






启动元数据服务
# 前台启动
hive --service metastore
# 元数据服务会一直在前台运行,需要克隆一个session进行其他操作 或者使用ctrl+z将它挂起到后台
# 后台启动
hive --service metastore &
# 在后台启动 若退出终端 则会退出
nohup hive --service metastore &
# 这种方式 即使退出终端 服务也会继续运行 启动日志会在当前目录下的 nohup.out中
nohup hive --service metastore 1>/dev/null 2>1 &
# 这种方式将 启动日志 写入到黑洞 不显示任何内容
# /dev/null :代表空设备文件
# > :代表重定向到哪里,例如:echo "123" > /home/123.txt
# 1 :表示stdout标准输出,系统默认值是1,所以">/dev/null"等同于"1>/dev/null"
# 2 :表示stderr标准错误输出
# & :表示等同于的意思,2>&1,表示2的输出重定向等同于1
# 1>/dev/null:首先表示标准输出重定向到空设备文件,也就是不输出任何信息到终端,说白了就是不显示任何信息。
# 2>&1:接着,标准错误输出重定向标准输出,因为之前标准输出已经重定向到了空设备文件,所以标准错误输出也重定向到空设备文件。
# 检查启动额端口
# 端口存在说明元数据服务启动成功
netstat -nltp | grep 9083
命令行客户端
Hive发展至今,总共历经了两代客户端工具。
第一代客户端( deprecated不推荐使用)︰$HIVE_HOME/bin/hive,是一个shellUtil。主要功能∶一是可用于以交互或批处理模式运行Hive查询;二是用于Hive相关服务的启动,比如metastore服务。
第二代客户端( recommended推荐使用)∶$HIVE_HOME/bin/beeline,是一个JDBC客户端,是官方强烈推荐使用的Hive命令行工具,和第一代客户端相比,性能加强安全性提高。
第一代客户端Hive

本地访问
# 先启动元数据服务 注意如果已经启动不能再次启动 会报错
nohup hive --service metastore &
# 启动后直接使用hive命令即可
# 进入后可以使用正常的SQL语句.
# 退出客户端的命令
exit;
quit;
远程访问
# 我们是远程连接模式是可以使用其他计算机来进行访问的.
# 如果使用其他计算机访问 首先这台计算机需要安装hive
# linux02 和 linux03 上传 hive的压缩包并解压
# linux02
tar -zxf apache-hive-3.1.2.tar.gz
mv apache-hive-3.1.2-bin/ /opt/apps/hive-3.1.2/
rm -rf apache-hive-3.1.2.tar.gz
scp -r /opt/apps/hive-3.1.2 linux03:/opt/apps/
# 这里只需要配置 hive-env.sh
# linux02 linux03
cp /opt/apps/hive-3.1.2/conf/hive-env.sh.template /opt/apps/hive-3.1.2/conf/hive-env.sh
vim /opt/apps/hive-3.1.2/conf/hive-env.sh
export HADOOP_HOME=/opt/apps/hadoop-3.1.1
export HIVE_CONF_DIR=/opt/apps/hive-3.1.2/conf
export HIVE_AUX_JARS_PATH=/opt/apps/hive-3.1.2/lib
vim /opt/apps/hive-3.1.2/conf/hive-site.xml
# 需要在hive-site.xml中配置 元数据服务的地址 其他什么都不需要配置了
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://linux01:9083</value>
</property>
</configuration>
# 之后就可以直接访问
# 注意若没有配置hive环境变量 则需要到/opt/apps/hive-3.1.2/bin 下使用hive命令
cd /opt/apps/hive-3.1.2/bin
./hive
第二代客户端Beeline
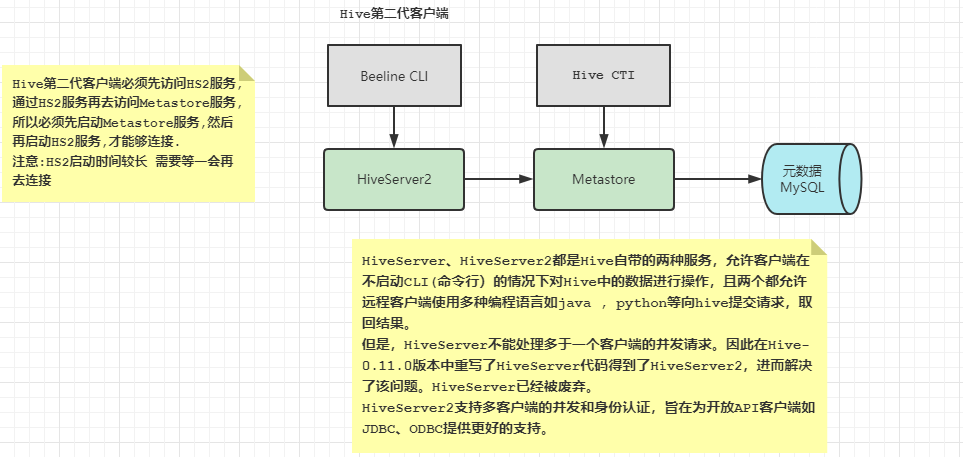
本地访问
# 先启动Metastore服务 如果已经启动可以忽视
nohup hive --service metastore &
# 然后才启动hiveserver2服务 端口号10000 在hive-site.xml中进行的配置
nohup hive --service hiveserver2 &
# 启动后可以使用 来进行验证 检查10000端口
netstat -nltp | grep 10000
# 查看WEB页面http://linux01:10002/
# 使用beeline命令 进入后输入相关连接的uri
!connect jdbc:hive2://linux01:10000
# 需要输入用户名 root 密码为空 不输入 直接回车
# 退出命令 !quit 或者直接ctrl+c
# 也可以直接以下命令进行连接
# beeline -u jdbc:hive2://linux01:10000 -n root
远程访问
# 使用其他计算机访问的话首先保证 linux01的Metastore和 hiveserver2都已经启动
# linux02 和 linux03 上传 hive的压缩包并解压
# linux02
tar -zxf apache-hive-3.1.2.tar.gz
mv apache-hive-3.1.2-bin/ /opt/apps/hive-3.1.2/
rm -rf apache-hive-3.1.2.tar.gz
scp -r /opt/apps/hive-3.1.2 linux03:/opt/apps/
# 这里只需要配置 hive-env.sh
# linux02 linux03
cp /opt/apps/hive-3.1.2/conf/hive-env.sh.template /opt/apps/hive-3.1.2/conf/hive-env.sh
vim /opt/apps/hive-3.1.2/conf/hive-env.sh
export HADOOP_HOME=/opt/apps/hadoop-3.1.1
export HIVE_CONF_DIR=/opt/apps/hive-3.1.2/conf
export HIVE_AUX_JARS_PATH=/opt/apps/hive-3.1.2/lib
# 由于不直接访问Metastore 所以不需要配置hive-site.xml 直接使用beeline正常访问即可
非交互式操作
不进入到hive中 直接执hql语句或者hql文件 ,执行完毕后返回linux命令行
使用 –e 参数来直接执行hql的语句
hive -e "show databases;"
使用 –f 参数通过指定文本文件来执行hql的语句
vi a.sql
show databases;
# 执行sql文件
hive -f a.sql
# 执行sql文件 将执行结果写入到另一个文件中
hive -f a.sql > b.sql
Hive可视化工具
DBeaver和idea都可以对hive进行连接
都需要添加jdbc驱动
DBeaver社区版,开源免费.
idea提示很好
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











