










博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、大数据毕业设计:2025年选题大全 深度学习 python语言 JAVA语言 hadoop和spark(建议收藏)✅
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、项目介绍
技术栈:
Python语言、Django框架、requests爬虫、数据分析、Echarts可视化、知音漫客网站、HTML
2、项目界面
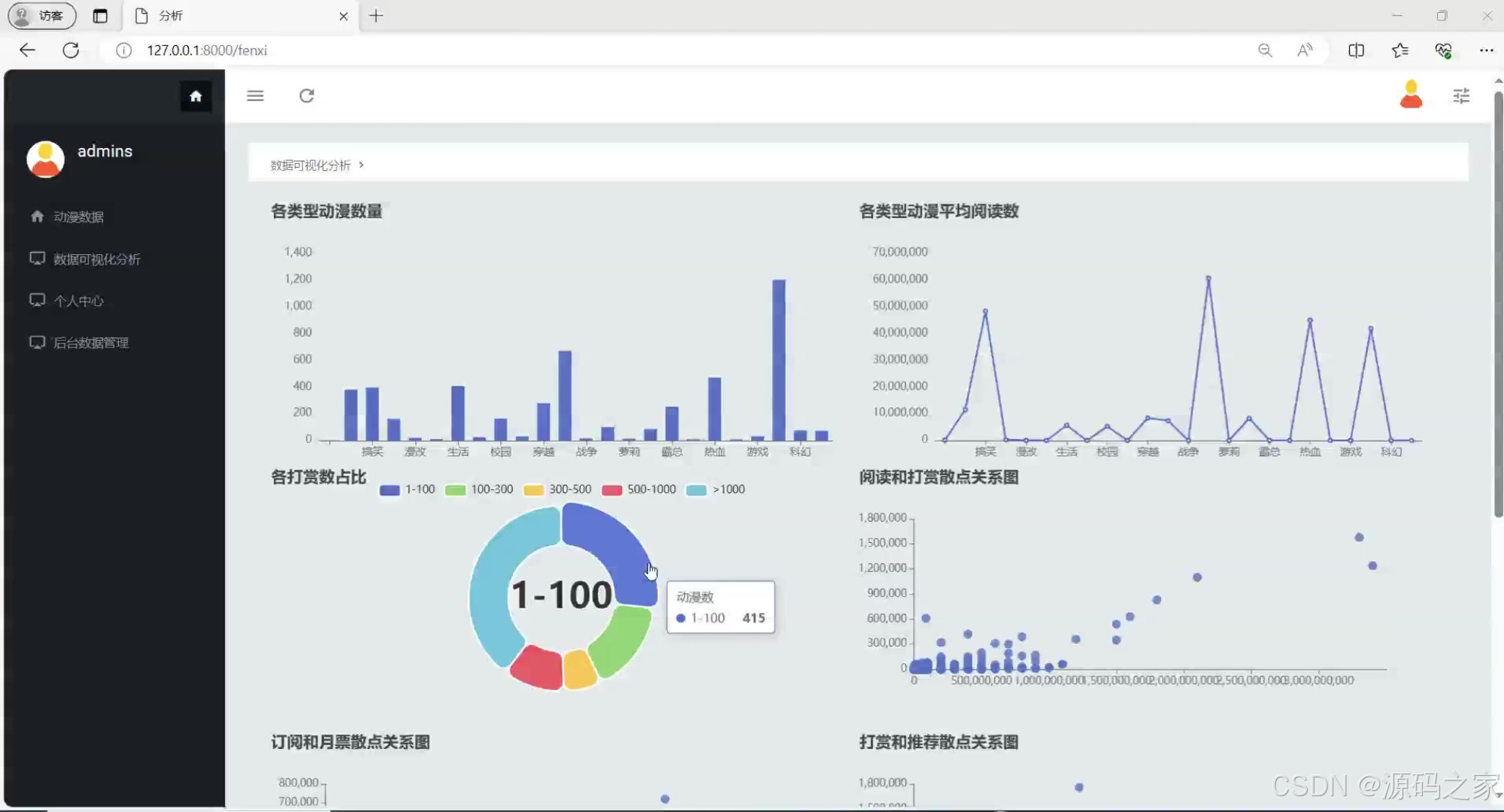
(1)动漫数据可视化分析
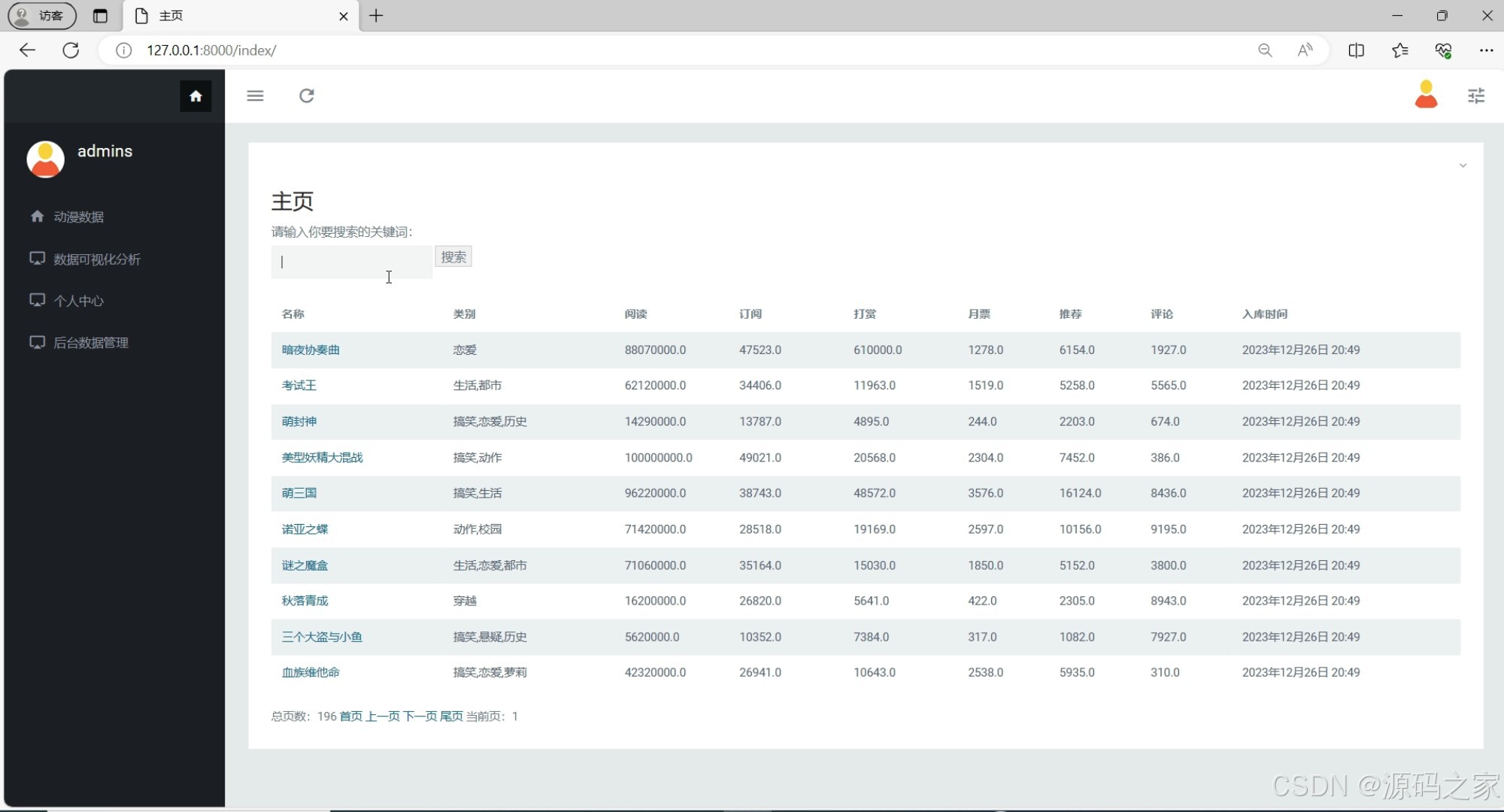
(2)动漫数据列表
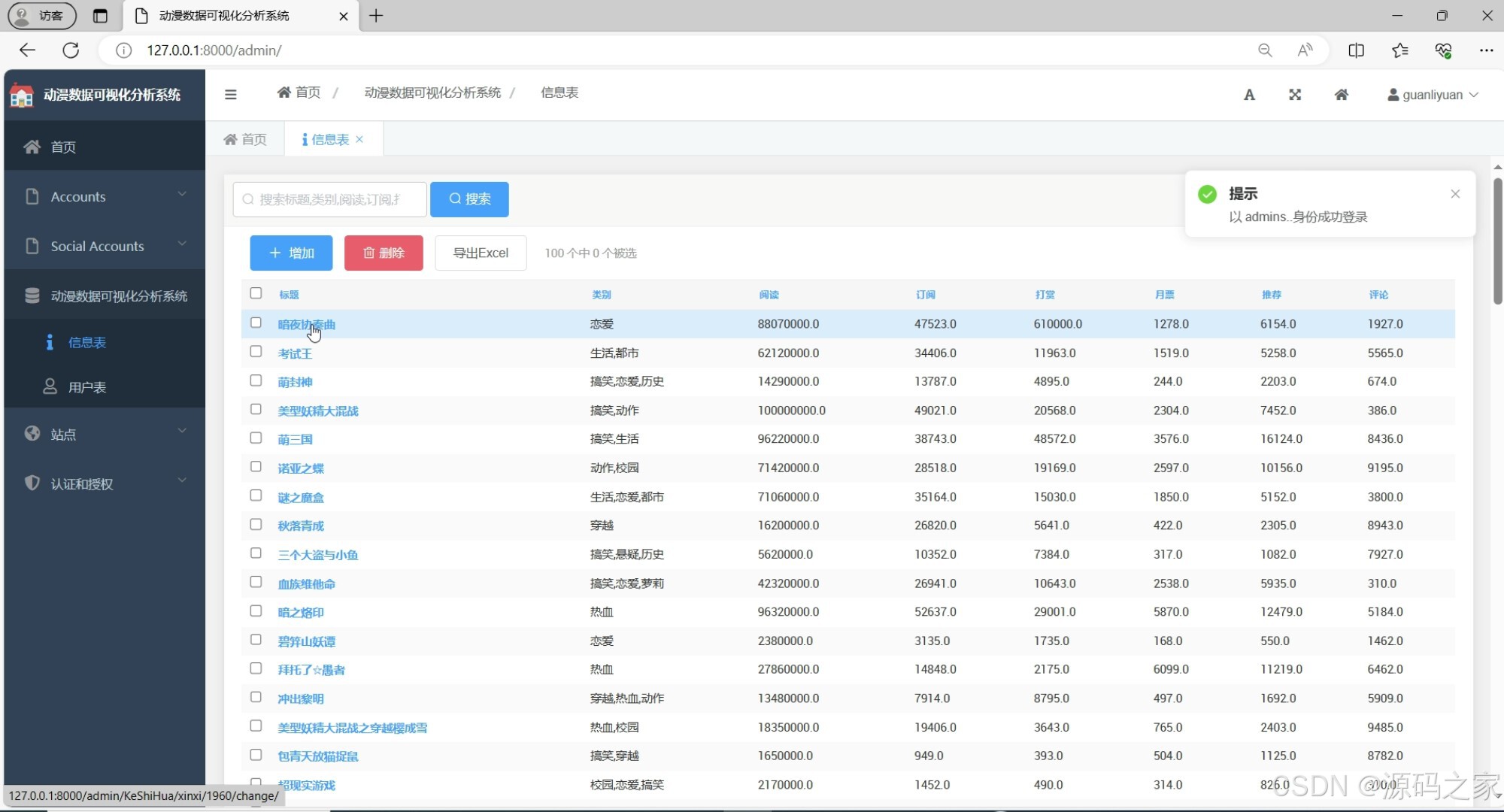
(3)后台数据管理
(4)注册登录
(5)数据采集
3、项目说明
这个系统是一个基于Python语言和Django框架构建的动漫数据分析和可视化平台,主要围绕知音漫客网站的数据进行采集、分析、展示和管理。以下是该系统的主要功能模块介绍:
- 数据采集模块
技术栈:使用requests库进行爬虫开发。
功能:定期或按需从知音漫客网站抓取动漫相关数据,如动漫名称、作者、更新状态、评分、简介等。
实现:通过模拟浏览器请求,解析网页内容,提取所需数据,并保存到本地数据库或数据文件中。 - 数据分析模块
技术栈:Python数据分析库(如Pandas、NumPy)。
功能:对采集到的动漫数据进行清洗、整理、统计和分析,如热门动漫排名、作者作品数量统计、动漫类型分布等。
实现:利用数据分析库对数据库中的数据进行处理,生成分析报告或数据可视化所需的中间数据。 - 数据可视化模块
技术栈:Echarts。
功能:将数据分析结果以图表形式展示,如柱状图、折线图、饼图等,便于用户直观理解数据。
实现:将Echarts集成到Django的前端页面中,通过Ajax或后端渲染方式将数据分析结果传递给前端,由Echarts进行图表绘制。 - 动漫数据列表展示模块
功能:以列表形式展示动漫数据,包括动漫的基本信息和部分详细信息。
实现:在Django的前端页面中,通过模板语言渲染动漫数据列表,提供搜索、排序、分页等功能。 - 后台数据管理模块
功能:为管理员提供后台管理界面,用于管理动漫数据、用户信息、系统设置等。
实现:利用Django的admin后台或自定义后台管理界面,提供数据的增删改查功能,以及用户权限管理、日志查看等。 - 注册登录模块
功能:提供用户注册和登录功能,确保用户身份的安全性和数据的私密性。
实现:使用Django的用户认证系统,实现用户注册、登录、密码重置等功能,并通过session或token保持用户会话。
