







系列文章目录
文章目录
2)如果删除的数据库不存在,最好采用if exists判断数据库是否存在
前言
该博客主要介绍了Hive的数据类型和DDL数据定义,包括创建数据库、查询数据库、选择数据库、创建表等操作。在内部表和外部表的部分,详细介绍了它们的区别和使用方法,并演示了如何导入数据和进行表的操作,如重命名表、增加/修改/替换列信息等。最后,在DML数据操作中,我们介绍了数据导入、插入数据、查询语句创建表和加载数据、导出数据等操作。通过学习本系列文章,读者可以快速入门大数据技术,并在实际应用中进行实践和探索。
一、hive的基本操作
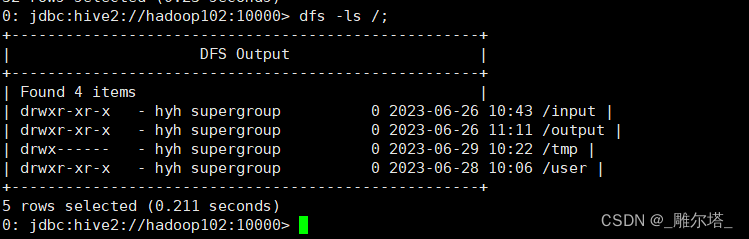
在hive中查看dfs的文件系统:
dfs -ls /;
 查看在hive中执行的所有命令:
查看在hive中执行的所有命令:
1、进入当前用户的根目录:
cd ~
2、查看.hivehistory文件
cat .hivehistory
二、hive的常见配置
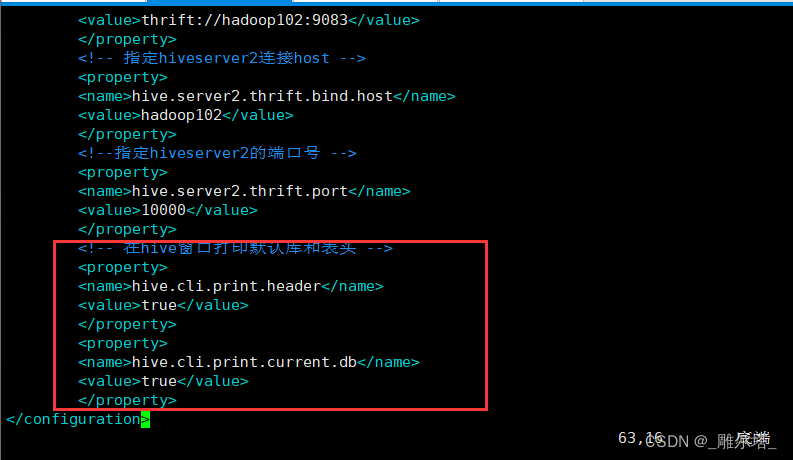
1.hive窗口中打印默认的表头
<!-- 在hive窗口打印默认库和表头 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
2.hive运行日志信息的配置
(1)hive的log默认存储在/tmp/用户名(当前的用户)/hive.log
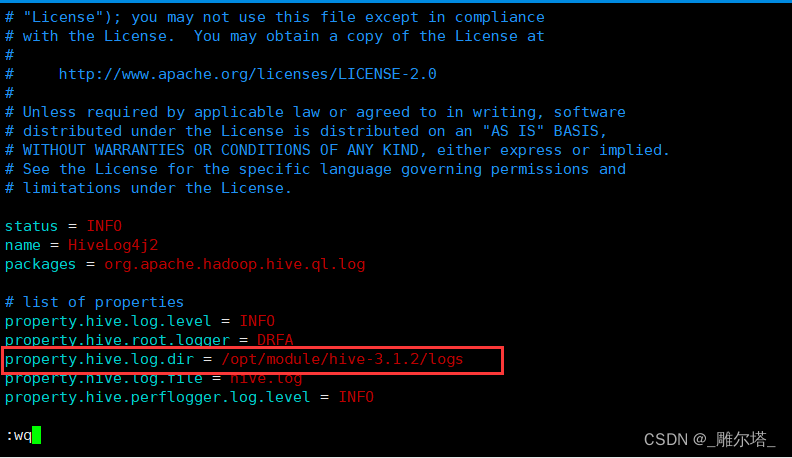
(2)修改hive的log存放位置
修改hive的conf中hive-log4j2.properties.template进行重命名为hive-log4j2.properties
mv hive-log4j2.properties.template hive-log4j2.properties
在hive-log4j2.properties中修改log存储位置,并保存:
property.hive.log.dir = /opt/module/hive-3.1.2/logs
二、编写启动metastore和hiveserver2脚本
1.shell命令:
nohup:放在命令的开头,表示不挂起,也就是关闭终端,进程也继续保持运行状态。
&:放在命令的结尾,表示后台运行。
0:标准输入。
1:标准输出。
2:错误输出。
2>&1:把错误输出重定向到标准输出。
后台运行metastore:
nohup hive --service metastore 2>&1 &
2.参数配置方式
1)查看当前所有的配置信息
hive>set ;
2)参数的配置三种方式
