







建议看视频前先把环境安装了,要不然又不知道空的那段时间干嘛了!
目录
模型部署的挑战
1.部署到服务器,服务器类型多(CPU,GPU,TPU),部署到集群如何分布式推理大模型。
2.部署到移动端,如何在有限的资源加载推理大模型。
3.计算量大

4.内存开销大
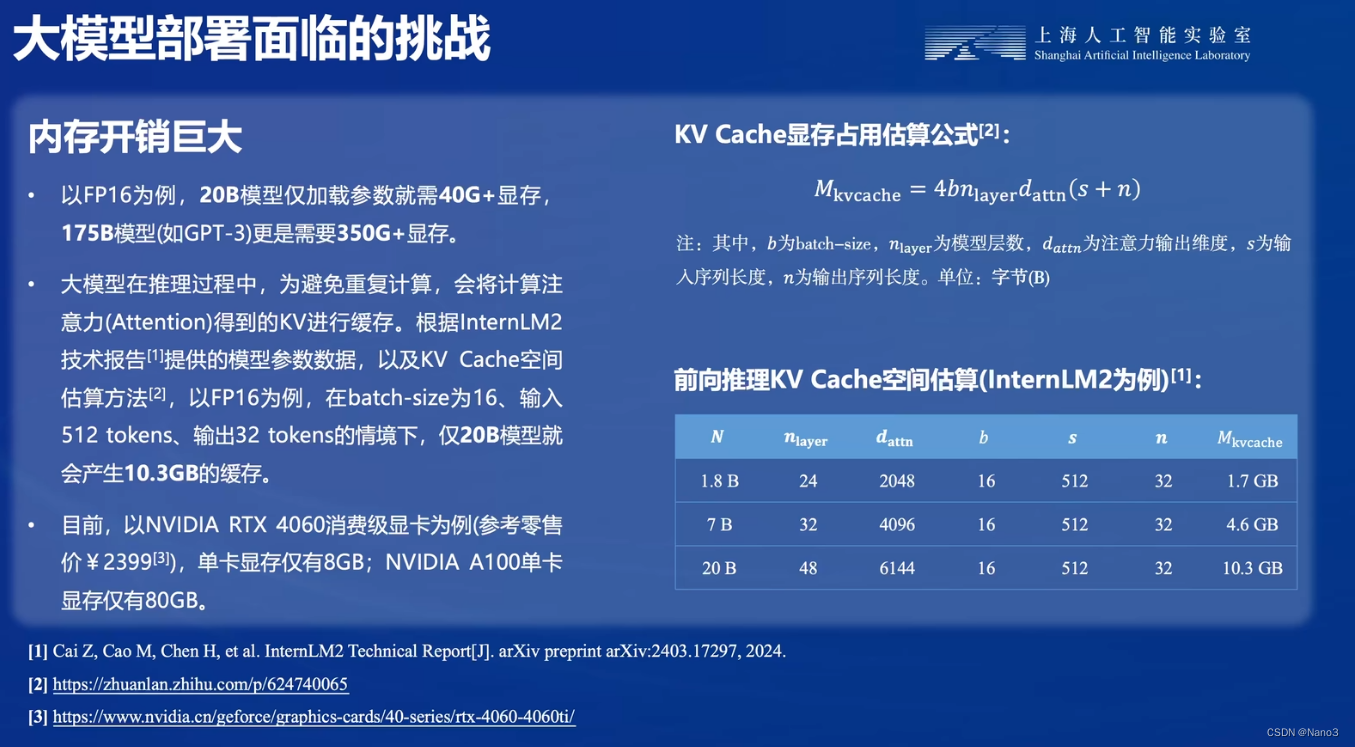
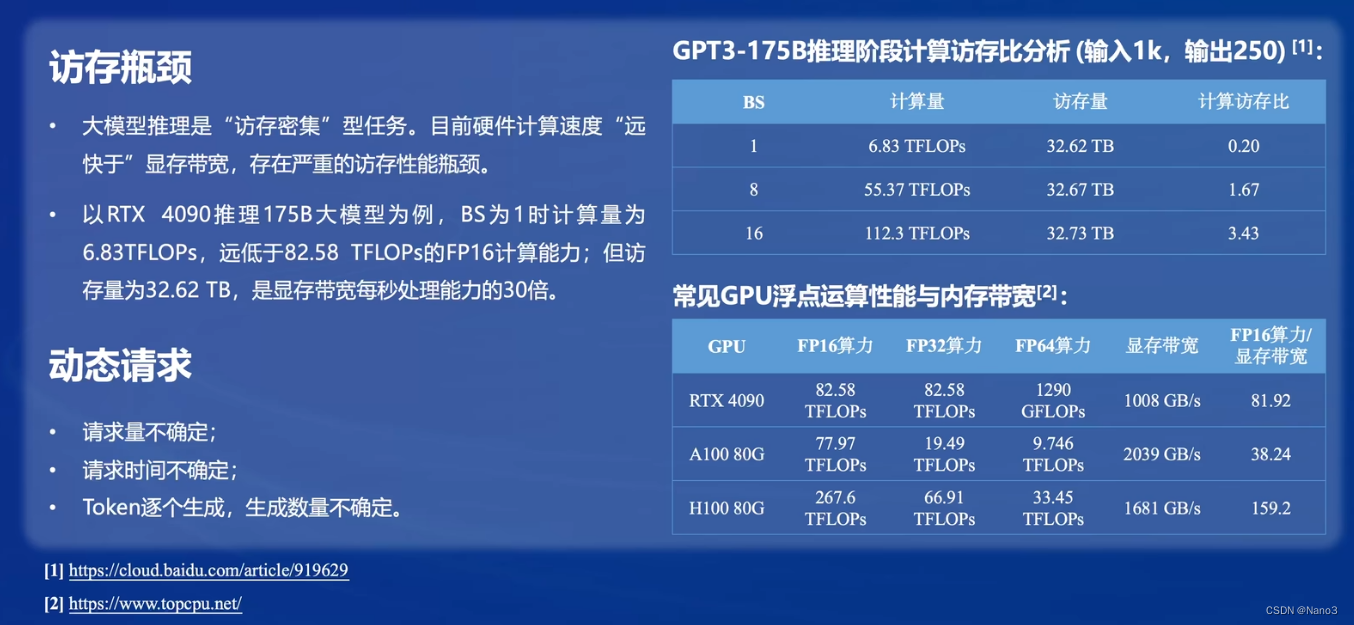
5.访存瓶颈
放存量大
部署方法
1.剪枝

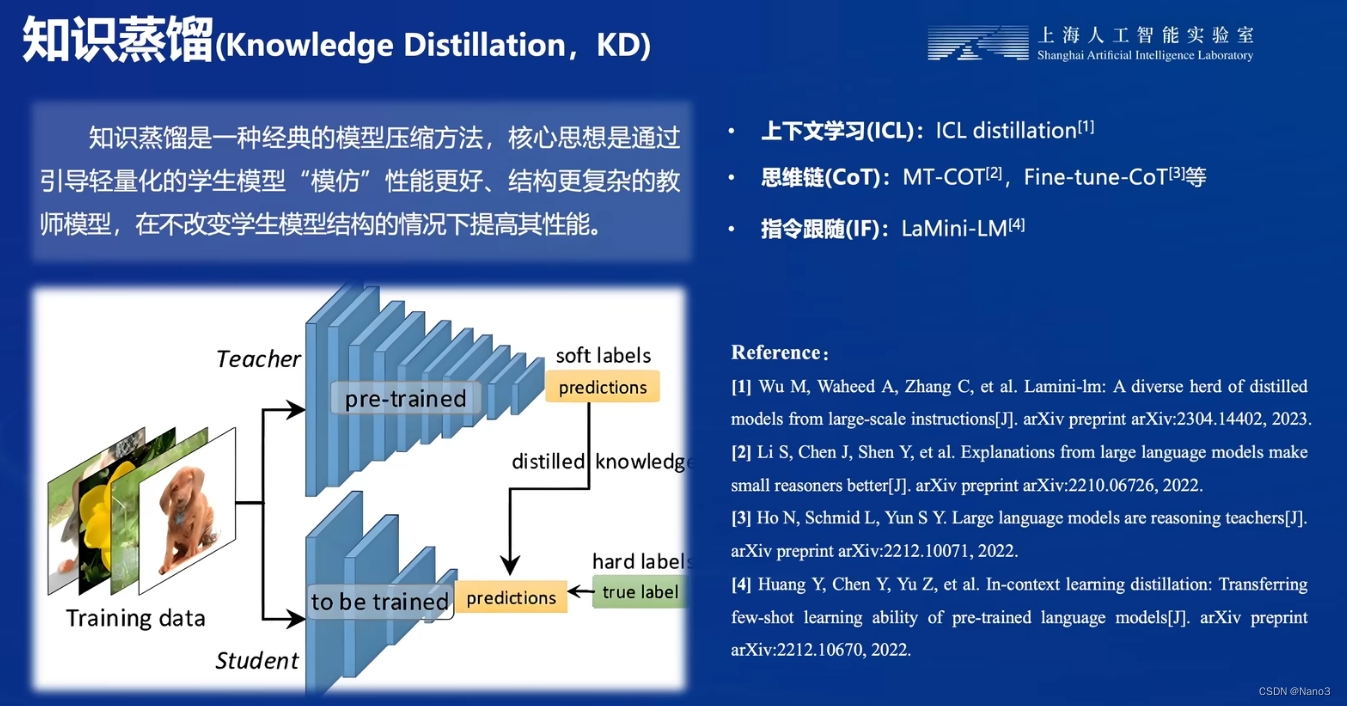
2.知识蒸馏
3.量化

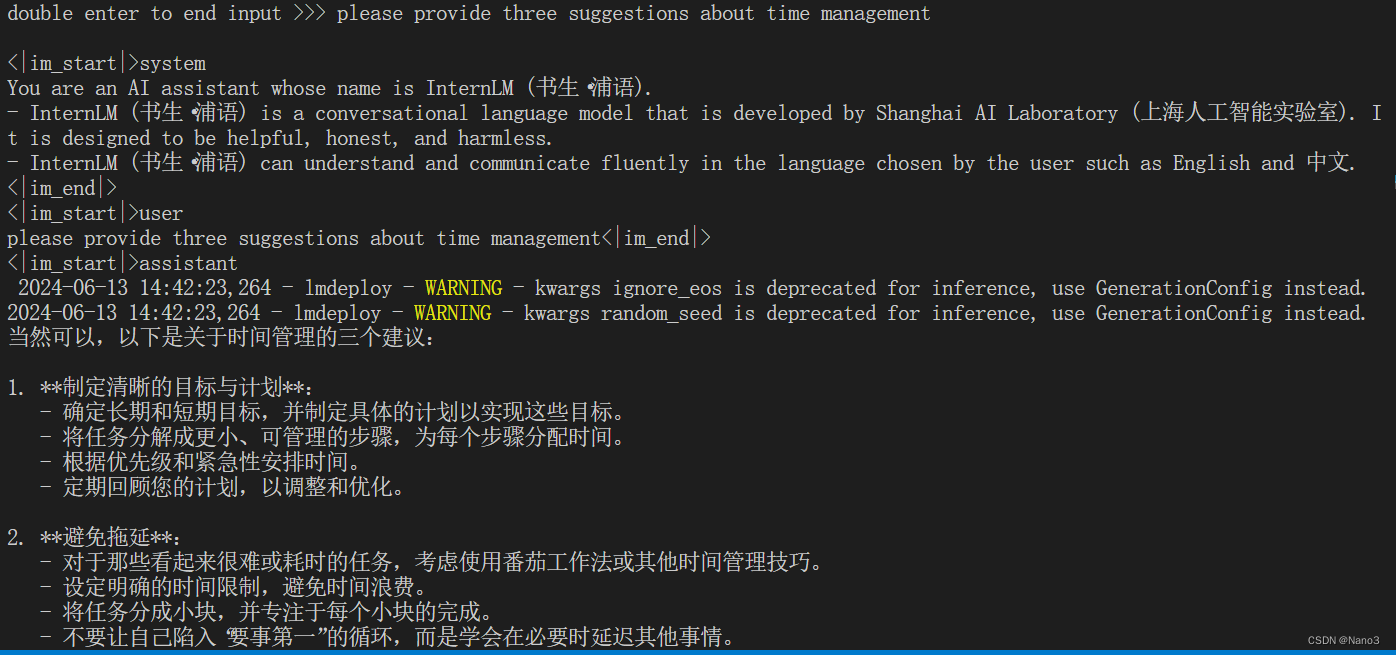
配置 LMDeploy 运行环境,以命令行方式与模型对话

使用Transformer库运行模型,是有点慢的

执行完整个程序需要大概一分钟
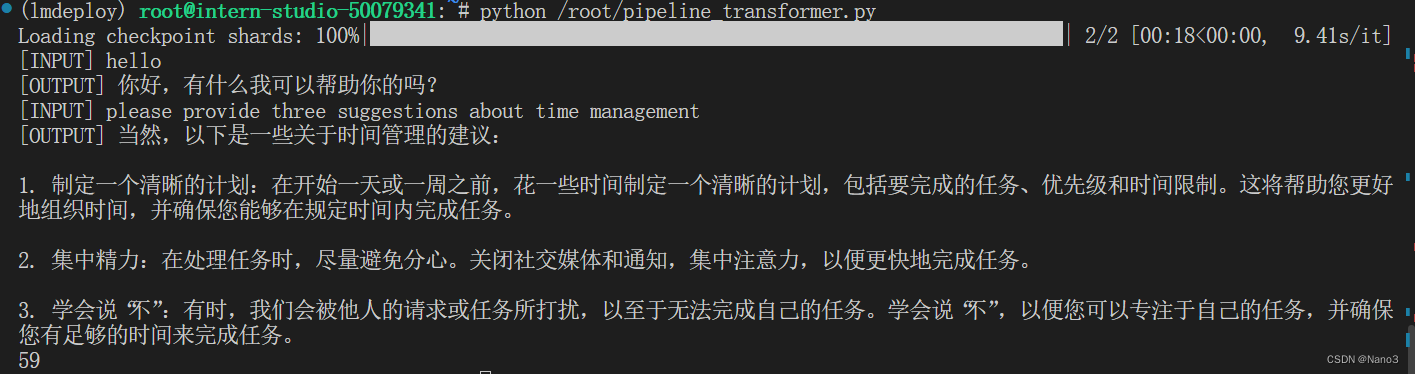
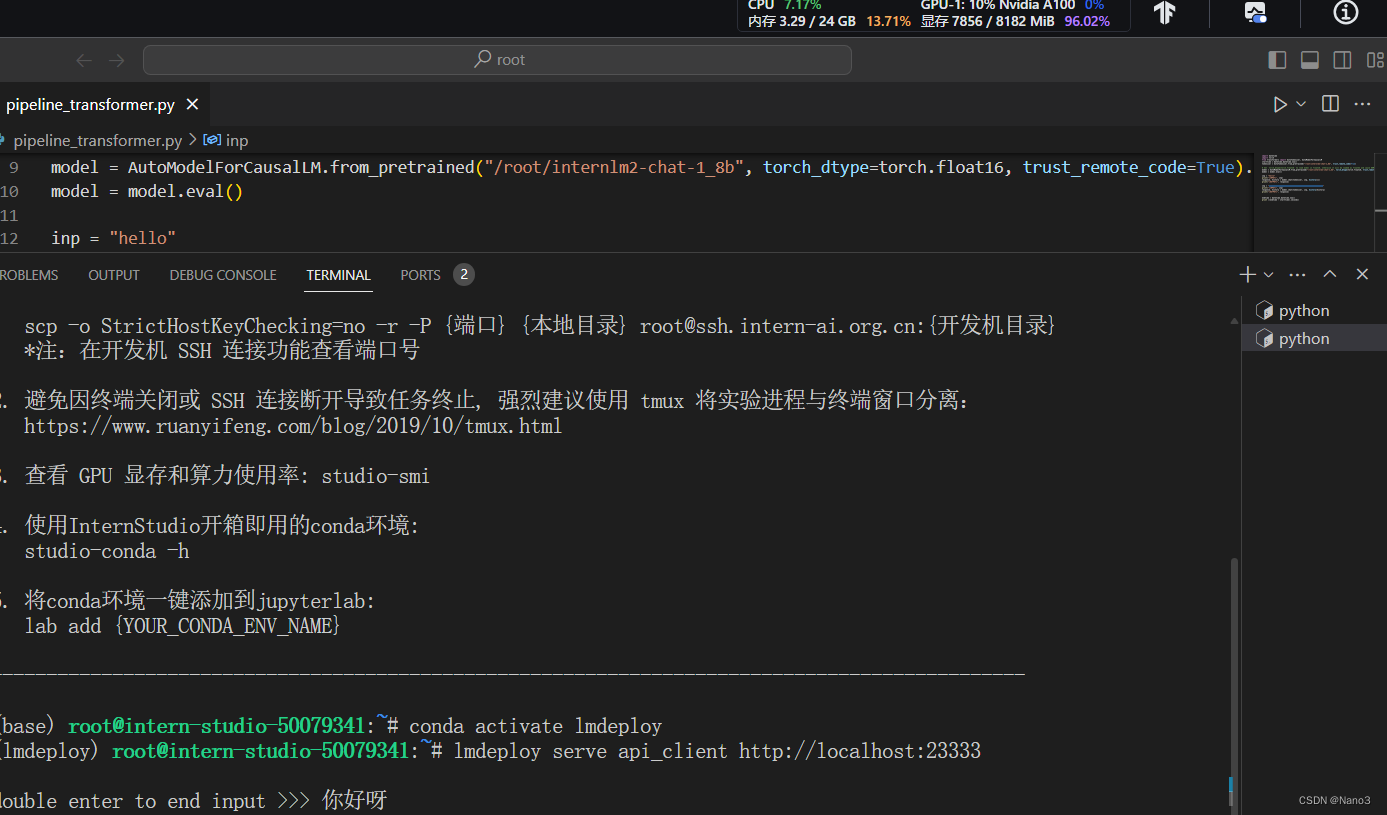
以命令行方式与 InternLM2-Chat-1.8B 模型对话(记得按两下回车)
快不少,沉默的时间也比刚才短多了。
lmdeploy chat -h查看更多的功能,如下:
usage: lmdeploy chat [-h] [--backend {pytorch,turbomind}] [--trust-remote-code] [--meta-instruction META_INSTRUCTION]
[--cap {completion,infilling,chat,python}] [--adapters [ADAPTERS ...]] [--tp TP]