系统整体流程
数据采集:通过爬虫从知音漫客网站抓取动漫数据。
数据分析:对抓取到的数据进行清洗、整理和分析。
数据可视化:将分析结果以图表形式展示在前端页面。
数据列表展示:以列表形式展示动漫数据,提供搜索和排序功能。
后台管理:管理员通过后台管理界面管理数据和用户。
用户注册登录:用户通过注册登录功能访问系统,确保数据的安全性。
4、核心代码
@login_required
def index(request):
if request.method == 'GET':
datas = models.XinXi.objects.all().order_by('-id')
return render(request,r"projects\table_s.html",locals())
elif request.method == 'POST':
data = request.POST
projects_name = data.get('projects_name')
if not projects_name:
return redirect('web:index')
datas = models.XinXi.objects.filter(name__icontains=projects_name).order_by('-id')
return render(request,r"projects\table_s.html",locals())
@login_required
def user_profile(request):
if request.method == 'GET':
return render(request,'projects/user-profile.html',locals())
@login_required
def update_user(request):
if request.method == 'GET':
data = models.Users.objects.get(username=request.user.username)
return render(request,'projects/form_validations.html',locals())
elif request.method == 'POST':
datas = models.Users.objects.get(username=request.user.username)
error = {}
data = request.POST
email = data.get('email','')
if email != '' and '@' in str(email):
email = email
else:
error['email'] = '邮箱格式错误'
