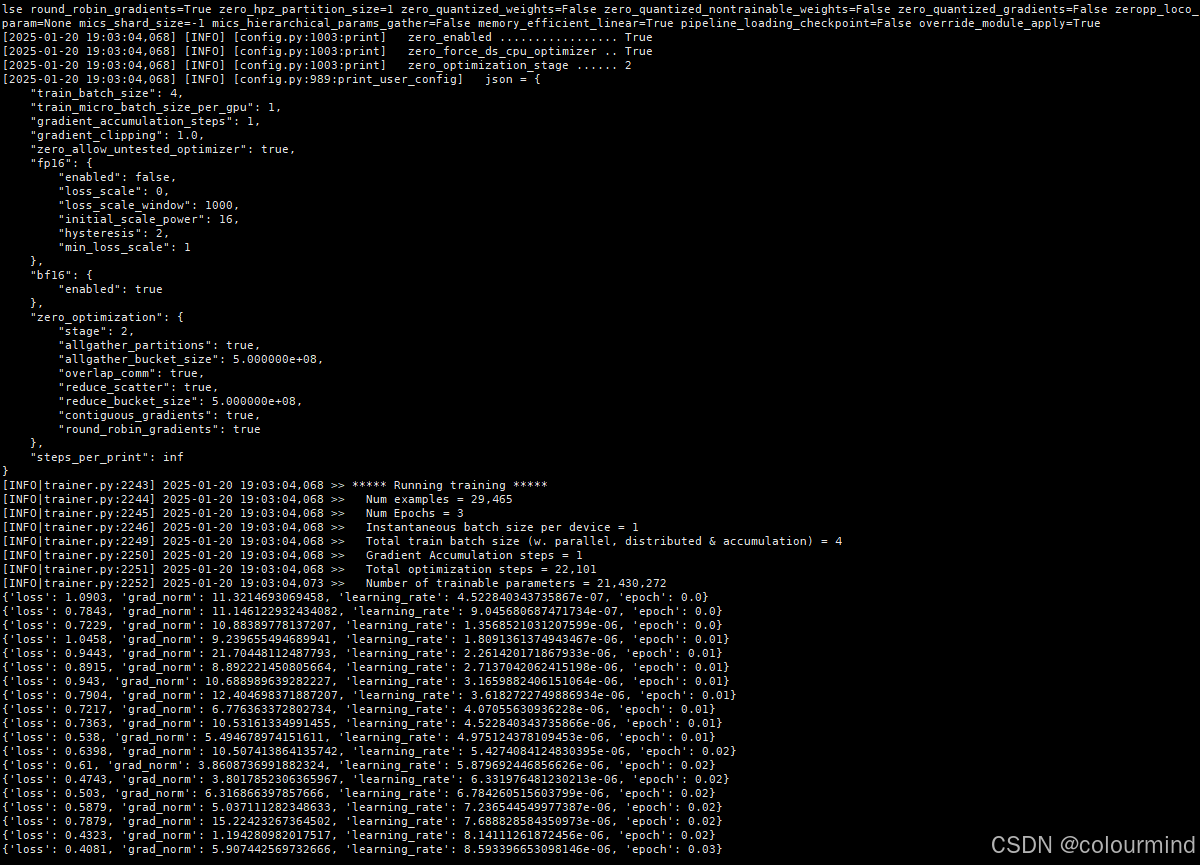
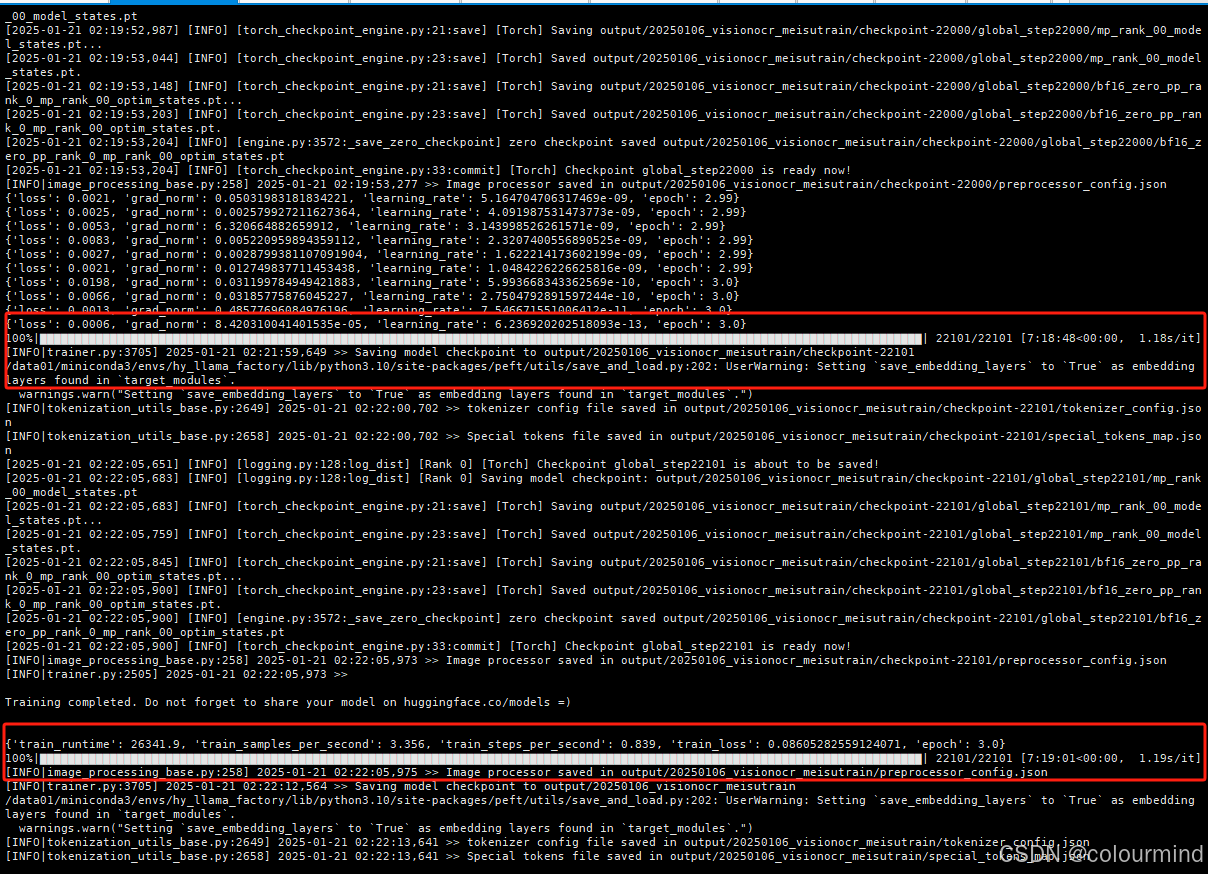
训练耗时及速度
{'train_runtime': 26341.9, 'train_samples_per_second': 3.356, 'train_steps_per_second': 0.839, 'train_loss': 0.08605282559124071, 'epoch': 3.0}
相比而言还是单机单节点更快

















 4178
4178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