[--model-name MODEL_NAME] [--session-len SESSION_LEN] [--max-batch-size MAX_BATCH_SIZE]
[--cache-max-entry-count CACHE_MAX_ENTRY_COUNT] [--model-format {hf,llama,awq}]
[--quant-policy QUANT_POLICY] [--rope-scaling-factor ROPE_SCALING_FACTOR]
model_path
Chat with pytorch or turbomind engine.
positional arguments:
model_path The path of a model. it could be one of the following options: - i) a local directory path of a
turbomind model which is converted by `lmdeploy convert` command or download from ii) and iii). -
ii) the model_id of a lmdeploy-quantized model hosted inside a model repo on huggingface.co, such
as "internlm/internlm-chat-20b-4bit", "lmdeploy/llama2-chat-70b-4bit", etc. - iii) the model_id of
a model hosted inside a model repo on huggingface.co, such as "internlm/internlm-chat-7b",
"qwen/qwen-7b-chat ", "baichuan-inc/baichuan2-7b-chat" and so on. Type: str
options:
-h, --help show this help message and exit
--backend {pytorch,turbomind}
Set the inference backend. Default: turbomind. Type: str
--trust-remote-code Trust remote code for loading hf models. Default: True
--meta-instruction META_INSTRUCTION
System prompt for ChatTemplateConfig. Deprecated. Please use --chat-template instead. Default:
None. Type: str
--cap {completion,infilling,chat,python}
The capability of a model. Deprecated. Please use --chat-template instead. Default: chat. Type: str
PyTorch engine arguments:
--adapters [ADAPTERS ...]
Used to set path(s) of lora adapter(s). One can input key-value pairs in xxx=yyy format for
multiple lora adapters. If only have one adapter, one can only input the path of the adapter..
Default: None. Type: str
