







系列文章目录
文章目录
前言
当你往前走的时候,要一路撒下花朵,因为同样的道路你决不会走第二遍。
hadoop的运行模式分为本地模式、伪分布式、完全分布式。
一、本地模式
1.1创建目录
创建一个wcinput目录,并进入目录,创建一个文件word.txt,并输入一些单词,保存。
[hyh@hadoop102 hadoop-3.1.3]$ mkdir wcinput[hyh@hadoop102 hadoop-3.1.3]$ cd wcinput[hyh@hadoop102 wcinput]$ vim word.txt
1.2需要执行命令来统计单词的个数
执行命令hadoop-3.1.3/share/hadoop/mapreduce下的hadoop-mapreduce-examples-3.1.3.jar来统计单词的个数。
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
结果如下,根据wcinput中的单词进行统计:
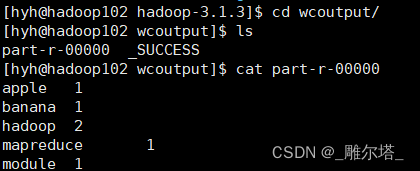
二、完全分布式
步骤整体如下:
2.1编写集群分发脚本
rsync -av 要拷贝的文件路径 / 名称 目的用户 @ 主机名 :目录的路径 / 名称
[hyh@hadoop102 opt]$ rsync -av /opt/software/* chenxp@hadoop103:/opt/software/
(1)编写脚本
-
功能:循环复制文件到所有的节点的相同目录下
- 期望的脚本:脚本名 要同步的文件名称
- 脚本的实现:
#!/bin/bash
#1.判断参数个数
if [ $# -lt 1 ]
then
echo Not enough argument!
exit
fi
#2.遍历集群中所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ===========$host==========
#3.遍历所有的目录,一个一个的发送
for file in $@
do
#4.判断文件是否存在
if [ -e $file ]
then
#5.获取当前文件的父目录
pdir=$(cd -P $(dirname $file);pwd)
#6.获取当前文件名
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
#分发文件
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exist!
fi
done
done(2)修改脚本的权限-具有可执行权限
[hyh@hadoop102 bin]$ chmod +x xsync.sh
(3)将脚本赋值到/bin中,方便全局调用
[hyh@hadoop102 bin]$ sudo cp xsync.sh /bin/
(4)测试脚本
[hyh@hadoop102 bin]$ ./xsync.sh /home/chenxp/bin
(5)检查
2.2免密设置
The authenticity of host 'hadoop104 (192.168.81.104)' can't be established.ECDSA key fingerprint is SHA256:GjywmiM7XB61LXLg459aNXGsD23R6PtVgbvSmj9YDCI.ECDSA key fingerprint is MD5:dc:d5:11:cf:ca:27:49:46:7a:43:f6:16:1e:10:d1:58.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'hadoop104,192.168.81.104' (ECDSA) to the list of knownhosts.hyh@hadoop104's password:
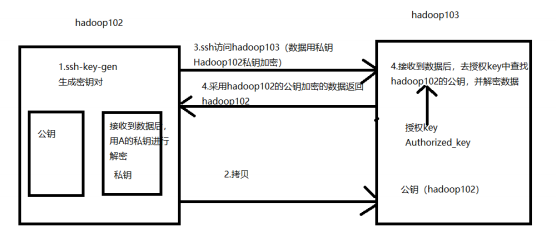

生成密钥, 并查看密钥,此时在.ssh目录下回生成id_rsa私钥和id_rsa.pub公钥:
[hyh@hadoop102 .ssh]$ ssh-keygen -t rsa
执行完操作以后,查看目录下文件:
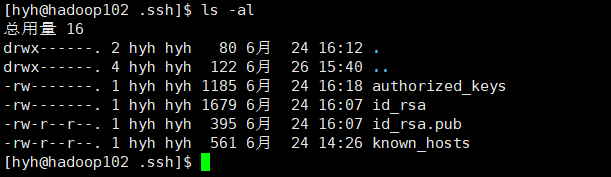
把hadoop102的密钥对拷贝到hadoop103 hadoop104 hadoop102中 :
[hyh@hadoop102 .ssh]$ ssh-copy-id hadoop103[hyh@hadoop102 .ssh]$ ssh-copy-id hadoop104[hyh@hadoop102 .ssh]$ ssh-copy-id hadoop102
结语
在本系列文章中,介绍了大数据Hadoop方向技术。从本地模式到完全分布式的运行模式进行了详细的说明和演示。
在本地模式下,创建了一个包含单词的文件,并使用Hadoop的示例程序进行单词统计。通过这个简单的例子,了解了Hadoop的基本工作原理和使用方法。
而在完全分布式环境中,介绍了搭建Hadoop集群的步骤,包括安装JDK、配置环境变量、安装Hadoop等。我们还通过编写脚本和使用rsync工具,实现了文件在集群中的分发和同步。此外,还介绍了如何设置免密登录,以方便在集群节点之间进行SSH连接。
通过本系列文章的学习,你应该对Hadoop和Spark的基本概念和运行模式有了更深入的了解。希望这些知识能够帮助你在大数据领域取得更好的成果。
在你的大数据之旅中,记得始终保持前进的姿态,将你的学习和实践散发出美丽的花朵,因为每一次的经历都是独一无二的。祝愿你在大数据方向上取得巨大的成功!















 2131
2131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