hive (default)> set mapred.reduce.tasks;
hive (default)> set mapred.reduce.tasks=100;
hive (default)> set mapred.reduce.tasks;
三、Hive数据类型
1.基本数据类型
|
Hive
数据类型
|
Java
数据类型
|
长度
|
|
TINYINT
|
byte
|
1byte
有符号整数
|
|
SMALINT
|
short
|
2byte
有符号整数
|
|
INT
|
int
|
4byte
有符号整数
|
|
BIGINT
|
long
| 8byte有符号整数 |
|
BOOLEAN
|
boolean
|
布尔类型,
true
或者
false
|
|
FLOAT
|
float
|
单精度浮点数
|
|
DOUBLE
|
double
|
双精度浮点数
|
|
STRING
| string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 |
|
TIMESTAMP
|
时间类型
| |
| BINARY | 字节数组 |
2.集合数据类型
|
数据类
型
|
描述
|
|
STRUCT
|
和
c
语言中的
struct
类似,都可以通过
“
点
”
符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第
1
个元素可以通过字段
.first
来引用。
|
|
MAP
|
MAP
是一组键
-
值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键
->
值对是
’first’->’John’
和
’last’->’Doe’
,那么可以通过字段名
[‘last’]
获取最后一个元素。
|
|
ARRAY
|
数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’]
,那么第
2
个元素可以通过数组名
[1]
进行引用。
|
四、DDL数据定义
1.创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name[COMMENT database_comment][LOCATION hdfs_path][WITH DBPROPERTIES (property_name=property_value, ...)];
- 创建一个数据库,数据库在HDFS上的默认存储路径是/user/hive/warehouse/*.db。
