









转自:https://blog.csdn.net/m0_37477175/article/details/78625534
本篇博客是对MIT周博磊论文《earning Deep Features for Discriminative Localization.》的学习笔记。- 要想更多的了解周博磊的主要研究,可以观看斗鱼将门的回放视频,主要是网络的可解释性以及场景分类。
首先,看一下论文具体达到的效果:

通过训练一个场景分类的网络,在分类达到一定精度的时候,利用论文中的方法可视化分类图像的attention区域,比如前两列的图像,代表的是刷牙场景,第二排的图像则显示热力图的重点区域在刷牙的动上;后两列图像为砍树的场景,可以看到attention区域在人和砍树的动作上。论文中称attention区域为class-specific image regions。
这个就感觉比较类人了,人在分辨一个物体比如自行车的时候,不会均匀的观察全体,而是通过判断是否有车把,车轱辘等等region来分辨是否是一个自行车。论文也是基于此想法做的研究。
另一个最近的使用例子是大名鼎鼎的吴恩达公司做的肺炎诊断准确率超过人类医生
在定位患病区域的时候使用 Class Activation Maps, 定位了它识别出的病变,高亮区域是分析病症需要重点观察的位置。 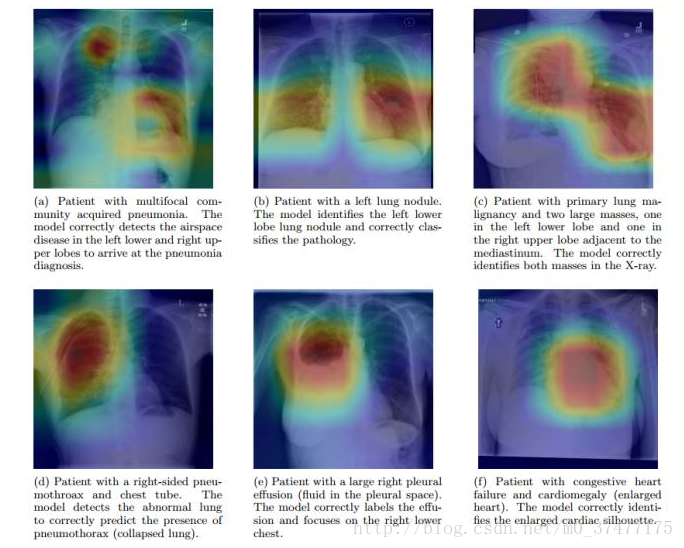
好的!知道如此牛逼则下面开始对论文做相关笔记!
关键技术
- global average pooling layer
- class activation map
global average pooling layer
本论文去掉了全连接层,因为全连接层不能保持图像的空间结构,而使用GAP Layer来代替。在此定位中,比如说一副图片是自行车,车把在右上角,则经过层层卷积到最后一层卷积层之后,feature map上右上角的区域应该对应着自行车的车把,而全连接相当于对feature map 做了一个全排列,丢失掉了空间信息。除此之外,full connected Layer 占了整个网络参数的大部分(仅全连接层参数就可占整个网络参数80%左右),去掉之后,能够使网络训练变得简单。 
比如 最后一层feature map 为64*7*7,则经过GAP之后就为64*1*1
每一个7*7对应一个1*1,值为单个feature map的平均值。
class activation map
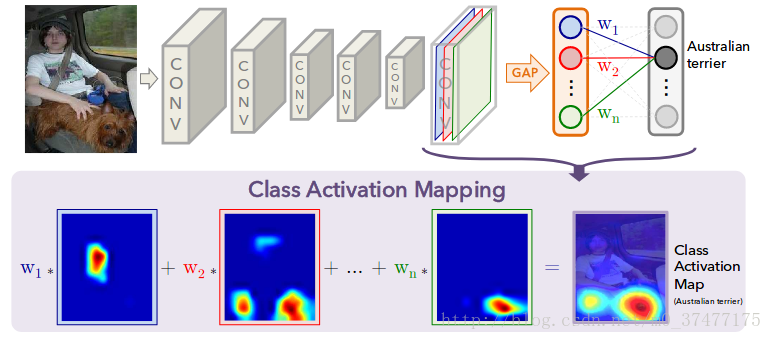
原理通俗来说非常简单:假设有10分类,有一个分类为 猫,训练之后的网络,我们输入张图片,发现 猫 的概率为0.6,则我们想知道网络对于猫的一个attention区域是什么。借之前的假设,经过GAP之后,为64*1*1,直接输入输出为10类的full connected layer,则对应的 猫 这个标签的输出,连接有64个权重,即w1,w2……w64。我们将权重与最后一层的feature map 线性相加,得到一个7*7的map,直接,非常暴力的resize到原图大小,形成热力图。这是对过程的一个通俗解释。想要深入的了解到底是如何实现的,比如如何形成热力图这些细节要到源码中看。
caffe的matlab代码
当然最方便的还是python
caffe的python的代码
pycaffe 代码梳理
首先乱七八糟基础库的导入,环境的设置
import numpy as np
import sys
import os
try:
caffe_root = os.environ['CAFFE_ROOT'] + '/'
except KeyError:
raise KeyError("Define CAFFE_ROOT in ~/.bashrc")
sys.path.insert(1, caffe_root+'python/')
import caffe
import cv2
from py_returnCAMmap import py_returnCAMmap #额外的py文件导入
from py_map2jpg import py_map2jpg #额外的py文件导入
import scipy.io- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
网络导入以及类别文件
关于网络预训练参数文件以及网络配置文件都可以在上面提到的github中下载。
model = 'googlenet'
if model == 'alexnet':
net_weights = 'models/alexnetplusCAM_imagenet.caffemodel'
net_model = 'models/deploy_alexnetplusCAM_imagenet.prototxt'
out_layer = 'fc9'
last_conv = 'conv7'
crop_size = 227
