







目录
作业截图
1.在茴香豆 Web 版中创建自己领域的知识问答助手 笔记




2.在 InternLM Studio 上部署茴香豆技术助手 笔记

3.进阶1搭建个人工作助手或者垂直领域问答助手
课程笔记
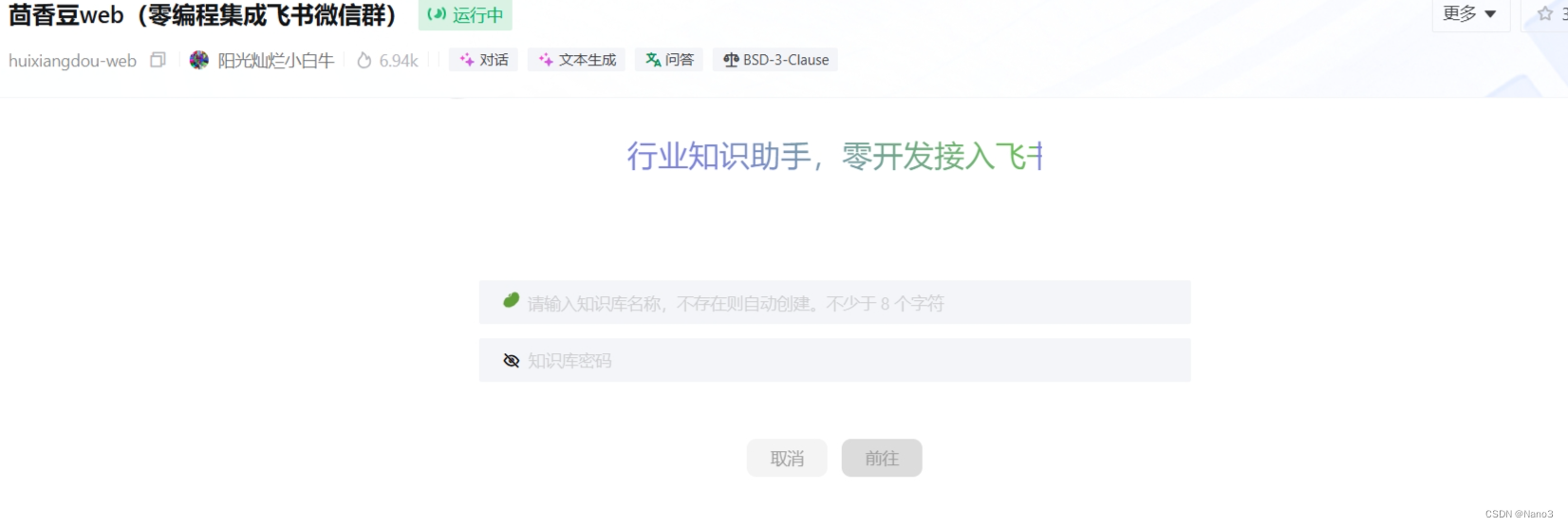
在茴香豆 Web 中创建知识问答助手
首先打开茴香豆web,创建自己的知识库,建议自己备份知识库名称和密码。
然后添加文档,因为最近很喜欢看b站算塔罗牌,所以想整个赛博算命。
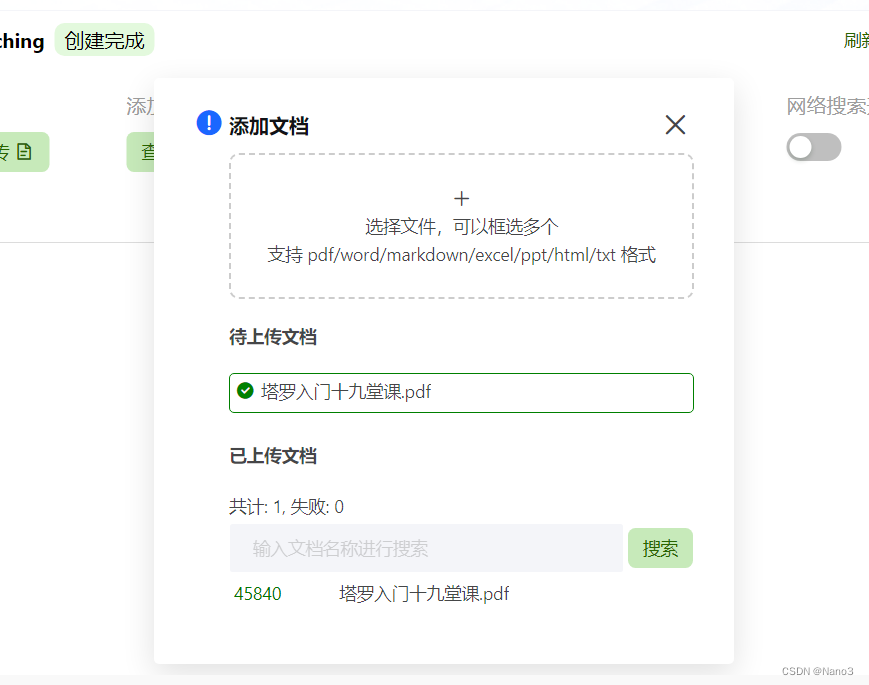
不过从作业截图1看来还是有很大提升空间,也可能是给的文档太乱了,并不像“正经”算塔罗牌的样子。
InternLM Studio 上部署茴香豆技术助手(茴香豆工作流介绍)
同样因为视频教程和github的tutorial都很清楚详细,所以不再截图部署过程。tutorial里还有茴香豆的文件结构解释,非常清楚。
./huixiangdou
├── __init__.py
├── frontend # 存放茴香豆前端与用户端和通讯软件交互代码
│ ├── __init__.py
│ ├── lark.py
│ └── lark_group.py
├── main.py # 运行主贷
├── service # 存放茴香豆后端工作流代码
│ ├── __init__.py
│ ├── config.py #
│ ├── feature_store.py # 数据嵌入、特征提取代码
│ ├── file_operation.py
│ ├── helper.py
│ ├── llm_client.py
│ ├── llm_server_hybrid.py # 混合模型代码
│ ├── retriever.py # 检索模块代码