--tp TP GPU number used in tensor parallelism. Should be 2^n. Default: 1. Type: int
--model-name MODEL_NAME
The name of the to-be-deployed model, such as llama-7b, llama-13b, vicuna-7b and etc. You can run
`lmdeploy list` to get the supported model names. Default: None. Type: str
--session-len SESSION_LEN
The max session length of a sequence. Default: None. Type: int
--max-batch-size MAX_BATCH_SIZE
Maximum batch size. Default: 128. Type: int
--cache-max-entry-count CACHE_MAX_ENTRY_COUNT
The percentage of gpu memory occupied by the k/v cache. Default: 0.8. Type: float
TurboMind engine arguments:
--tp TP GPU number used in tensor parallelism. Should be 2^n. Default: 1. Type: int
--model-name MODEL_NAME
The name of the to-be-deployed model, such as llama-7b, llama-13b, vicuna-7b and etc. You can run
`lmdeploy list` to get the supported model names. Default: None. Type: str
--session-len SESSION_LEN
The max session length of a sequence. Default: None. Type: int
--max-batch-size MAX_BATCH_SIZE
Maximum batch size. Default: 128. Type: int
--cache-max-entry-count CACHE_MAX_ENTRY_COUNT
The percentage of gpu memory occupied by the k/v cache. Default: 0.8. Type: float
--model-format {hf,llama,awq}
The format of input model. `hf` meaning `hf_llama`, `llama` meaning `meta_llama`, `awq` meaning the
quantized model by awq. Default: None. Type: str
--quant-policy QUANT_POLICY
Whether to use kv int8. Default: 0. Type: int
--rope-scaling-factor ROPE_SCALING_FACTOR
Rope scaling factor. Default: 0.0. Type: float
正常执行,显存占比7856/8182。
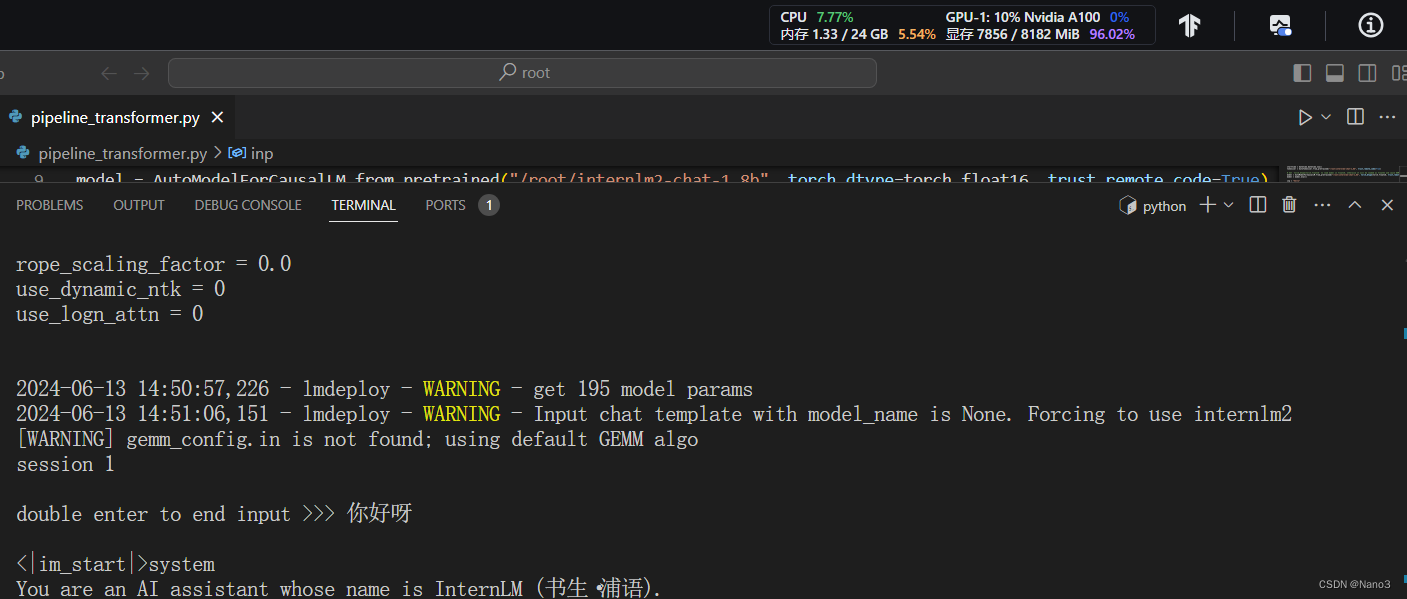
设置KV Cache为0.4+W4A16量化