elif model == 'googlenet':
net_weights = 'models/imagenet_googlenetCAM_train_iter_120000.caffemodel'
net_model = 'models/deploy_googlenetCAM.prototxt'
out_layer = 'CAM_fc'
crop_size = 224
last_conv = 'CAM_conv'
else:
raise Exception('This model is not defined')
categories = scipy.io.loadmat('categories1000.mat')
#数据类型一定要随时随地的查看
#print type(categories)
#<type 'dict'> #字典类型
#print categories- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
图片数据标准化函数
def im2double(im):
return cv2.normalize(im.astype('float'), None, 0.0, 1.0, cv2.NORM_MINMAX)- 1
- 2
初始化模型以及利用caffe io接口进行数据类型转换
net = caffe.Net(net_model, net_weights, caffe.TEST)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
#将channel放到最前面
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', np.load(caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy').mean(1).mean(1))
#transformer.set_raw_scale('data', 255) # rescale from [0, 1] to [0, 255]
#transformer.set_channel_swap('data', (2,1,0)) # caffe模型的图片数据为BGR格式,而我们此处采用opencv读取图片数据,格式也是BGR所以不用转换
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
提取网络最后一层全连接层的权重
weights_LR = net.params[out_layer][0].data
#可打印查看数据类型
#print 'weight_LR_type',type(weights_LR),'weight_LR_shape',np.shape(weights_LR)
# the value of W of the layer 'CAM_FC'
# shape: [1000, N] N-> depends on the network
#N取决与GAP层的输出维数- 1
- 2
- 3
- 4
- 5
- 6
读入样例图片

image = cv2.imread('22.jpg')
image = cv2.resize(image, (256, 256))
# Take center crop.
center = np.array(image.shape[:2]) / 2.0
crop = np.tile(center, (1, 2))[0] + np.concatenate([
-np.array([crop_size, crop_size]) / 2.0,
np.array([crop_size, crop_size]) / 2.0
])
crop = crop.astype(int)
input_ = image[crop[0]:crop[2], crop[1]:crop[3], :]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
提取最后一层的特征feature map
# extract conv features
net.blobs['data'].reshape(*np.asarray([1,3,crop_size,crop_size])) # run only one image
net.blobs['data'].data[...][0,:,:,:] = transformer.preprocess('data', input_)
#进行前向运算
out = net.forward()
#得到最后一层的概率
scores = out['prob']
#得到最后一层卷积层的特征
activation_lastconv = net.blobs[last_conv].data- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
进行CAM操作