0: jdbc:hive2://hadoop102:10000> create database db_hive;
- 避免要创建的数据库已经存在错误,增加if not exists判断。
0: jdbc:hive2://hadoop102:10000> create database if not exists db_hive;
- 创建一个数据库,指定数据库在HDFS上存放的位置。
0: jdbc:hive2://hadoop102:10000> create database db_hive2 location '/db_hive2.db';
2.查询数据库
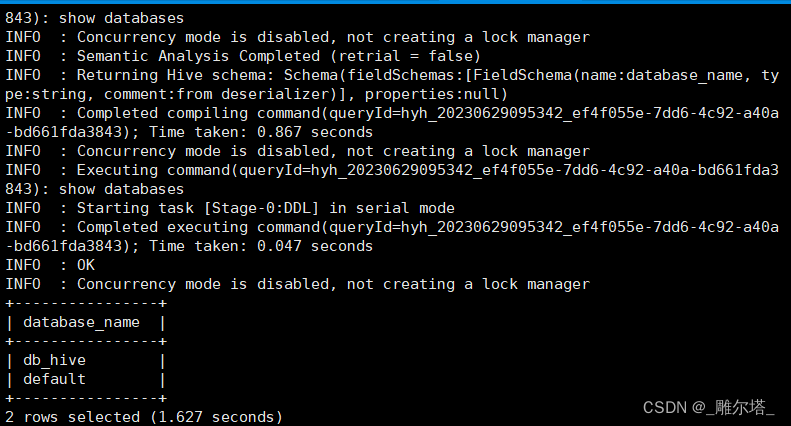
1)查询数据库
0: jdbc:hive2://hadoop102:10000> show databases;
2)过滤显示查询的数据库
0: jdbc:hive2://hadoop102:10000> show databases like 'db*';
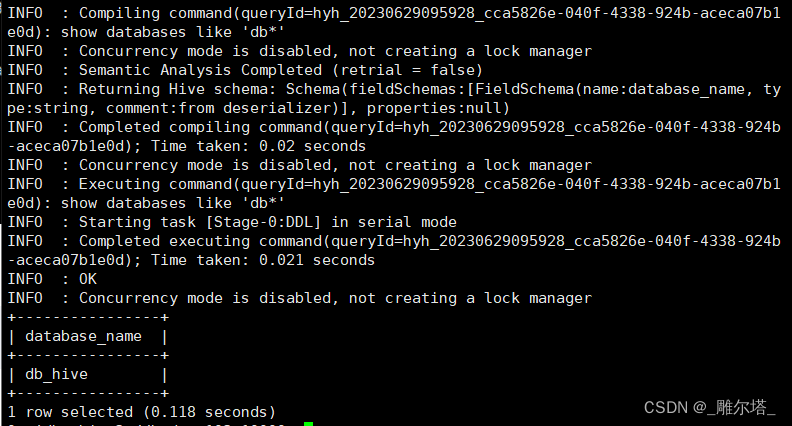
2.查看数据库详情
1)显示数据库信息
0: jdbc:hive2://hadoop102:10000> desc database db_hive;
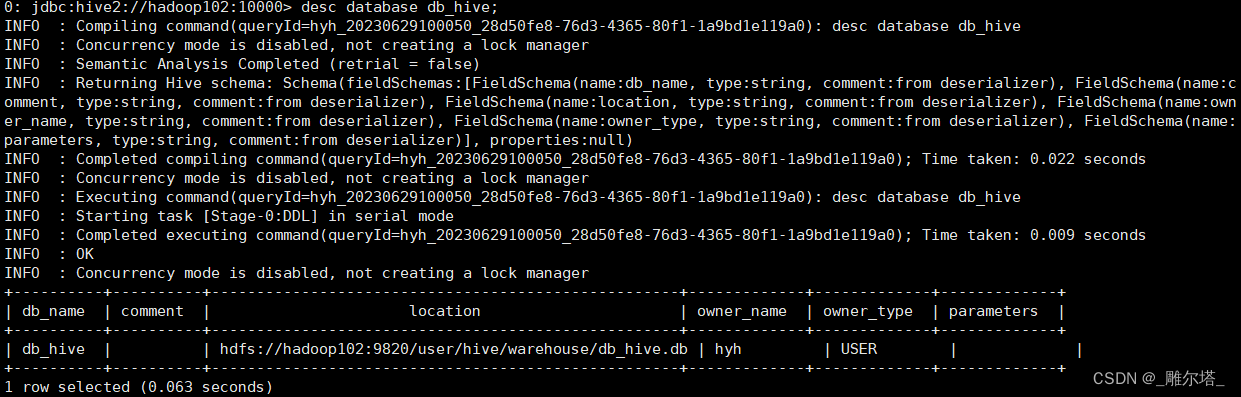
2)显示数据库详细信息-extended
0: jdbc:hive2://hadoop102:10000> desc database extended db_hive;
3.选择数据库
hive (default)> use db_hive

4.删除数据库
1)删除空数据库
hive (db_hive)> drop database db_hive2;
2)如果删除的数据库不存在,最好采用if exists判断数据库是否存在
hive (db_hive)> drop database if exists db_hive2;
3)如果数据库不为空,可以采用cascade命令,强制删除
hive (default)> drop database db_hive cascade;
5.创建表
1)建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name[( 字段名 数据类型 [COMMENT 字段的注释 ], ...)][COMMENT 表的注释 ][PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)][ROW FORMAT row_format][STORED AS file_format][LOCATION hdfs_path]
