







1.1 流式计算简介
大数据中的计算通常可以分为哪三大类呢?
1、一种是离线数据(T+1,周、月、季度、年等指标)
2、一种是实时数据(一条数据触发一次计算、较短时间触发一次计算、最近几秒、最近几分钟、最近几十分钟)
3、一种是准实时(交互式)(较短时间触发一次计算、最近几分钟、最近几十分钟)
三种其实在业界界定都很模糊,但是也相对清晰。通常是根据数据从产生到被计算的时间间隔,如果间隔越小就越接近实时,越大越接近离线。
1.1.1 流式计算
如何去理解流式计算,最形象的例子,就是商城的扶梯或者直梯的案例。流式计算就像电梯里的人流一样,数据连绵不断的产生,并被快速计算或分析,所以流式计算拥有如下一些特点:
-
数据是无界的(unbounded)
-
数据是动态的
-
计算速度是非常快的
-
计算不止一次
-
计算不能终止
反过来看看一下离线计算有哪些特点:
-
数据是有界的(Bounded)
-
数据静态的
-
计算速度通常较慢
-
计算只执行一次
-
计算终会终止
在大数据计算领域中,通常所说的流式计算分为了实时计算和准实时计算。所谓事实计算就是来一条记录(一个事件Event)启动一次计算;而准实时计算则是介于实时计算和离线计算之间的一个计算,所以每次处理的是一个微小的批次。
1.1.2 SparkStreaming简介
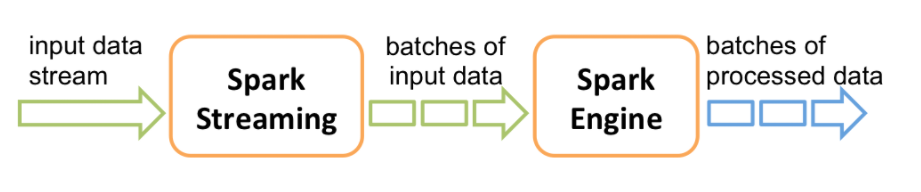
SparkStreaming,和SparkSQL一样,也是Spark生态栈中非常重要的一个模块,主要是用来进行流式计算的框架。流式计算框架,从计算的延迟上面,又可以分为纯实时流式计算和准实时流式计算,**SparkStreaming是属于的准实时计算框架**。 所谓纯实时的计算,指的是来一条记录(event事件),启动一次计算的作业;离线计算,指的是每次计算一个非常大的一批(比如几百G,好几个T)数据;准实时呢,介于纯实时和离线计算之间的一种计算方式。显然不是每一条记录就计算一次,显然比起离线计算数据量小的多,怎么表示?Micro-batch(微小的批次)。 SparkStreaming是SparkCore的api的一种扩展,使用DStream(_discretized stream_ or DStream)作为数据模型,基于内存处理连续的数据流,本质上还是RDD的基于内存的计算。 DStream,本质上是RDD的序列。SparkStreaming的处理流程可以归纳为下图:
SparkStreaming的特点
易用
Spark Streaming将Apache Spark的语言集成API引入到流处理中,使您可以像编写批处理作业一样编写流式作业。它支持Java、Scala和Python语言。
容错
Spark Streaming可以从盒子中恢复丢失的工作和操作员状态(如滑动窗口),而不需要任何额外的代码。
ps: Spark Streming可以保证每条数据只会被处理一次
易整合
通过在Spark上运行,Spark流允许您重用相同的代码进行批处理、根据历史数据连接流,或者对流状态运行即席查询。构建强大的交互式应用程序,而不仅仅是分析。
1.1.3 SparkStreaming基本工作原理
接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据,也是由一个一个的batch所组成的。
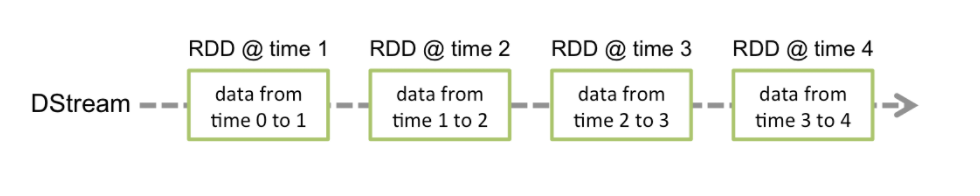