1.先设置KV Cache最大占用比例为0.4,这时候显存占比6152/8182,相较于之前已经下降了一千多M。
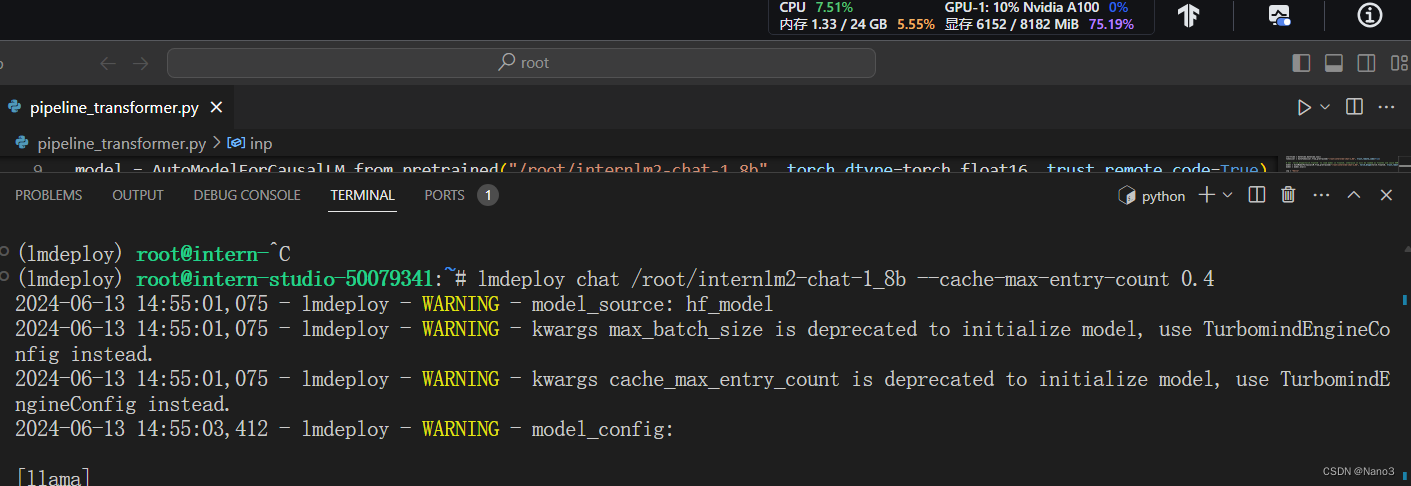
2.使用W4A16量化
lmdeploy lite auto_awq \#调用量化功能使用awq量化
/root/internlm2-chat-1_8b \#原模型路径
--calib-dataset 'ptb' \#使用ptb数据集
--calib-samples 128 \#采样128个数据对
--calib-seqlen 1024 \#上下文长度1024
--w-bits 4 \#量化的位宽,这里是 4 位
--w-group-size 128 \
--work-dir /root/internlm2-chat-1_8b-4bit #量化后输出路径
虽然视频说在开发机不需要科学上网,不过没科学上网时候下数据集还是不行。所以用开发机还是也科学上网吧。
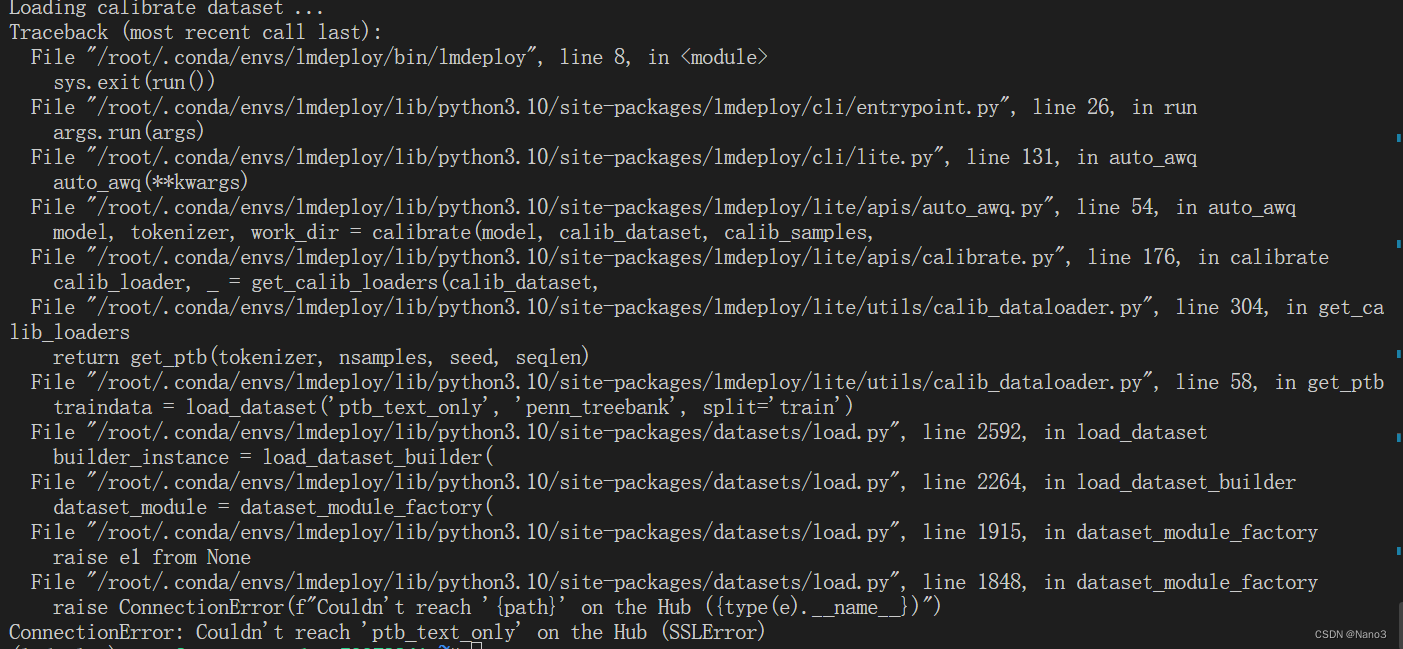
嗯开发机科学上网后就可以了。
看起来真的是一层一层的量化,这个过程有点慢。
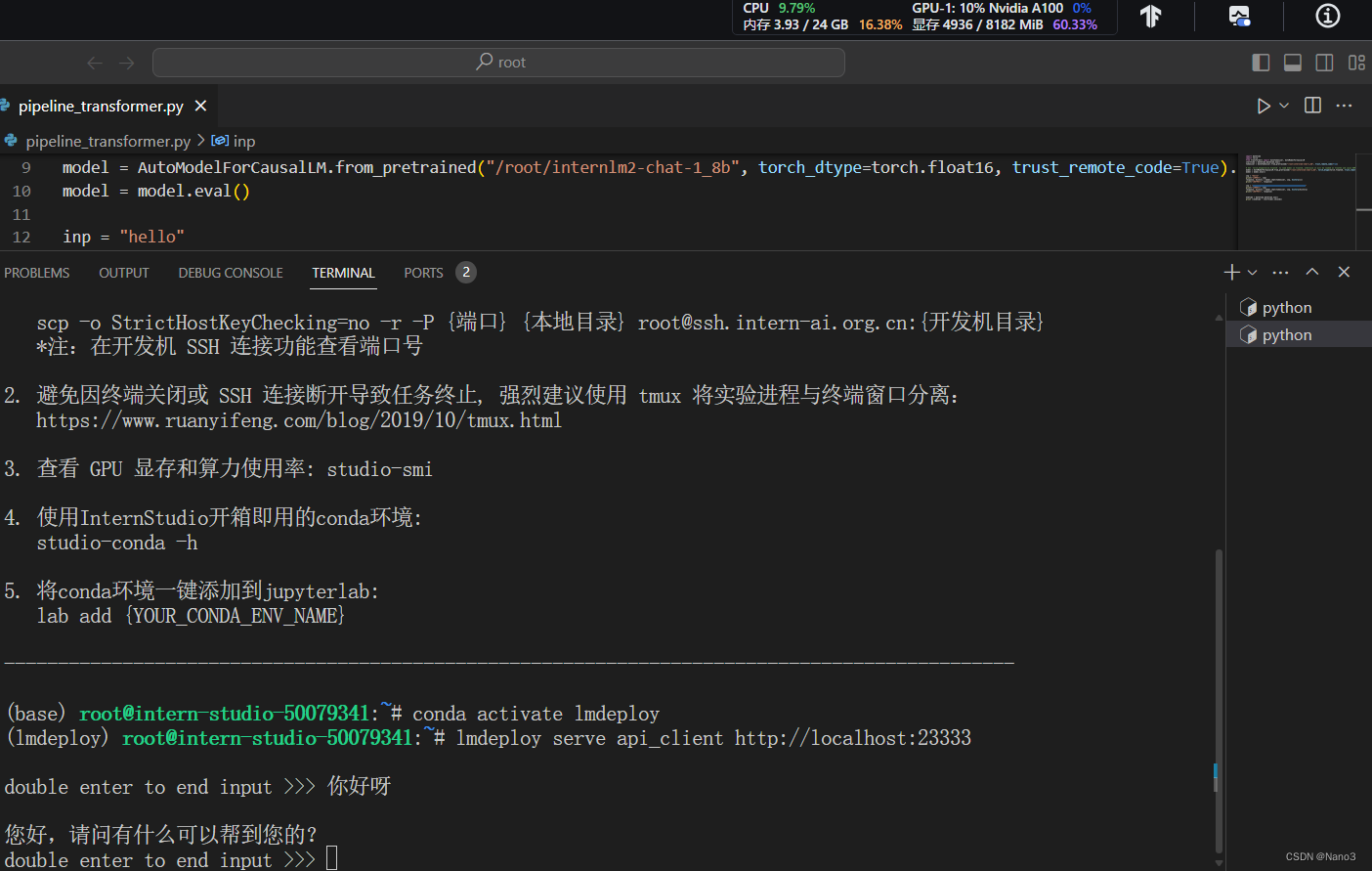
W4A16量化+KV Cache最大占用比例为0.4,4936/8182,又下降了很多,而且也很快。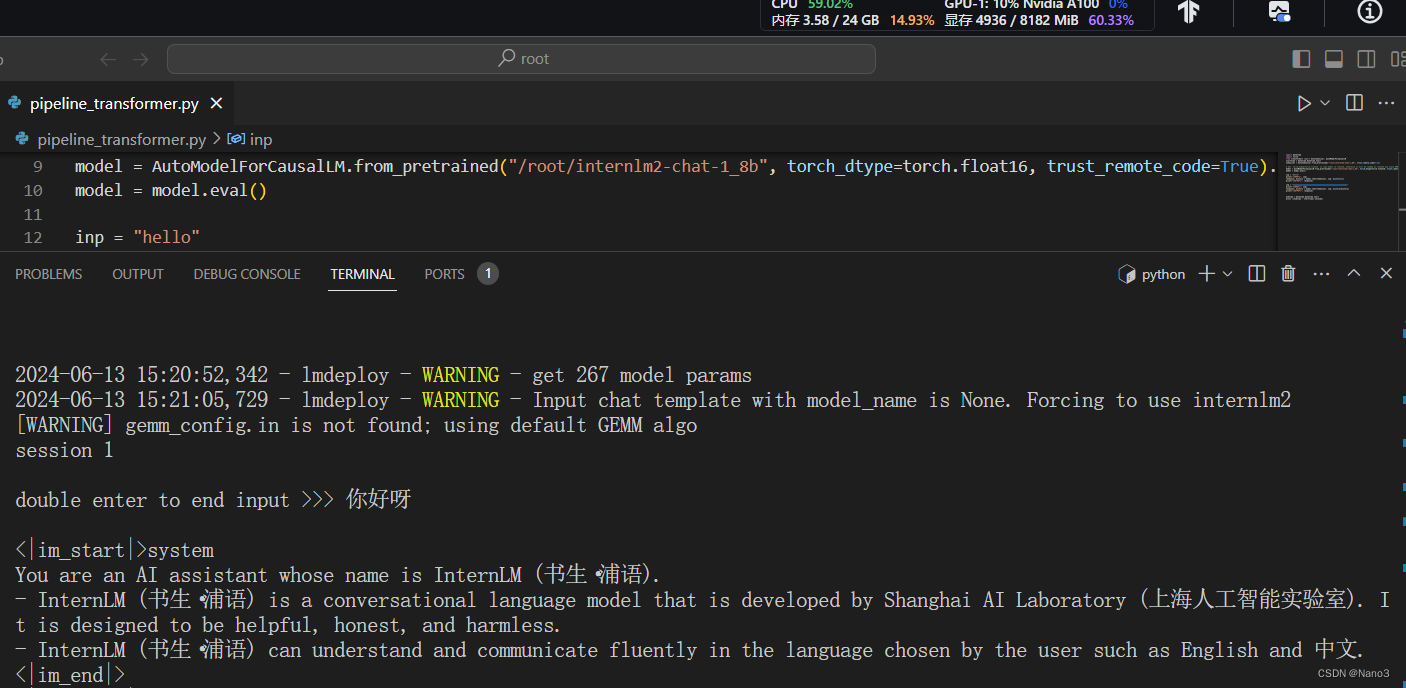
以API Server方式启动 lmdeploy量化
1.启动API服务器,推理internlm2-chat-1_8b模型
lmdeploy serve api_server \
/root/internlm2-chat-1_8b \
--model-format hf \
--quant-policy 0 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