2)字段说明
( 1 ) EXTERNAL 关键字可以让用户创建一个外部表,在建表的同时可以指定一个指向实际数据的路径( LOCATION ),在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。( 2 ) COMMENT :为表和列添加注释。( 3 ) PARTITIONED BY 创建分区表( 4 ) ROW FORMAT delimited fields terminated by ' 分隔符 '( 5 ) STORED AS 指定存储文件类型( 6 ) LOCATION :指定表在 HDFS 上的存储位置。
3)案例:
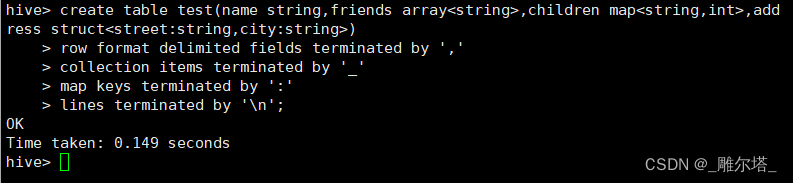
hive (db_hive)> create table test(name string,friends array<string>,childrenmap<string,int>,address struct<street:string,city:string>)> row format delimited fields terminated by ',' -- 列分隔符> collection items terminated by '_' ---map,struct 和 array 元素的分隔符> map keys terminated by ':' ---map 中键和值之间的分隔符> lines terminated by '\n'; --- 行分隔符OKTime taken: 0.156 seconds
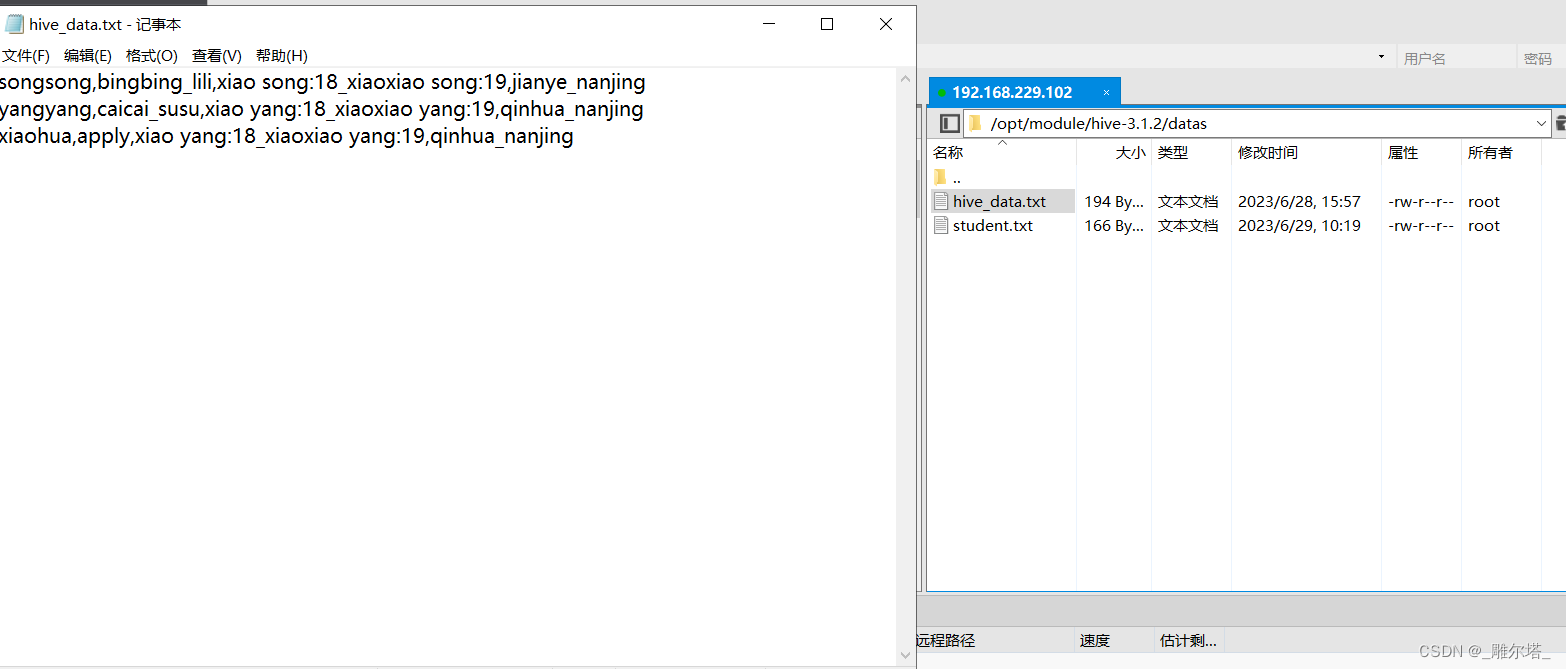
- 准备文本数据导入到test表 :
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,jianye_nanjing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,qinhua_nanjingxiaohua,apply,xiao yang:18_xiaoxiao yang:19,qinhua_nanjing
hive (db_hive)> load data local inpath '/opt/module/hive-3.1.2/datas/hive_data.txt'
into table test;
- 查看数据
hive (db_hive)> select * from test;hive (db_hive)> select name,friends[1],children['xiaoxiao yang'],address.city fromtest;