Spark Streaming提供了一种高级的抽象,叫做DStream,英文全称为Discretized Stream,中文翻译为“离散流”,它代表了一个持续不断的数据流。DStream可以通过输入数据源来创建,比如Kafka、Flume、ZMQ和Kinesis;也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window。 DStream的内部,其实一系列持续不断产生的RDD。RDD是Spark Core的核心抽象,即,分布式式弹性数据集。DStream中的每个RDD都包含了一个时间段内的数据。
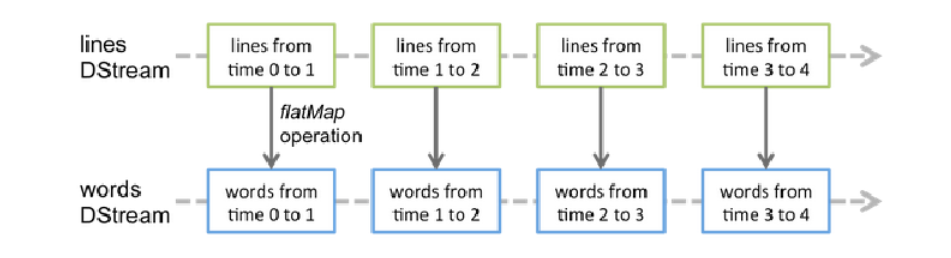
对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。但是,在底层,其实其原理为,对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。底层的RDD的transformation操作。 还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次的API。
1.1.4 Storm V.S. SparkStreaming V.S. Flink
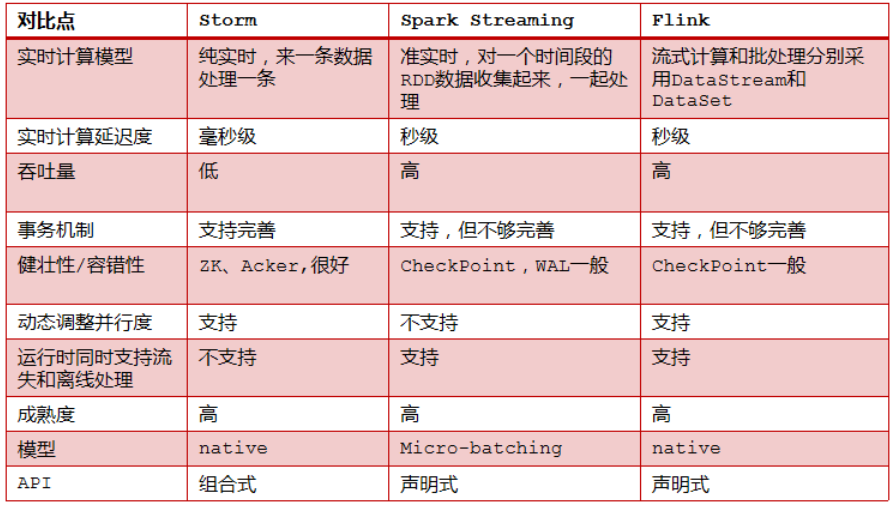
1.1.5 如何选择一款合适的流式处理框架
-
对于Storm来说:
1、建议在需要纯实时,不能忍受1秒以上延迟的场景下使用,比如实时计算系统,要求纯实时进行交易和分析时。
2、在实时计算的功能中,要求可靠的事务机制和可靠性机制,即数据的处理完全精准,一条也不能多,一条也不能少,也可以考虑使用Storm,但是Spark Streaming也可以保证数据的不丢失。
3、如果我们需要考虑针对高峰低峰时间段,动态调整实时计算程序的并行度,以最大限度利用集群资源(通常是在小型公司,集群资源紧张的情况),我们也可以考虑用Storm
-
对于Spark Streaming来说:
1、不满足上述3点要求的话,我们可以考虑使用Spark Streaming来进行实时计算。
2、考虑使用Spark Streaming最主要的一个因素,应该是针对整个项目进行宏观的考虑,即,如果一个项目除了实时计算之外,还包括了离线批处理、交互式查询、图计算和MLIB机器学习等业务功能,而且实时计算中,可能还会牵扯到高延迟批处理、交互式查询等功能,那么就应该首选Spark生态,用Spark Core开发离线批处理,用Spark SQL开发交互式查询,用Spark Streaming开发实时计算,三者可以无缝整合,给系统提供非常高的可扩展性。
-
对于Flink来说:
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口(Window)操作
支持有状态计算的Exactly-once语义
支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
支持具有Backpressure功能的持续流模型
支持基于轻量级分布式快照(Snapshot)实现的容错
一个运行时同时支持Batch on Streaming处理和Streaming处理
Flink在JVM内部实现了自己的内存管理
支持迭代计算
支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存

















 2083
2083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