│ ├── sg_search.py # 增强搜索,图检索代码
│ ├── web_search.py # 网页搜索代码
│ └── worker.py # 主流程代码
└── version.py
以下内容来自茴香豆的两篇技术报告 2401.08772 和 2405.02817,源码以及个人理解。
下图是茴香豆的工作流(来自 2401.08772 )
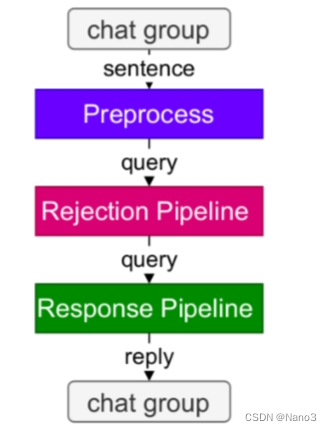
在BreadcrumbsHuixiangDou/huixiangdou/service/worker.py中generate函数可以看到pipeline的构成:
# build pipeline
preproc = PreprocNode(self.config, self.llm, self.language)
text2vec = BCENode(self.config, self.llm, self.retriever, self.language)
websearch = WebSearchNode(self.config, self.config_path, self.llm, self.language)
sgsearch = SGSearchNode(self.config, self.config_path, self.llm, self.language)
check = SecurityNode(self.llm, self.language)
pipeline = [preproc, text2vec, websearch, sgsearch]
Preprocess
PreprocNode is for coreference resolution and scoring based on group chats.