age = data.get('age','')
try:
int(age)
if age != '' and 0 < int(age) and int(age) < 120:
age = age
else:
raise Exception('年龄错误')
except:
error['age'] = '年龄错误'
set = data.get('set','')
if set != '' and str(set) in ['男','女']:
set = set
else:
error['set'] = '性别格式错误'
if error != {}:
return render(request,'projects/form_validations.html',context={'data':datas,'error':error})
else:
models.Users.objects.filter(username=request.user.username).update(email=email,age=age,set=set)
user = request.user
return render(request, 'projects/user-profile.html', locals())
@login_required
def fenxi(request):
if request.method == 'GET':
return render(request,'projects/fenxi.html',locals())
def mean(a):
if len(a) == 0:
return 0
return round(sum(a) / len(a),2)
@login_required
def tubiao(request):
if request.method == 'GET':
datas = models.XinXi.objects.all()
#各类型数量
types1 = []
for da1 in datas:
for da2 in da1.type.split(','):
types1.append(da2)
type_name = []
type_count = []
for ty1 in list(set(types1)):
type_name.append(ty1)
type_count.append(types1.count(ty1))
#各类型动漫平均阅读数
yuedu_name = []
yuedu_count = []
for ty1 in list(set(types1)):
yuedu_name.append(ty1)
data11 = models.XinXi.objects.filter(type=ty1)