五、内部表
1.创建内部表:
0: jdbc:hive2://hadoop102:10000> create table if not exists student(id int,name string)
. . . . . . . . . . . . . . . .> row format delimited fields terminated by '\t'
. . . . . . . . . . . . . . . .> stored as textfile
. . . . . . . . . . . . . . . .> location '/user/hive/warehouse/student';
2.导入文本数据
导入文本数据到student表中,内容如下:
字段和字段之间是制表符'\t'
10001 ss1
10002 ss2
10003 ss3
10004 ss4
10006 ss6
10007 ss7
10008 ss8
10009 ss9
100010 ss10
100011 ss11
100012 ss12
100013 ss13
100014 ss14
100015 ss15
0: jdbc:hive2://hadoop102:10000> load data local inpath '/opt/module/hive-3.1.2/datas/student.txt' into table student;
3.根据查询的结果列表
查询的结果会添加到新建的表中:
0: jdbc:hive2://hadoop102:10000> create table if not exists stuent1 as select id,name from student;
4.查看表的类型
0: jdbc:hive2://hadoop102:10000> desc formatted student;
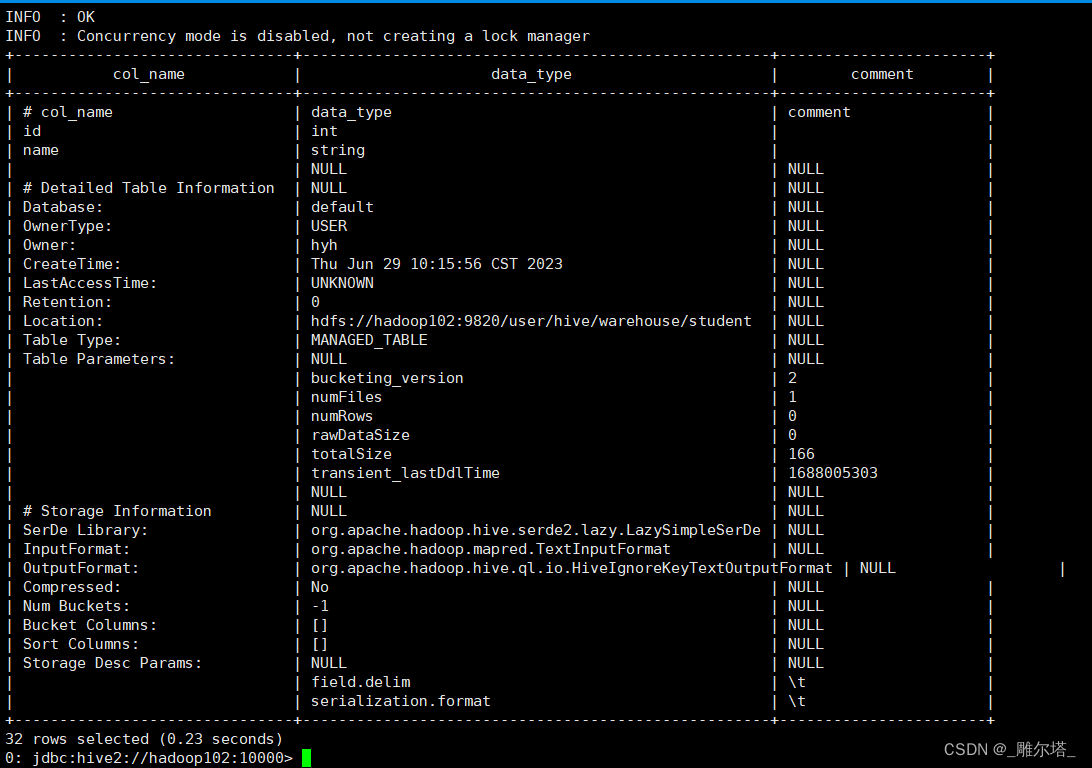
六、外部表
1.上传数据到HDFS
hive (db_hive)> dfs -mkdir /user/hive/warehouse/dept;
hive (db_hive)> dfs -mkdir /user/hive/warehouse/emp;
hive (db_hive)> dfs -put /opt/module/hive-3.1.2/datas/emp.txt /user/hive/warehouse/emp;
hive (db_hive)> dfs -put /opt/module/hive-3.1.2/datas/dept.txt /user/hive/warehouse/dept;