对提问打分,判断是否是是有主题疑问句。
self.SCORING_QUESTION_TEMPLTE = '“{}”\n请仔细阅读以上内容,判断句子是否是个有主题的疑问句,结果用 0~10 表示。直接提供得分不要解释。\n判断标准:有主语谓语宾语并且是疑问句得 10 分;缺少主谓宾扣分;陈述句直接得 0 分;不是疑问句直接得 0 分。直接提供得分不要解释。'
查看多条消息是否可以合并为一条,是否群聊中有代词可替换
self.CR_NEED = """群聊场景中“这”、“它”、“哪”等代词需要查看上下文和其他用户的回复才能确定具体指什么,请完成群聊场景代词替换任务。
以下是历史对话,可能有多个人的发言:
{}
输入内容:{}
输入内容的信息是否完整,是否需要从历史对话中提取代词或宾语来替代 content 中的一部分词汇? A:不需要提取,信息完整 B:需要 C:不知道
一步步分析,首先历史消息包含哪些话题;其次哪个话题与问题最相关;如果都不相关就不提取。"""
self.CR = """请根据历史对话,重写输入的文本。
以下是历史对话,可能有多个人的发言:
{}
输入的文本
“{}”
一步步分析,首先历史对话包含哪些话题;其次哪个话题与输入文本中的代词最相关;用相关的话题,替换输入中的代词和缺失的部分。直接返回重写后的文本不要解释。"""