lmdeploy serve api_server: serve 用于启动服务api_server
/root/internlm2-chat-1_8b: 语言模型的路径。
–model-format hf: 指定模型的格式为 hf
–quant-policy 0: 指定量化策略,这里的 0 表示不使用量化
–server-name 0.0.0.0: 服务ip地址
–server-port 23333: 设置服务器监听的端口号为 23333。
–tp 1: 这可能是设置线程池大小或类似的并发参数,1 表示使用单个线程。
quant-policy是0时,运行如下:
2.设置KV Cache为0.4+W4A16量化
但是作业要求以API Server方式启动 lmdeploy,开启 W4A16量化,调整KV Cache的占用比例为0.4,所以先把之前的terminal终止了,然后把上面命令中model位置,model-format和quant-policy 0 改一下,换成之前量化的命令:
lmdeploy serve api_server \
/root/internlm2-chat-1_8b-4bit \
--model-format awq \
--cache-max-entry-count 0.4 \
--server-name 0.0.0.0 \
--server-port 23333 \
--tp 1
好啦这个时候使用命令行提问时的显存也是4936/8182啦。
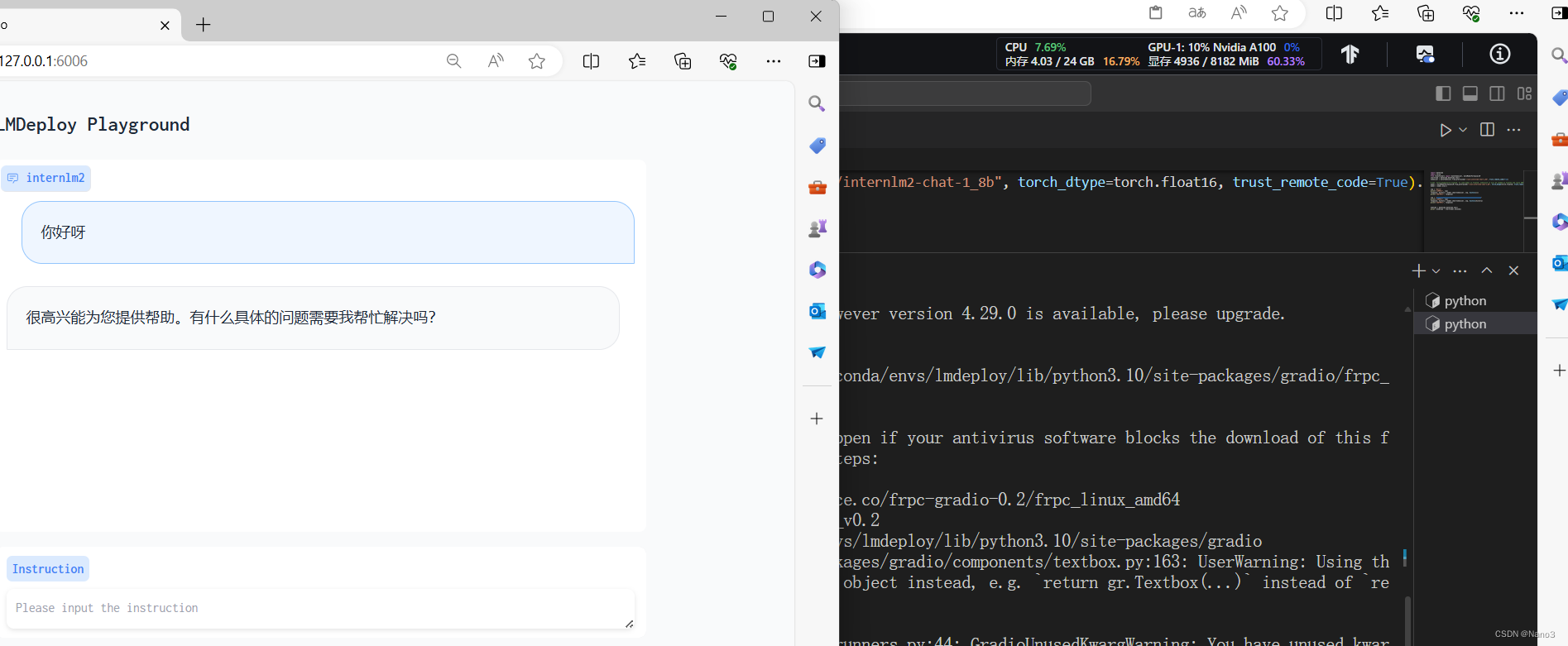
在Gradio网页客户端与模型对话
Python代码集成量化
1.python集成
在生成response的一瞬间显存大概是七千多。
2.设置kv cache 0.4
在生成response的一瞬间显存大概是四千多。