内容:
dept:
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
emp:
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
执行完命令可以看到文件已上传:
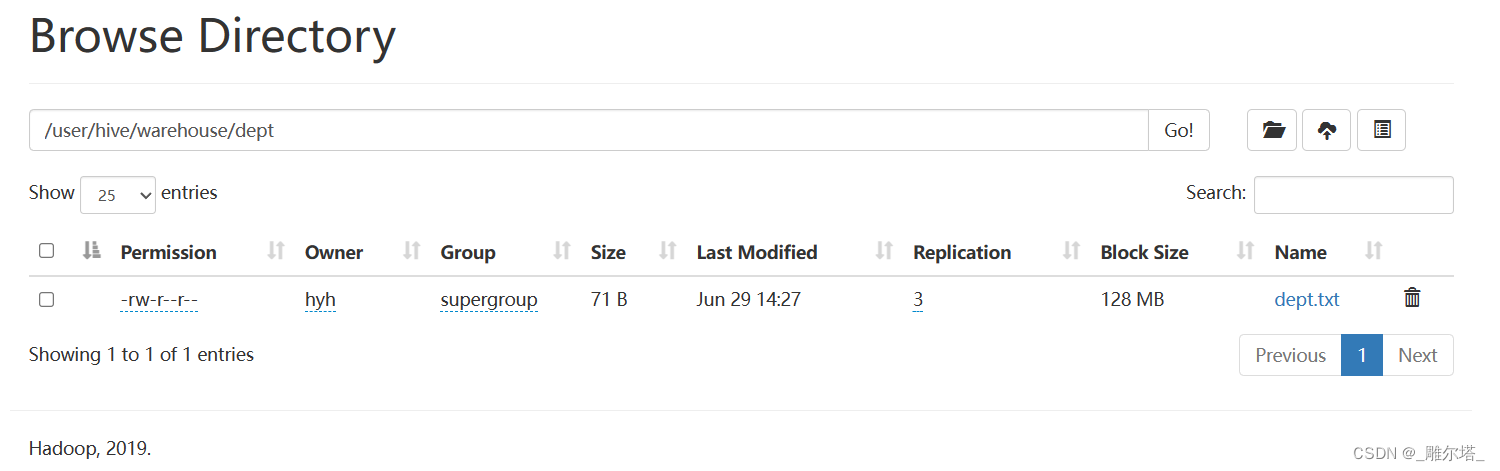
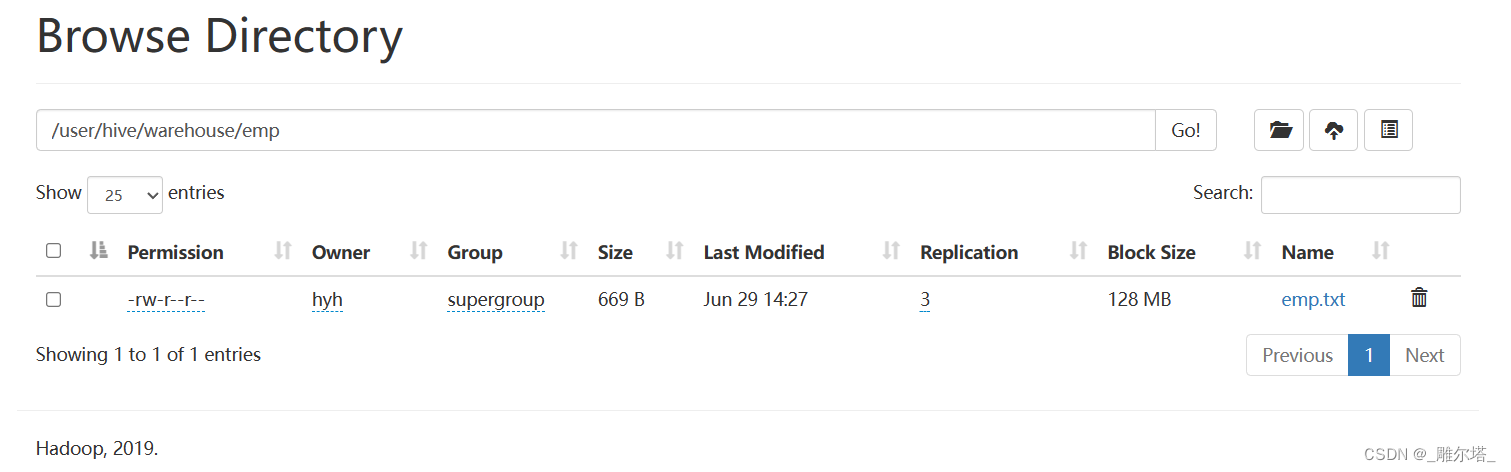
2.创建emp和dept表
hive (db_hive)> create external table if not exists emp(empno int,
> ename string,
> job string,
> mgr int,
> hiredate string,
> sal double,
> comm double,
> deptno int)
> row format delimited fields terminated by '\t'
> lines terminated by '\n';
hive (db_hive)> create external table if not exists dept(deptno int,
> dname string,
> loc int)
> row format delimited fields terminated by '\t'
> lines terminated by '\n';
查看表:
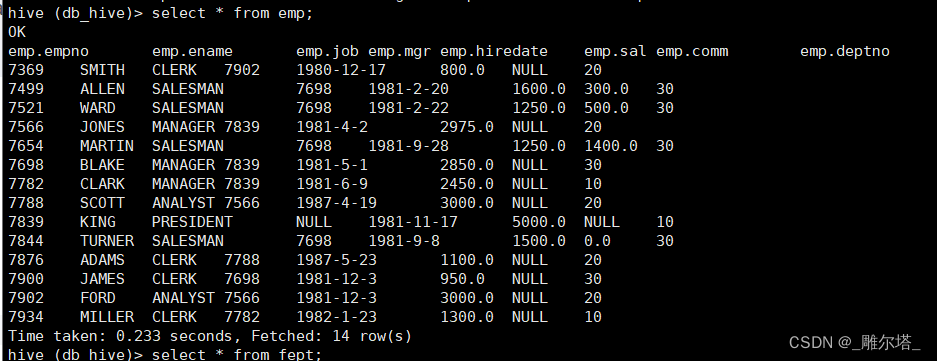
3.删除外表
hive (db_hive)> drop table dept;
alter table emp set tblproperties('EXTERNAL'='FALSE');
alter table emp set tblproperties('EXTERNAL'='TRUE');
查看表的类型
hive (db_hive)> desc formatted emp;
4、修改表
重命名表:
alter table 表名 rename to 新的表名;
hive (db_hive)> alter table emp rename to emp1;
增加/修改/替换列信息:
alter table 表名 add|replace COLUMNS (列名 数据类型 [comment 注释信息],.....) --增加和替换
alter table 表名 change 旧的列名 新的列名 数据类型 [comment 注释信息 ] -- 修改