Rejection Pipeline
BCENode is for retrieve from knowledge base
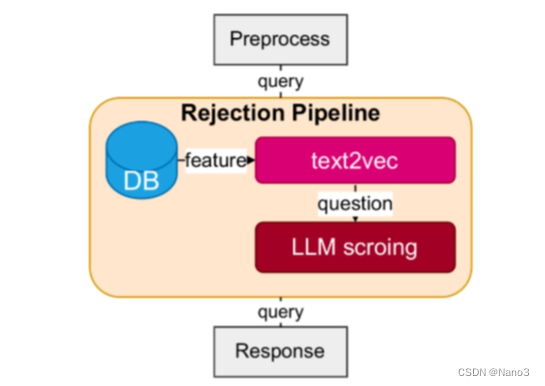
self.TOPIC_TEMPLATE = '告诉我这句话的主题,不要丢失主语和宾语,直接说主题不要解释:“{}”'
self.SCORING_RELAVANCE_TEMPLATE = '问题:“{}”\n材料:“{}”\n请仔细阅读以上内容,判断问题和材料的关联度,用0~10表示。判断标准:非常相关得 10 分;完全没关联得 0 分。直接提供得分不要解释。\n' # noqa E501
self.GENERATE_TEMPLATE = '材料:“{}”\n 问题:“{}” \n 请仔细阅读参考材料回答问题。'

RESPONSE PIPELINE
使用评分和部分排序从重新排序模型、网络搜索和知识图谱中过滤高质量的文本,为LLM生成响应。为了节省成本,混合并安排了不同的llm。建立了一套安全机制,以确保对聊天组的回复不涉及敏感话题。
里面rerank部分代码还是在上一部分的BCENode里,使用的是BCERerank。
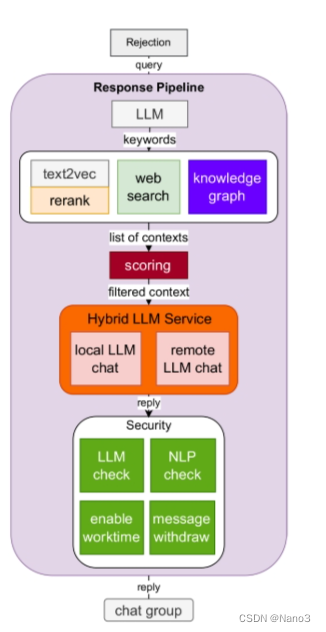
