







 本文详细介绍了缺失值的识别与处理方法,包括使用isnull()、dropna()和fillna()等函数进行数据清洗,以及利用missingno库进行缺失值可视化。此外还探讨了通过插值法和预测法来填补缺失值的高级技巧。
本文详细介绍了缺失值的识别与处理方法,包括使用isnull()、dropna()和fillna()等函数进行数据清洗,以及利用missingno库进行缺失值可视化。此外还探讨了通过插值法和预测法来填补缺失值的高级技巧。
目录
1.2 每列/行是否包含缺失值-isnull.any()/isnull.all()
0、前言
缺失值指的是由于人为或机器等原因导致数据记录的丢失或隐瞒,缺失值的存在一定程度上会影响后续数据分析和挖掘的结果,所以对他的处理将显得尤为重要。
1、缺失值的识别
1.1 每个数据的识别-isnull()
data.isnull()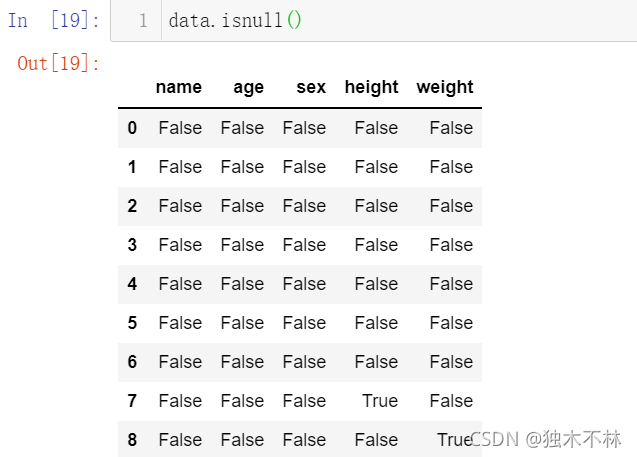
1.2 每列/行是否包含缺失值-isnull.any()/isnull.all()
data.isnull().any(axis=0)
data.isnull().all()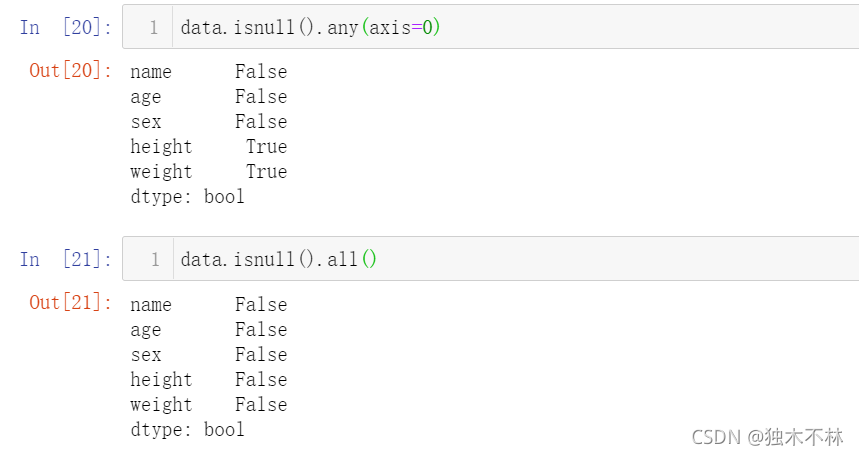
1.3 缺失值的个数-isnull().sum()
data.isnull().sum(axis=0)
1.4 检查所有的数据-data.info()
data.info()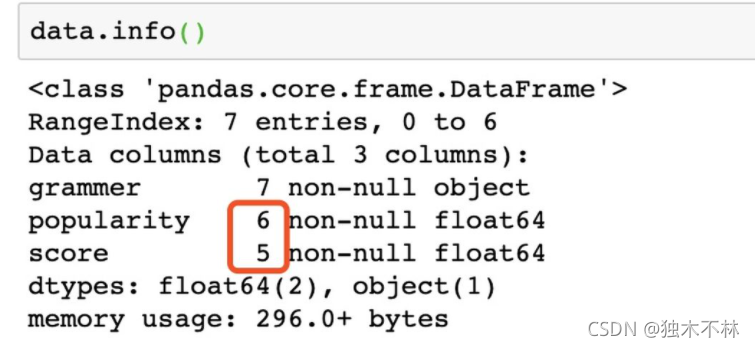
可以看到一共有7行,但是有两列的非空值都不到7行