yuedu_count.append(mean([da3.J_read for da3 in data11]))
#各打赏数占比
a1 = models.XinXi.objects.filter(reward__range=(1,100))
a2 = models.XinXi.objects.filter(reward__range=(100, 300))
a3 = models.XinXi.objects.filter(reward__range=(300, 500))
a4 = models.XinXi.objects.filter(reward__range=(500, 1000))
a5 = models.XinXi.objects.filter(reward__range=(1000, 10000000000))
reward_name = ['1-100','100-300','300-500','500-1000','>1000']
reward_count = [len(a1),len(a2),len(a3),len(a4),len(a5)]
reward_dict = []
for i in range(len(reward_name)):
reward_dict.append({'name':reward_name[i],'value':reward_count[i]})
#阅读和打赏散点关系图
yuedu_dasang_dict2 = []
for resu in datas:
yuedu_dasang_dict2.append([resu.J_read, resu.reward])
#订阅和月票散点关系图
dingyu_yuepiao_dict2 = []
for resu in datas:
dingyu_yuepiao_dict2.append([resu.collect, resu.monthticket])
#打赏和推荐散点关系图
dashang_tuijian_dict2 = []
for resu in datas:
dashang_tuijian_dict2.append([resu.reward, resu.recommend])
return render(request,'projects/tubiao.html',locals())
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,查看【用户名】、【专栏名称】就可以找到我啦🍅
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看👇🏻获取联系方式👇🏻

















 1567
1567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