WebSearchNode is for web search, use ddgs or serper
self.SCORING_RELAVANCE_TEMPLATE = '问题:“{}”\n材料:“{}”\n请仔细阅读以上内容,判断问题和材料的关联度,用0~10表示。判断标准:非常相关得 10 分;完全没关联得 0 分。直接提供得分不要解释。\n' # noqa E501
self.KEYWORDS_TEMPLATE = '谷歌搜索是一个通用搜索引擎,可用于访问互联网、查询百科知识、了解时事新闻等。搜索参数类型 string, 内容是短语或关键字,以空格分隔。\n你现在是{}交流群里的助手,用户问“{}”,你打算通过谷歌搜索查询相关资料,请提供用于搜索的关键字或短语,不要解释直接给出关键字或短语。' # noqa E501
self.GENERATE_TEMPLATE = '材料:“{}”\n 问题:“{}” \n 请仔细阅读参考材料回答问题。' # noqa E501
现使用keywords查找相关文章:
prompt = self.KEYWORDS_TEMPLATE.format(sess.groupname, sess.query)
search_keywords = self.llm.generate_response(prompt)
sess.debug['WebSearchNode_keywords'] = prompt
articles, error = engine.get(query=search_keywords, max_article=2)
判断文章的相关性
for article_id, article in enumerate(articles):
article.cut(0, self.max_length)
prompt = self.SCORING_RELAVANCE_TEMPLATE.format(sess.query, article.brief)
# truth, logs = is_truth(llm=self.llm, prompt=prompt, throttle=5, default=10, backend='puyu')
truth, logs = is_truth(llm=self.llm, prompt=prompt, throttle=5, default=10, backend='remote')
sess.debug['WebSearchNode_relavance_{}'.format(article_id)] = logs
