







最近在参加机器学习算法类的比赛,对一些知识点进行了查漏补缺和归纳总结,其实收获还挺多的,不得不说比赛是一个让人快速成长并且拓宽视野的过程,接下来就进入正题。
我们做机器学习任务的时候,通常情况下,拿到的数据都会存在缺失值,而数据预处理首先需要做的就是对存在的缺失值进行处理,这里我总结了处理缺失值的几种方法,并详细地解释了如何用代码实现,完全足够解决处理缺失值这一问题。
缺失值处理
1、观察数据是否存在缺失值
先简单讲下这篇文章用到的数据集,训练集原始数据共25497个样本,6个特征,一个标签。
train.shape结果:(25497, 7)
train.head()结果:
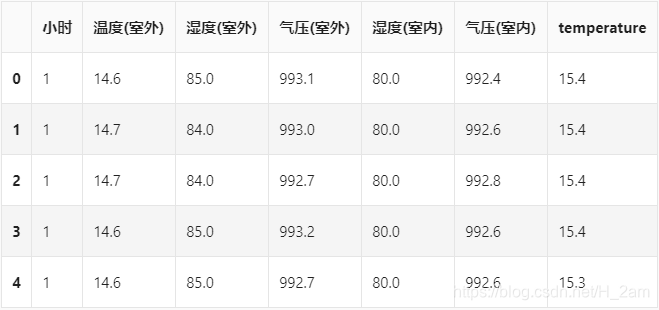
当我们用pandas.read_csv()读入一份数据后,通常用以下方法观察数据是否存在缺失值:
1)使用pandas.isnan()判断:
print(np.isnan(train).any())结果如下:

我们可以看到,在训练集中,除了 “小时” 这一列之外,其余特征都存在缺失值(isnan结果为True则为缺失值)。
2)使用DataFrame.info()函数判断:
train.info()结果如下:
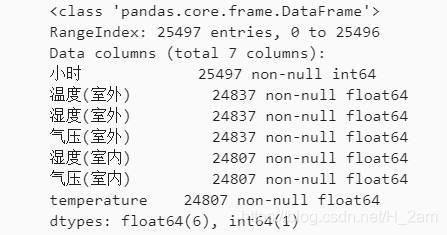
从结果可以看出,训练集共有25497个样本,所以除了“小时”这一列之外,其余特征均存在缺失值的情况。
2、处理缺失值的方法
对于缺失值的处理,通常有两种方法,一是直接丢掉含有缺失值的样本,二是用数据填充(比如用均值,中位数,众数等填充,也可以用指定的值填充),至于是直接丢掉效果好还是填充的效果好,这是没有具定论的,不同的数据效果是不一样的,所以实际操作过程中可以都进行尝试,找到最优的效果。
不过,需要强调的是,当训练集样本本身较少,而缺失值又相对较多的时候,不建议直接丢掉含有缺失值的样本,这样会使训练集样本更少,模型训练的时候学习到的东西也就更少。另外,测试集上的缺失值不能采用直接丢掉的方法,因为每一个样本都是你需要预测的样本,你不能把它丢掉。
对于具体的代码实现,这里总结了两种常用的方法,一种是用pandas实现,一种是用sklearn中的imput.SimpleImputer实现。
1)用pandas实现
①用 DataFrame.dropna() 来丢掉存在缺失值的样本:
train.dropna().reset_index(drop = True)运行之后即丢掉了含有空值的行,reset_index()使索引重置,参数drop = True表示丢掉原来的那列索引。
train.info()结果:
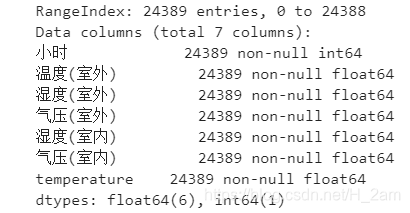
从结果可以看出,样本数量从原来的25497个变为了新的24389个,含空值的样本都被丢掉了。
下面讲下DataFrame.dropna()的参数:
| 参数 | 作用 |
|---|---|
| axis | 取 0 或 1 ,axis= 0;示删除某一行;axis= 1,表示删除某一列,默认为0 |
| how | 取 ‘any’ 或 ‘all ’ ;how = ’ any’, 表示某行(列)只要存在空值就删除;how = ‘all’, 表示某行(列)全为空值才删除;默认为’any’ |
| thresh | 取int值。如thresh= 2,表示某行(列)非空值至少为2个才会被保留。 |
| subset | 取array类型。指定某几列,如subset = [“小时”],表示丢弃小时这一列中的缺失值。默认不设置。 |
| inplace | inplace= True 表示操作之后的结果取代操作前的结果。用法:train.dropna(implace = True) 等价于 train=train.dropna() |
p.s. 对于不理解的函数,可以查官方帮助文档,如直接在代码框中运行help(pd.DataFrame.dropna)就可以查看dropna()的官方帮助文档,里面每个函数讲得很详细,还有例子帮助理解。
②用 DataFrame.fillna() 来填充缺失值:
train = train.fillna(method='bfill')参数method = ‘bfill’ 表示用缺失值后一个样本对应的值来填充该缺失值。
train.info()结果:
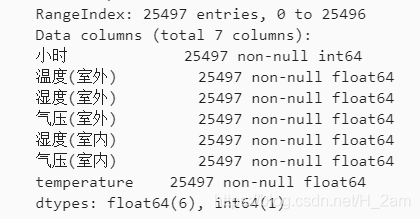
可以看到,处理后的样本数量与处理前相比没有变化,缺失值都被填充了。
下面讲下DataFrame.fillna()的参数:
| 参数 | 作用 |
|---|---|
| value | 用指定值来填充,如trian.fillna(value=0)表示用0来填充缺失值,默认为None |
| method | 取{‘backfill’, ‘bfill’, ‘pad’, ‘ffill’}中的一个,pad/ffill:用前一个非缺失值去填充该缺失值,backfill/bfill:用后一个非缺失值填充该缺失值。默认为None,需要指定一个值填充 |
| axis | 取 0 或 1 ; axis= 0,以行为操作;axis= 1,表示以列操作;默认为0 |
| inplace | inplace= True 表示操作之后的结果取代操作前的结果,默认为False |
| limit | 取int值,默认为None。设定method之后,设置limit限制填充的个数。 |
2)用sklearn实现
calss SimpleImputer (missing_values=nan, strategy=‘mean’,
fill_value=None, verbose=0, copy=True, add_indicator=False)
一般需要了解以下三个参数:
- missing_values 表示要被填充的值是什么,等于nan就是表示填充空值,也可以设为其他值,比如我想把为0的值填充为其他值,就设missing_values = 0。
- strategy 表示用什么值填充,可选’mean’均值、'median’中位数、'most_frequent’众数、‘constant’, 当为’constant’时,表示用fill_value的值来填充。
- fill_value, 当设strategy = ‘constant’,需要设置fill_value的值,如fill_value = 0,表示用0来填充
3、总结
总的来说,对于缺失值的处理无论是原理还是实现,都比较简单,但简单不意味着它不重要,如果不处理缺失值之后的很多操作都会报错,并且会影响到一些模型的学习效果,所以拿到数据的一开始就应该观察数据是否存在缺失值并对缺失值进行处理。
处理缺失值要注意以下细节:
①直接丢掉缺失值之后注意要重置索引,以为丢掉含缺失值的样本时那一行的索引也会被丢掉,索引不连续导致候选操作出问题,如写循环的时候。
②测试集中的缺失值不能直接丢掉,只能填充,因为你的任务是预测每一个样本,丢掉了那你就没完成规定的任务
处理完缺失值之后紧接着要做的就是对异常值进行处理,处理异常值往往对结果有不错的提升,所以非常重要。处理异常值比处理缺失值的过程要稍微复杂一些,因为涉及到数据的可视化分析,过两天再总结下对异常值的处理。希望这次的总结可以对大家有所帮助。

















 2181
2181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