案例
0: jdbc:hive2://hadoop102:10000> alter table dept add columns(city string); -- 新增一列0: jdbc:hive2://hadoop102:10000> desc dept -- 查看表结构0: jdbc:hive2://hadoop102:10000> alter table dept change column city deptcomm string;-- 修改表中的字段0: jdbc:hive2://hadoop102:10000> desc dept -- 查看表结构0: jdbc:hive2://hadoop102:10000> alter table dept replace columns(deptno string,dnamestring,loc string); -- 替换表0: jdbc:hive2://hadoop102:10000> desc dept -- 查看表结构
七、DML数据操作
1.数据导入
load data [local] inpath ' 数据的路径 ' [overwrite] into table 表名 [partition ]
|
load data :
表示加载数据
|
|
local:
从本地加载数据到
hive
表中,否则从
hdfs
加载数据到
hive
表
|
|
inpath:
表示的是加载数据的路径
|
|
overwrite:
覆盖表中已经存在的数据,否则表示追加
|
|
into table:
加载到哪张表中
|
|
partition:
上传到指定的分区
|
2.插入数据
hive (db_hive)> show tables;hive (db_hive)> desc student1;hive (db_hive)> insert into table student1 values(1,'apple'),(2,'manggo');hive (db_hive)> select * from student1
3.查询语句并创建表并加载数据(as select)
create table if not exists 表名 as select * from 表名 2
4.Import数据到指定的Hive表中
import table 表名 from ‘hdfs 的路径 '
5. export导出到HDFS上
export table 表名 to 'hdfs 的路径 '
注意: export和import主要用于两个hadoop集群之间hive表的迁移
6.数据导出(insert导出)到本地
(1)将查询的结果导出到本地
语法:
insert overwrite local directory '本地路径' select查询语句
hive (db_hive)> insert overwrite local directory '/opt/module/hive-3.1.2/datas/export/dept' select * from dept;
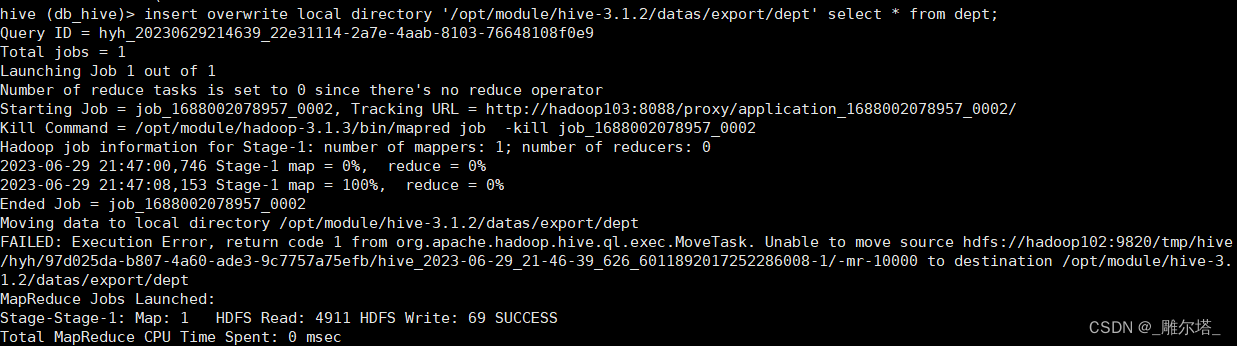 可以到本地的/opt/module/hive-3.1.2/datas/export/dept查看导出数据,发现导出的数据没有格式:
可以到本地的/opt/module/hive-3.1.2/datas/export/dept查看导出数据,发现导出的数据没有格式:
cat 000000_0
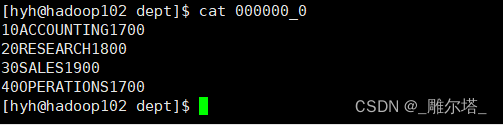
7.将查询的结果导出到HDFS上(没有local)
hive (db_hive)> insert overwrite directory '/user/hyh/dept'> ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' select * from dept;
可以到HDFS的/user/chenxp/dept查看导入的数据 :
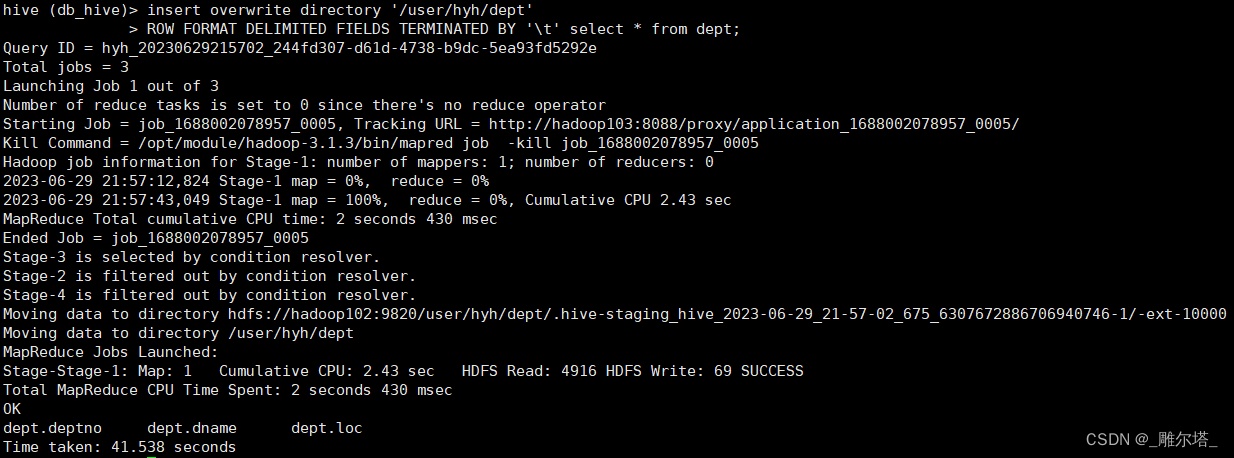
8.hadoop命令导出到本地
hive (db_hive)> dfs -get /user/hive/warehouse/dept/dept.txt /opt/module/hive-3.1.2;
hive (db_hive)> truncate table dept;FAILED: SemanticException [Error 10146]: Cannot truncate non-managed table dept.
因为dept表是外部表,所以报错:
hive (db_hive)> truncate table student1;
OKTime taken: 0.285 secondshive (db_hive)> select * from student1;OKstudent1.id student1.nameTime taken: 0.223 seconds
student1是内部表,所以能成功删除student1中所有的数据。
结语
如果该博客对你有用的话,请关注与收藏,您的认可是我最大的动力!














 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