if truth:
sess.web_knowledge += '\n'
sess.web_knowledge += article.content
sess.references.append(article.source)
SGSearchNode is for retrieve from source graph
SecurityNode is for result check
self.SECURITY_TEMAPLTE = '判断以下句子是否涉及政治、辱骂、色情、恐暴、宗教、网络暴力、种族歧视等违禁内容,结果用 0~10 表示,不要解释直接给出得分。判断标准:涉其中任一问题直接得 10 分;完全不涉及得 0 分。直接给得分不要解释:“{}”' # noqa E501
搭建飞书群组机器人助手
1.首先在飞书开放平台,创建企业自建项目。
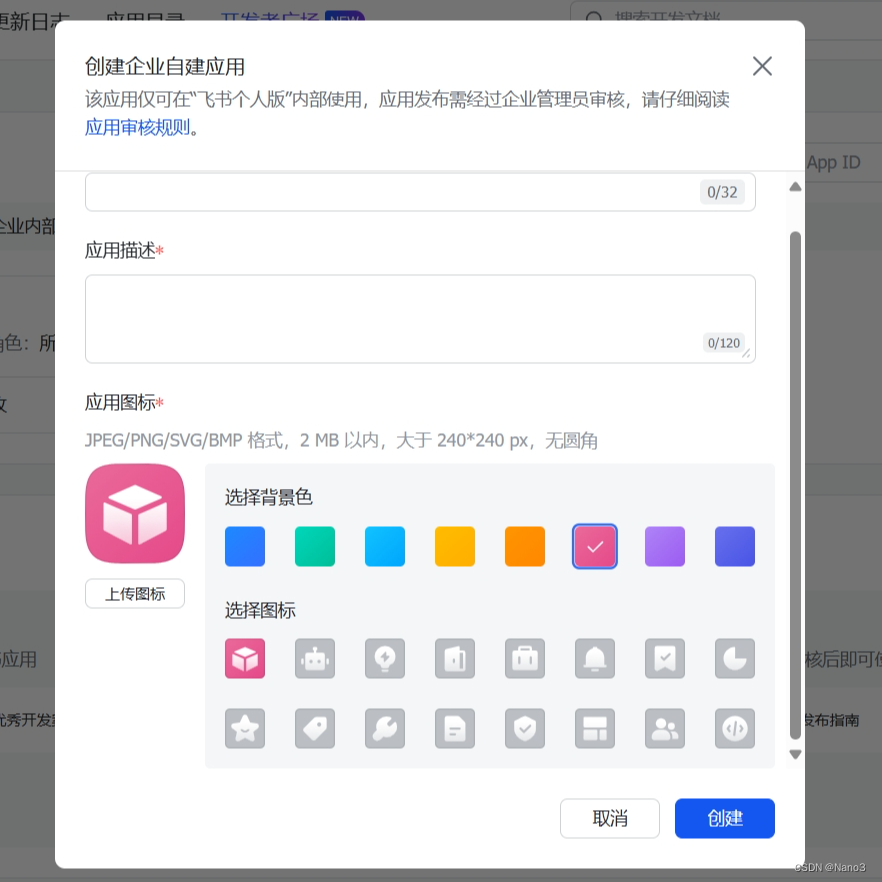
2.创建完成后,添加机器人应用,并复制App ID和App Secret。
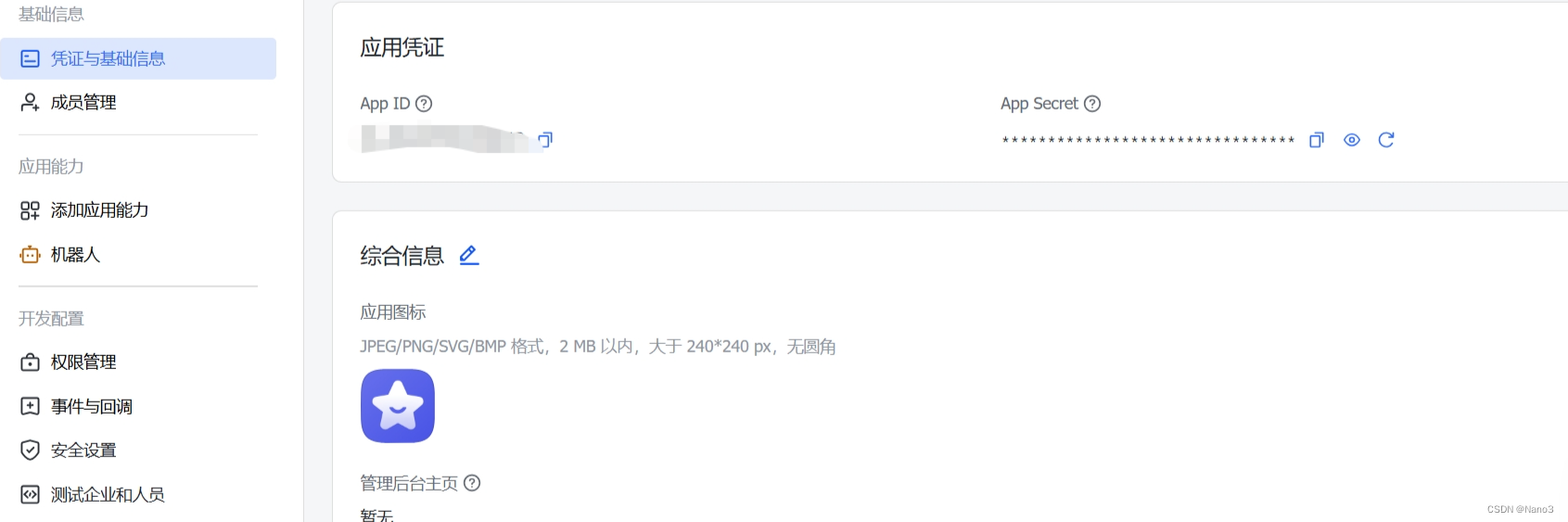
3.打开huixiangdou web,将上图的App ID和App Secret粘贴到下图对应位置。
