






1 Softmax标准化
Softmax是一种数学函数,通常用于将一组任意实数转换为表示概率分布的实数。其本质上是一种归一化函数,可以将一组任意的实数值转化为在[0, 1]之间的概率值,因为softmax将它们转换为0到1之间的值,所以它们可以被解释为概率。
S o f t m a x ( x i ) = e x i ∑ j = 1 k e x j Softmax(x_{i})=\frac{e^{x^{i} }}{\sum_{j=1}^{k}e^{x^{j}}} Softmax(xi)=∑j=1kexjexi
优点:
- 生成概率分布:Softmax标准化将原始分数转换为概率分布,使得每个类别的输出都可以解释为该类别的预测概率。
- 可解释性强:由于Softmax标准化的输出是概率值,因此对于分类任务,可以清晰地解释每个类别的相对重要性。
- 可微分性:Softmax函数是连续可微的,这使得它可以与梯度下降等优化算法一起使用,用于训练神经网络等模型。
缺点:
- Softmax标准化计算涉及指数运算,当输入数据量很大时,可能会导致数值稳定性问题,增加计算成本和时间。
- 类别间相关性:Softmax标准化假设各个类别之间是独立的,但实际情况下,类别之间可能存在相关性,这可能会导致Softmax标准化的输出存在一定的偏差。
- 容易受到异常值的影响:Softmax标准化对异常值敏感,因为它是基于输入数据的原始分数进行归一化的。如果输入数据中存在异常值,可能会影响Softmax标准化的输出结果。
2 Z-Score标准化
Z-Score标准化是数据处理的一种常用方法。通过它能够将不同量级的数据转化为统一量度的Z-Score分值进行比较。
Z
=
x
−
μ
σ
Z=\frac{x-\mu }{\sigma }
Z=σx−μ
式中:X为原始数据;μ为均值; σ为标准差。
优点:
- 简单,容易计算,凭借最简单的数学公式就能够计算出Z-Score并进行比较。
- 消除量级给分析带来的不便。
缺点: - 估算Z-Score需要总体的平均值与方差,这一值在真实的分析与挖掘中很难得到,大多数情况下是用样本的均值与标准差替代。
- Z-Score标准化假设数据符合正态分布,但实际上即使数据不符合正态分布,它仍然可以起到一定的标准化效果。然而,对于高度偏斜或不对称的数据分布,Z-Score标准化可能不是最佳选择。
- Z-Score消除了数据具有的实际意义,A的Z-Score与B的Z-Score与他们各自的分数不再有关系,因此Z-Score的结果只能用于比较数据间的结果,数据的真实意义还需要还原原值。
- 如果两组样本集的类型比例不一样,scale会带来bias。
3 Normalize标准化
每行的的总和加起来为一个确定数值,这里使用target_sum设为7.5


4 Log标准化
对数转换X = In(X + 1)

5 Scale标准化
对特征标准化,使得均值为0,方差为1。

6 RPKM标准化
RPKM(Reads Per Kilobase of transcript, per Million mapped reads)是常用的基因表达量标准化方法。
RPKM计算方法:
- 读取计数(Reads Count):计算每个基因的测序读取数。
- 基因长度标准化:将每个基因的读取数除以该基因的长度(以kb为单位)。这一步用于校正基因长度对读取数的影响。
- 测序深度标准化:将步骤2的结果除以样本中总的映射读取数(以百万为单位)。这一步用于校正测序深度对读取数的影响。
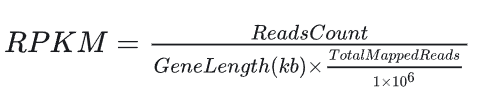
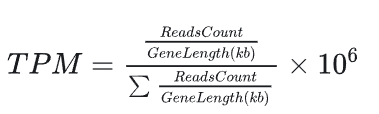
7 TPM标准化
TPM(Transcripts Per Million)是常用的基因表达量标准化方法。
TPM计算方法:
- 读取计数标准化:首先将每个基因的读取数除以该基因的长度(以kb为单位),类似于RPKM的第一步。
- 计算所有基因的标准化读取数的总和。
- 比例标准化:将每个基因的标准化读取数除以步骤2中的总和,并乘以10^6。这样可以确保TPM的总和在每个样本中都是百万级的,便于跨样本比较。

















 1266
1266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