## Class Activation Mapping
topNum = 5 # generate heatmap for top X prediction results
scoresMean = np.mean(scores, axis=0)
ascending_order = np.argsort(scoresMean)
IDX_category = ascending_order[::-1] # [::-1] to sort in descending order
curCAMmapAll = py_returnCAMmap(activation_lastconv, weights_LR[IDX_category[:topNum],:])
#数据归一化
curResult = im2double(image)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
对预测概率前五的标签,生成CAM map。
for j in range(topNum):
# for one image
curCAMmap_crops = curCAMmapAll[:,:,j]
curCAMmapLarge_crops = cv2.resize(curCAMmap_crops, (256,256))
curHeatMap = cv2.resize(im2double(curCAMmapLarge_crops),(256,256)) # this line is not doing much
curHeatMap = im2double(curHeatMap)
curHeatMap = py_map2jpg(curHeatMap, None, 'jet')
curHeatMap = im2double(image)*0.2+im2double(curHeatMap)*0.7
cv2.imshow(categories['categories'][IDX_category[j]][0][0], curHeatMap)
cv2.waitKey(0)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
最关键的代码
生成热力图
py_returnCAMmap.py
import numpy as np
def py_returnCAMmap(activation, weights_LR):
print(activation.shape)
if activation.shape[0] == 1: # only one image
n_feat, w, h = activation[0].shape
act_vec = np.reshape(activation[0], [n_feat, w*h])
n_top = weights_LR.shape[0]
out = np.zeros([w, h, n_top])
for t in range(n_top):
weights_vec = np.reshape(weights_LR[t], [1, weights_LR[t].shape[0]])
heatmap_vec = np.dot(weights_vec,act_vec)
heatmap = np.reshape( np.squeeze(heatmap_vec) , [w, h])
out[:,:,t] = heatmap
else: # 10 images (over-sampling)
raise Exception('Not implemented')
return out- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
生成热力图
py_map2jpg.py
import numpy as np
import cv2
def py_map2jpg(imgmap, rang, colorMap):
if rang is None:
rang = [np.min(imgmap), np.max(imgmap)]
heatmap_x = np.round(imgmap*255).astype(np.uint8)
return cv2.applyColorMap(heatmap_x, cv2.COLORMAP_JET)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
结果: 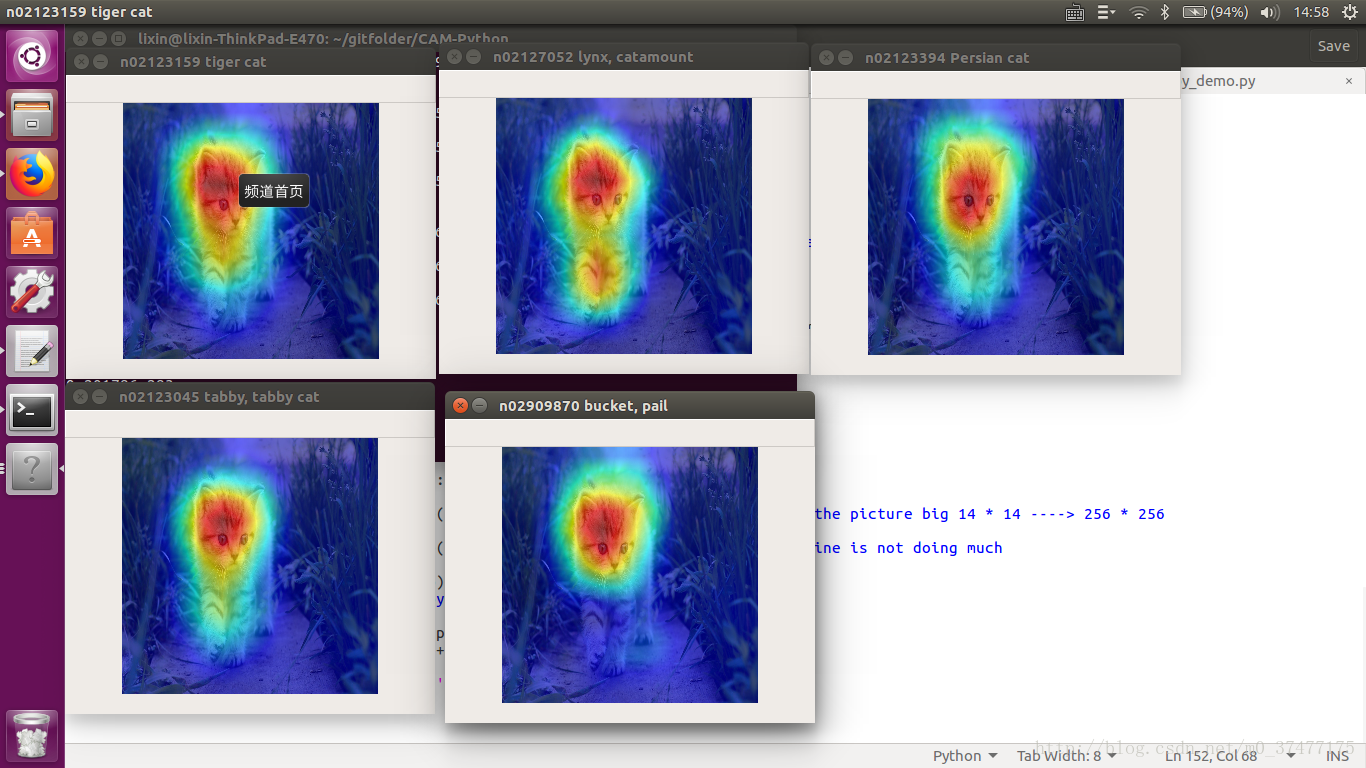
从左往右从上往下,概率值依次降低,得到的前五个label的热力图。
其中,概率值和标签index分别为
0.309264 282
0.290125 287
0.201786 283
0.111381 281
0.0131595 463
具体的代码可以查看上面的我发的链接。

















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