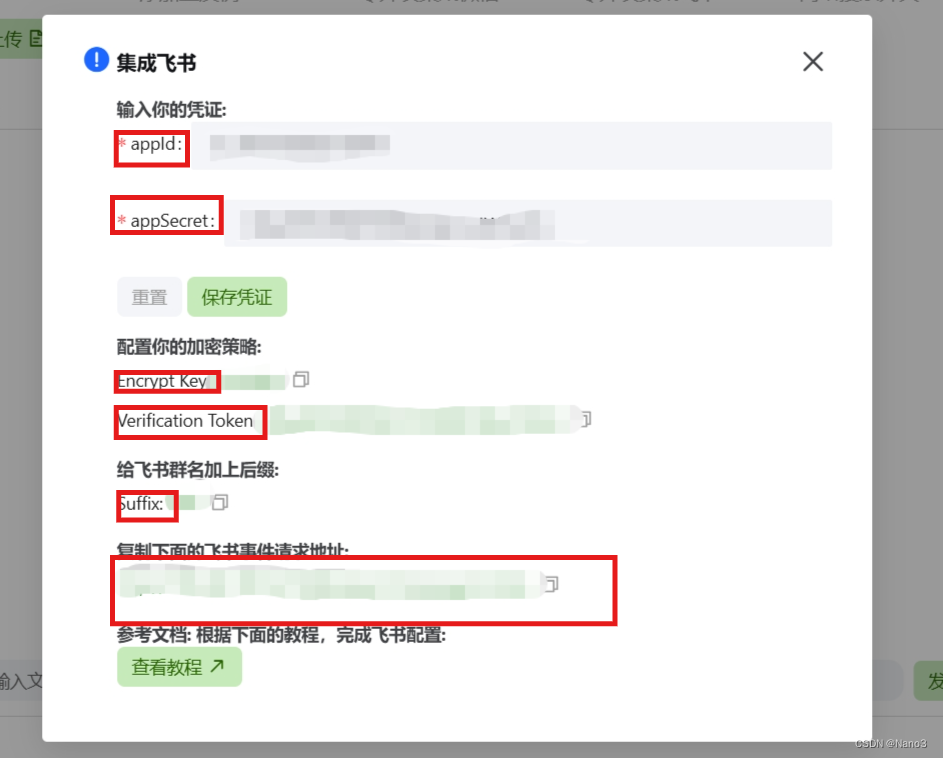
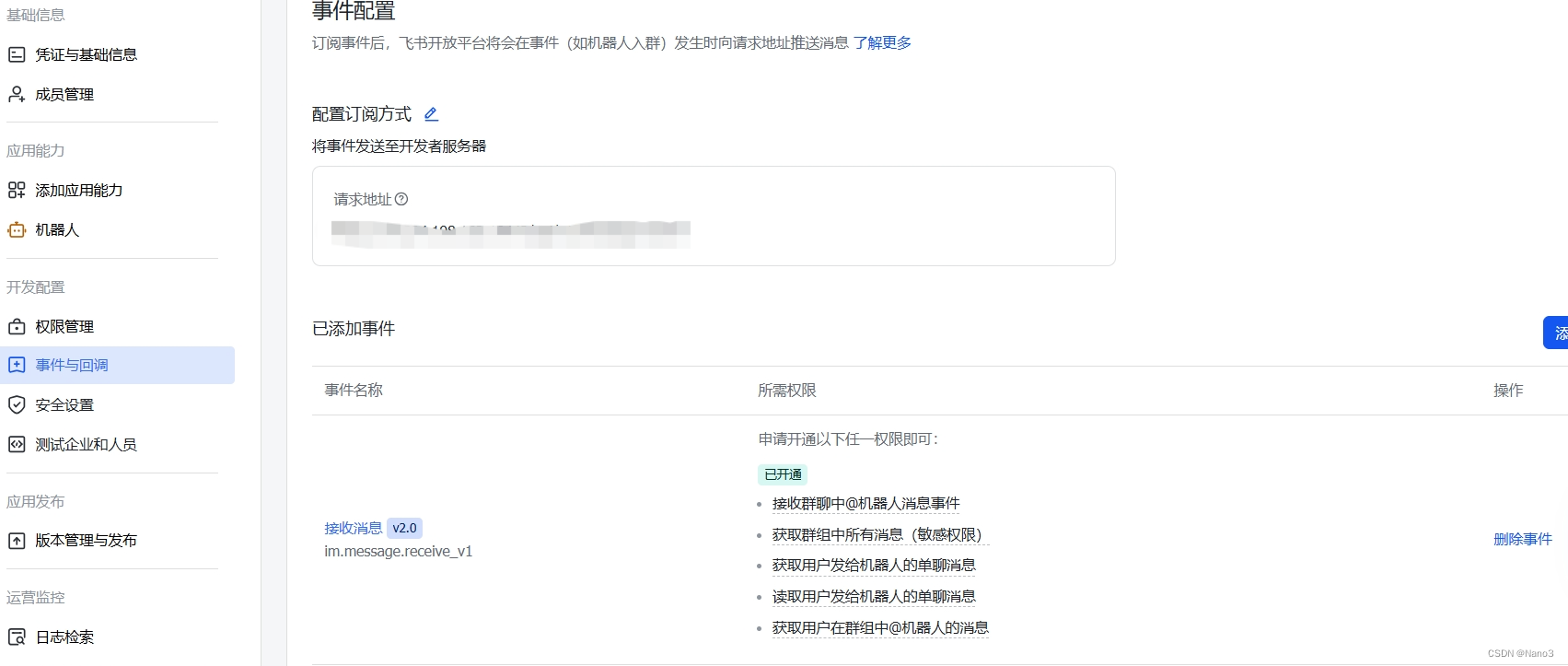
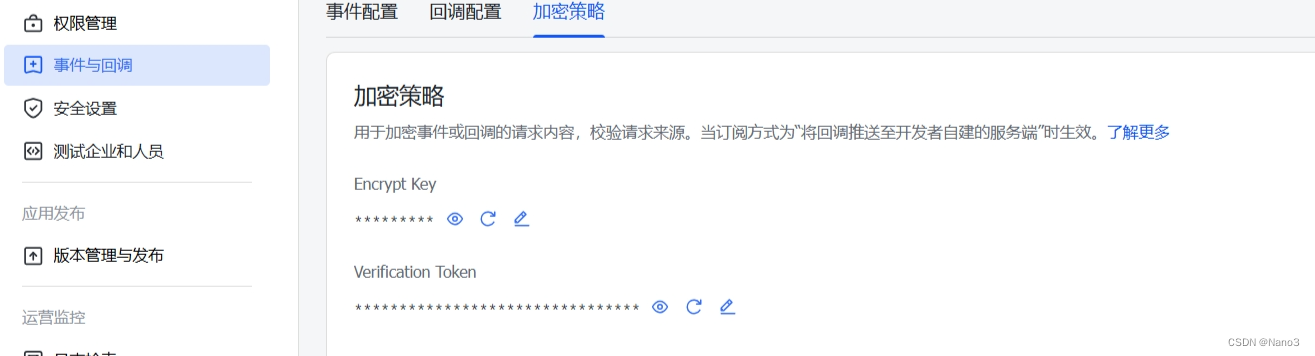
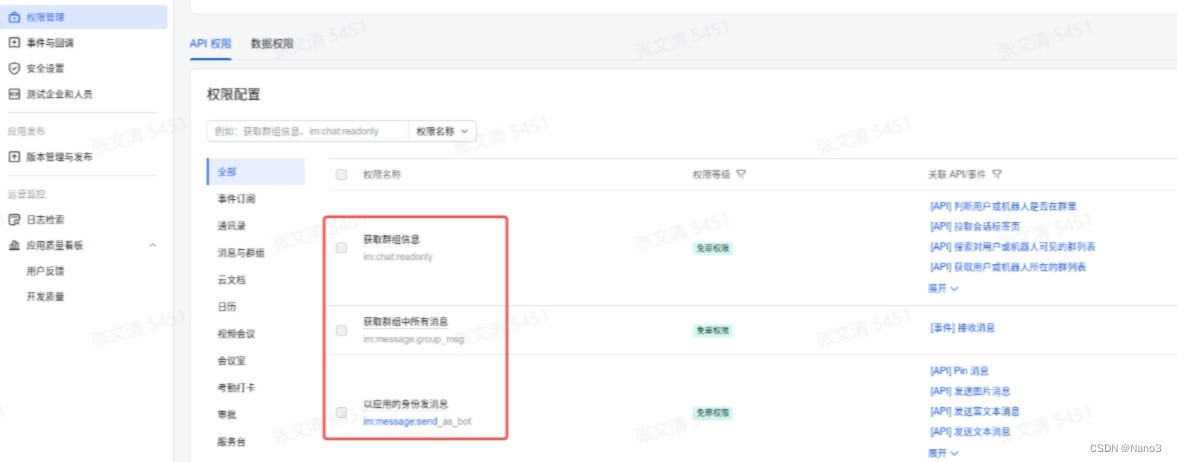
4.回到飞书开发者平台,将上图的请求地址复制到下图的请求地址,并开通以下事件和权限。
回调事件同理。
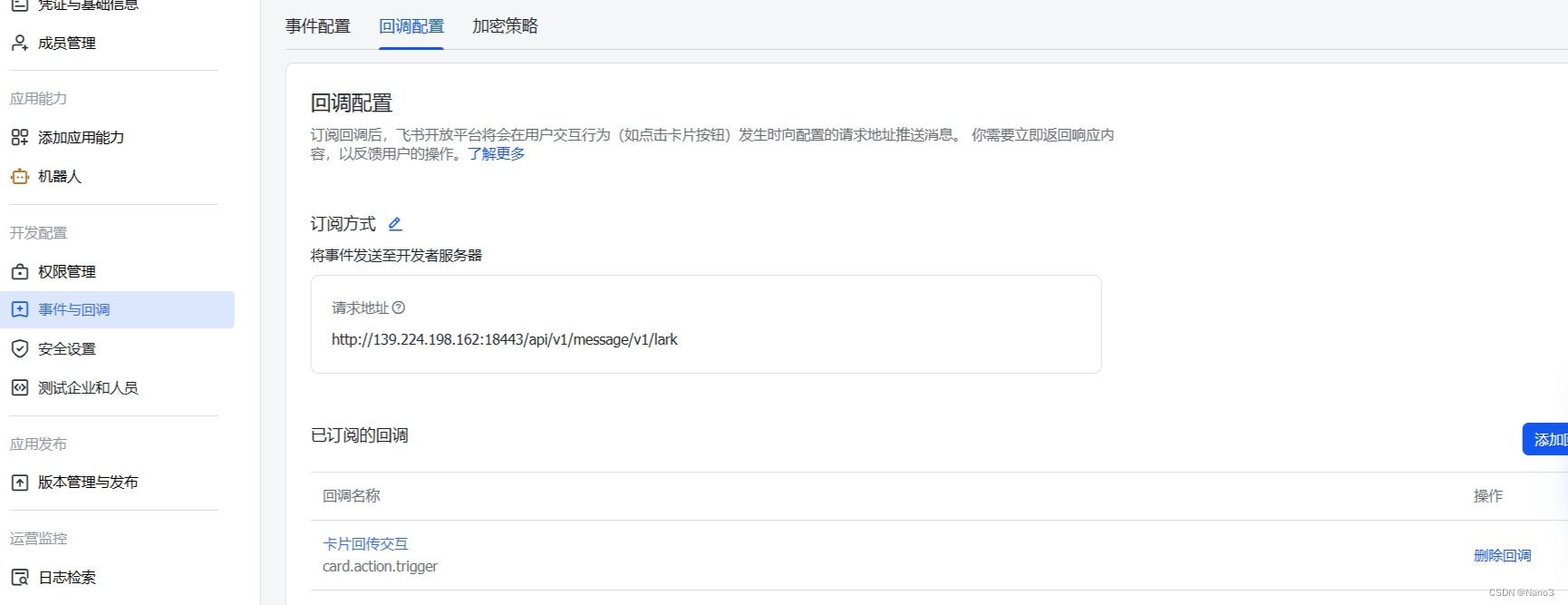
加密策略里的Key和token也都是复制huixiangdou
web里对应的。
在权限管理里开通以下权限:
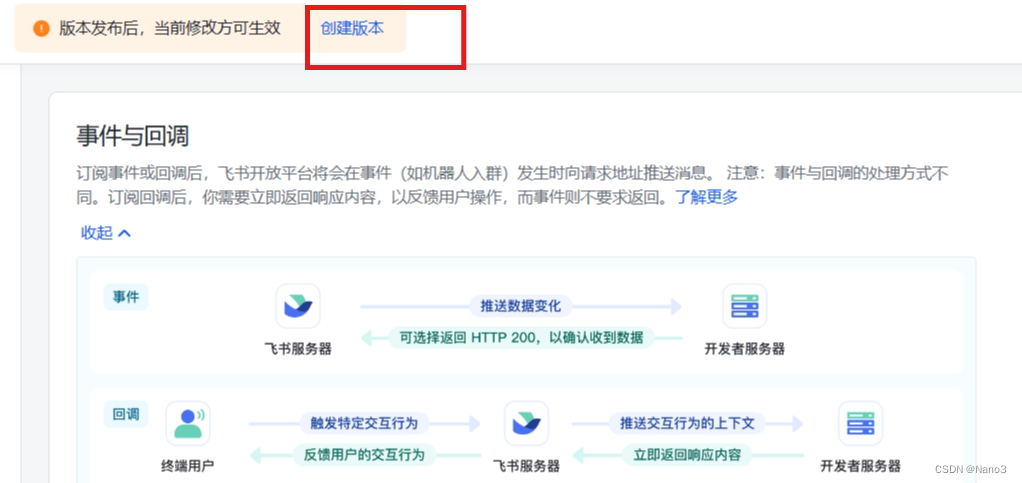
5.然后创建当前版本发布即可。
6.创建群聊并将群聊名称后加huixiangdou web的suffix,就可以在群组中@机器人聊天了。
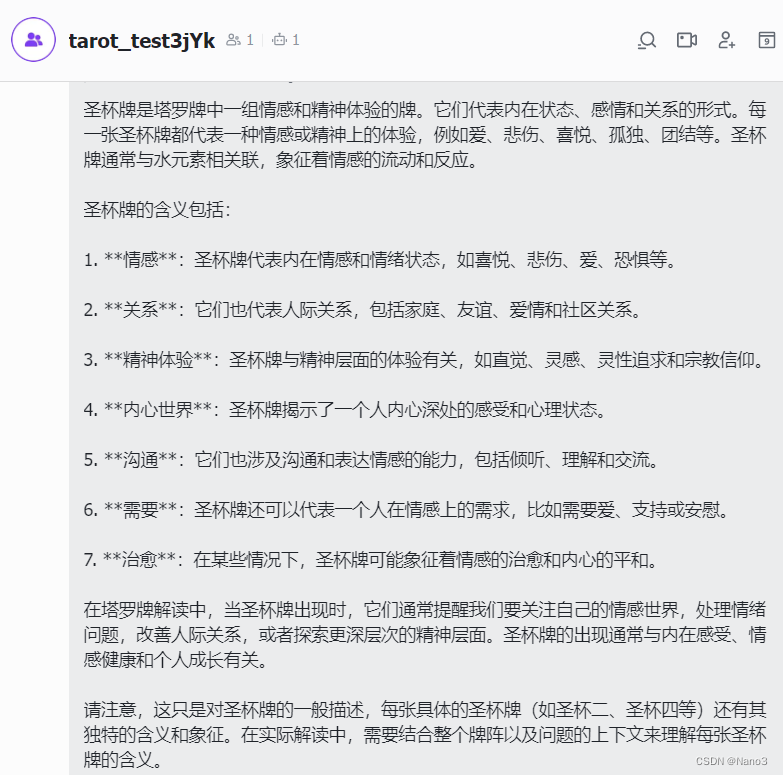
But…能在群组里@机器人聊天却无法直接和应用的机器人聊,看了好久教程也没漏过啥,so不懂了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