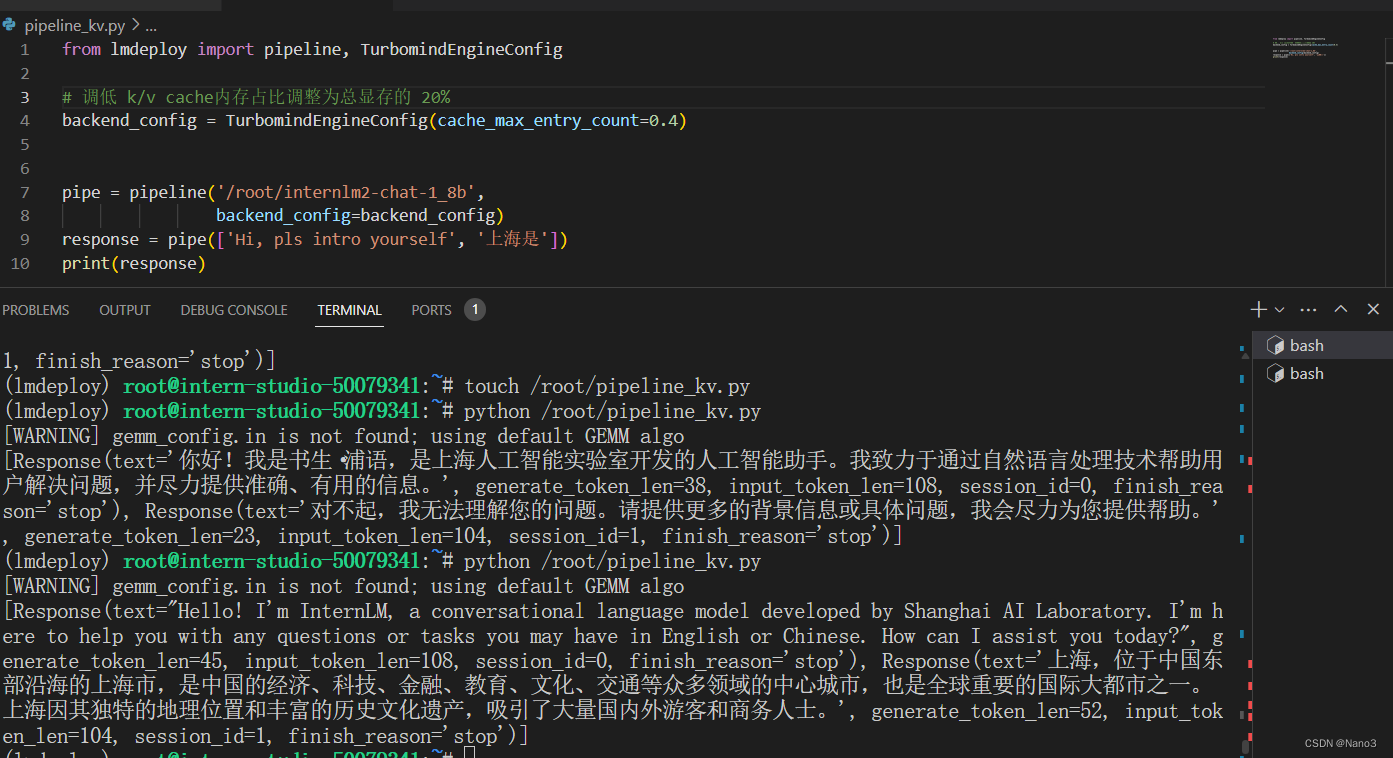
3.在以上加上W416A
把模型换成4bit的,然后查看LMDeploy官方文档的awq部分看看awq在python代码应用的格式,原来就还是model_format。
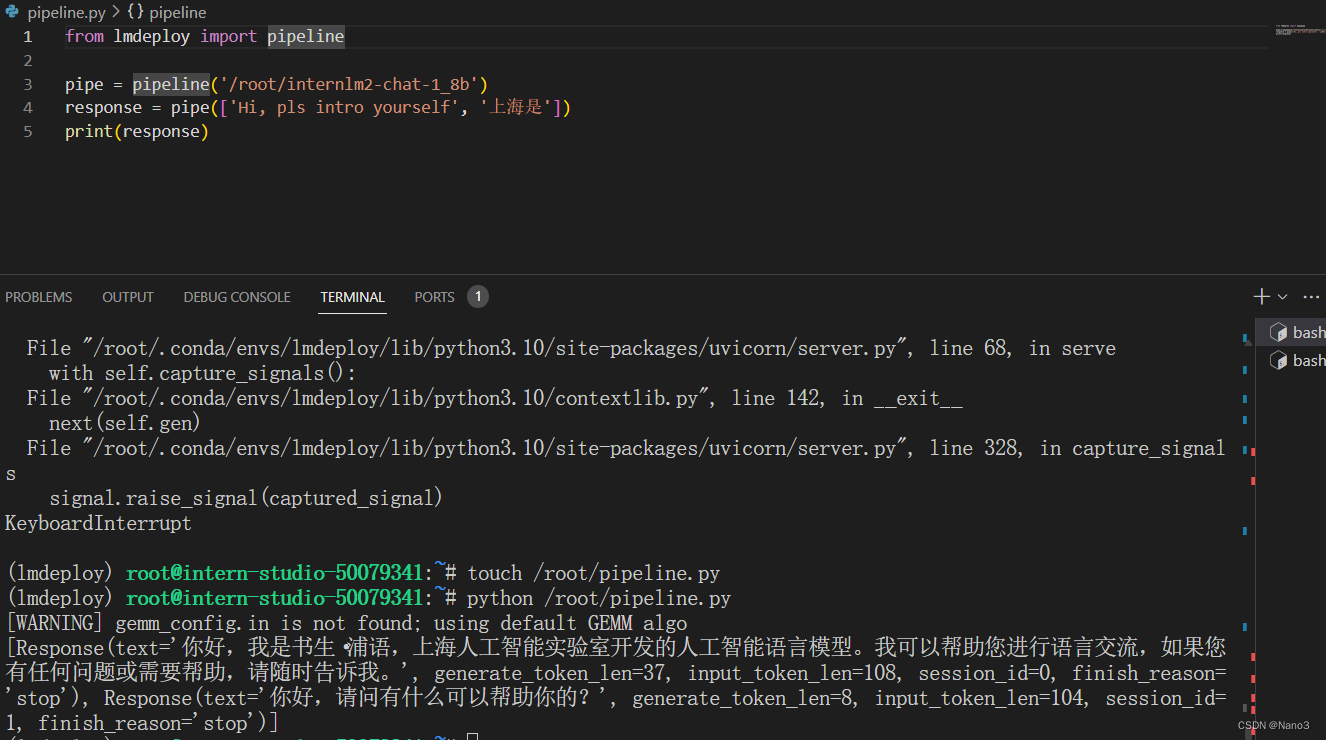
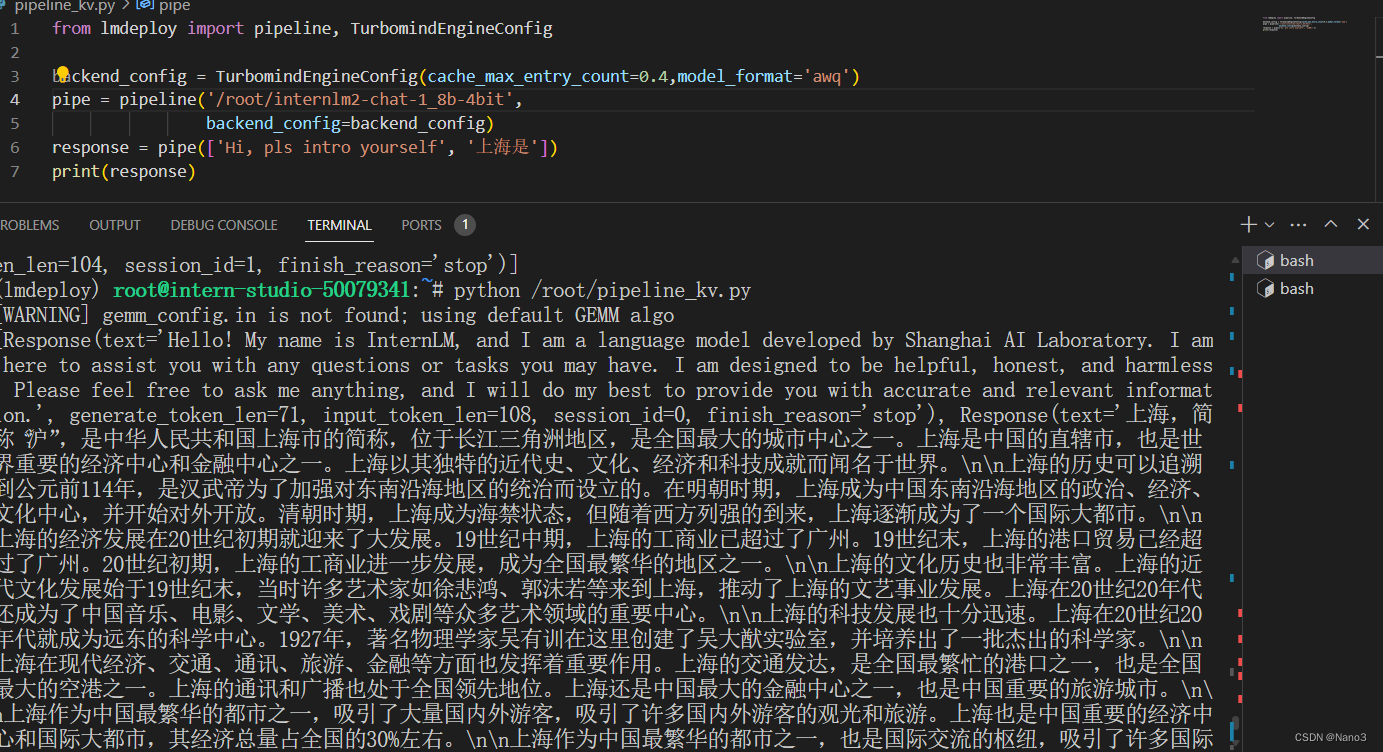
最后KV Cache 0.4+W4A16的代码就是以下:
from lmdeploy import pipeline, TurbomindEngineConfig
backend_config = TurbomindEngineConfig(cache_max_entry_count=0.4,model_format='awq')
pipe = pipeline('/root/internlm2-chat-1_8b-4bit',
backend_config=backend_config)
response = pipe(['Hi, pls intro yourself', '上海是'])
print(response)
按这样好像生成response一瞬间还是四千多。
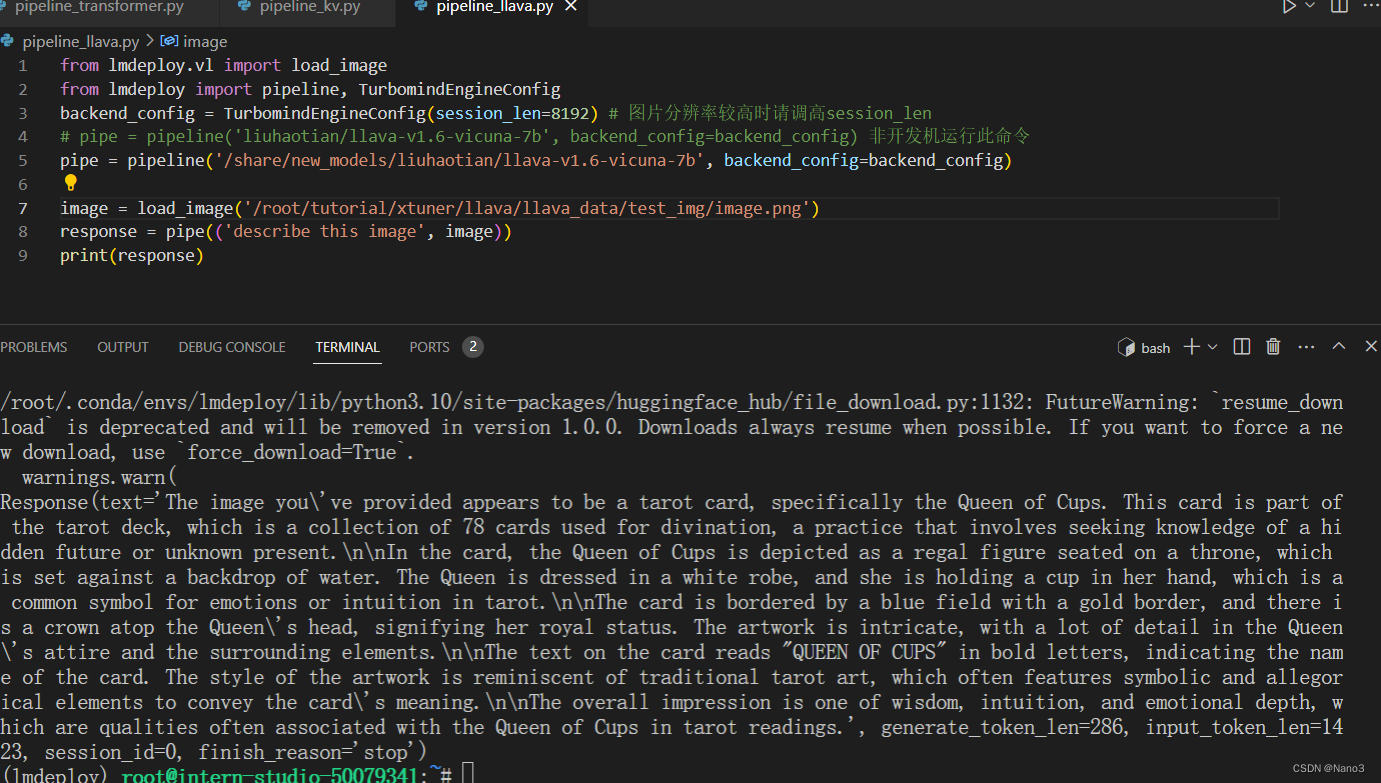
运行视觉多模态大模型 llava gradio demo
先把开发机配置升级下。
这个运行的时候显存确实大,我把image换成了做第4节课时上传的图片,一个抽象的塔罗牌。

说的挺准的。
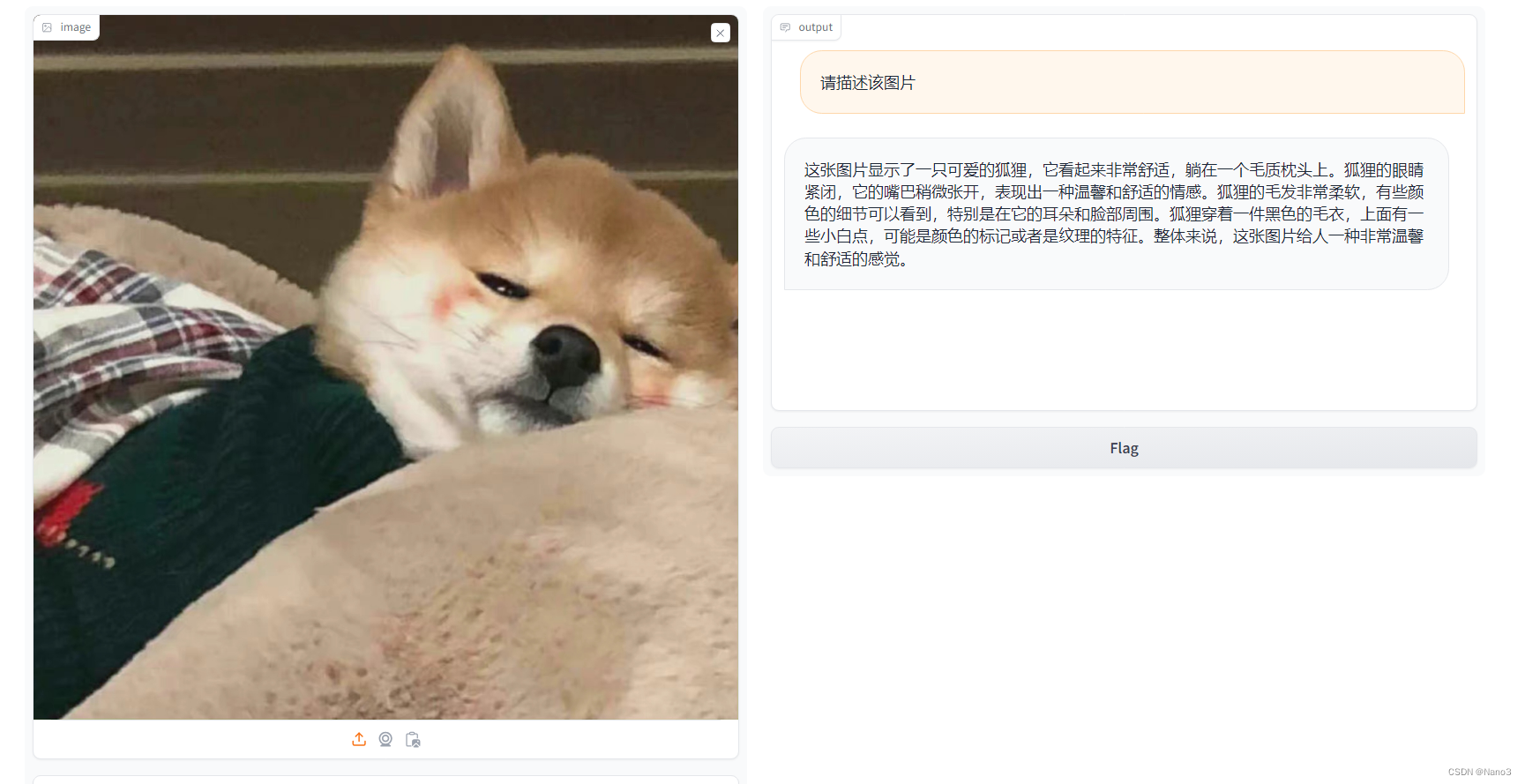
看来柴犬和狐狸不好分哈哈哈。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