1.5 缺失值可视化-missingno库
missingno提供了一个灵活且易于使用的缺少数据可视化工具和实用程序的小型工具集,使你可以快速直观地概述数据集的完整性。
pip install missingno1.5.1 缺失值的矩阵图
msno.matrix(data, figsize=(16, 9), width_ratios=(15, 5))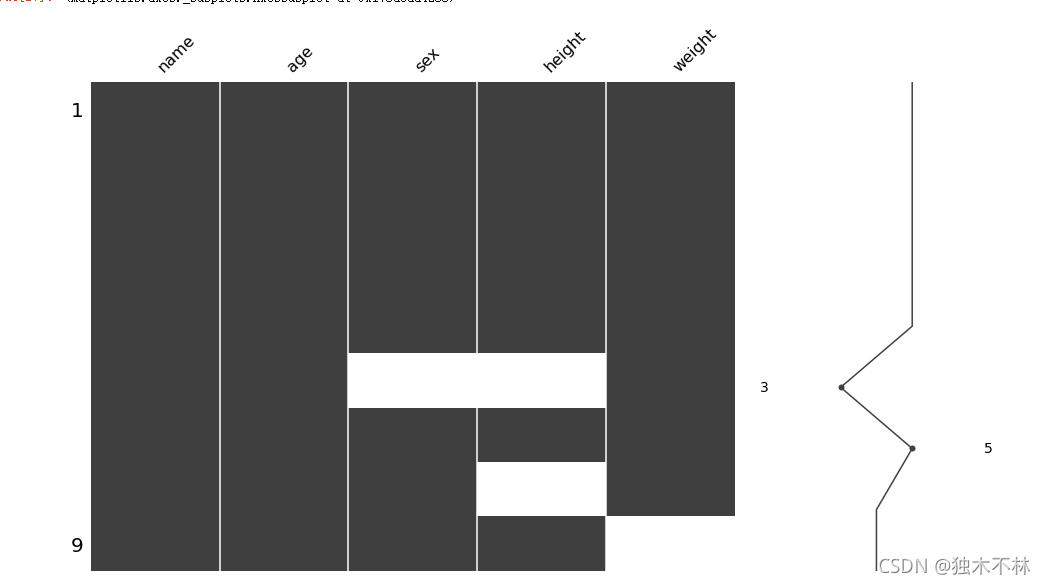
msno.matrix无效矩阵是一个数据密集的显示,它可以快速直观地看出数据完整度。
空白越多说明缺失越严重
右侧的迷你图概述了数据完整性的一般形状,并指出了数据集中具有最大和最小无效值的列数。需要说明的是,这个矩阵图最多容纳50个变量,超过此范围的标签开始重叠或变得不可读,默认情况下,大尺寸显示器会忽略它们。
1.5.2 缺失值的条形图
条形图提供与矩阵图相同的信息,但格式更简单。
msno.bar(data)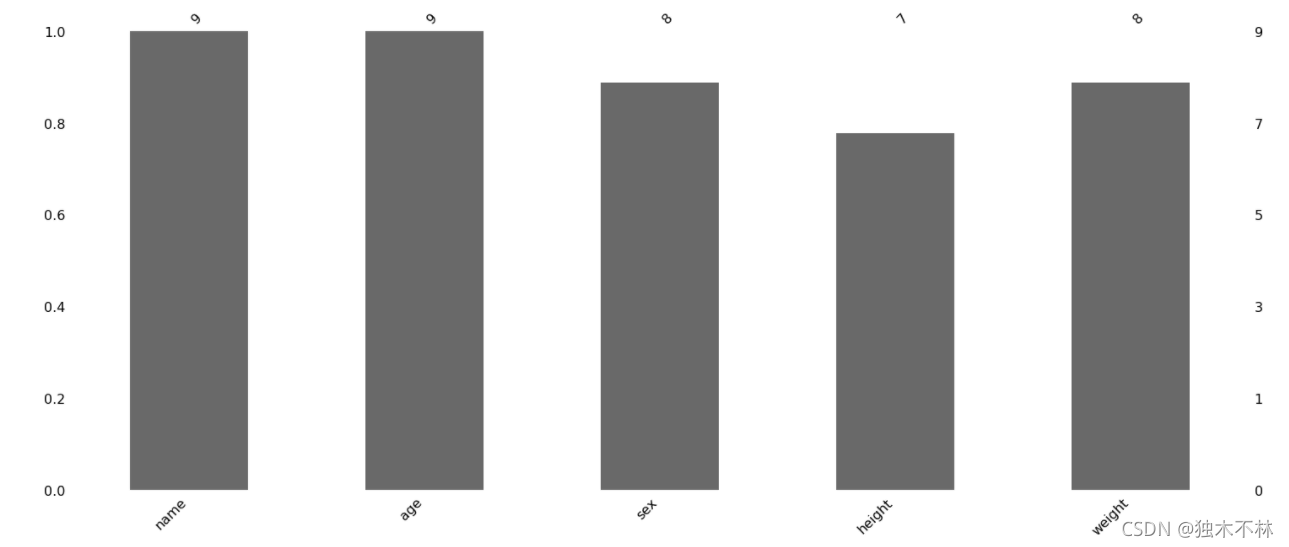 1.5.3 缺失值的热力图
1.5.3 缺失值的热力图
missingno相关性热力图可以显示无效的相关性:一个变量的存在或不存在如何强烈影响的另一个的存在。
数值为1:两个变量一个缺失另一个必缺失;
数值为-1:一个变量缺失另一个变量必然不缺失。
数值为0:变量缺失值出现或不出现彼此没有影响。
热力图非常适合于选择变量对之间的数据完整性关系,但是当涉及到较大的关系时,其解释力有限,并且它不特别支持超大型数据集。
注:始终为满或始终为空的变量没有任何有意义的关联,因此会从可视化中删除。
msno.heatmap(data) 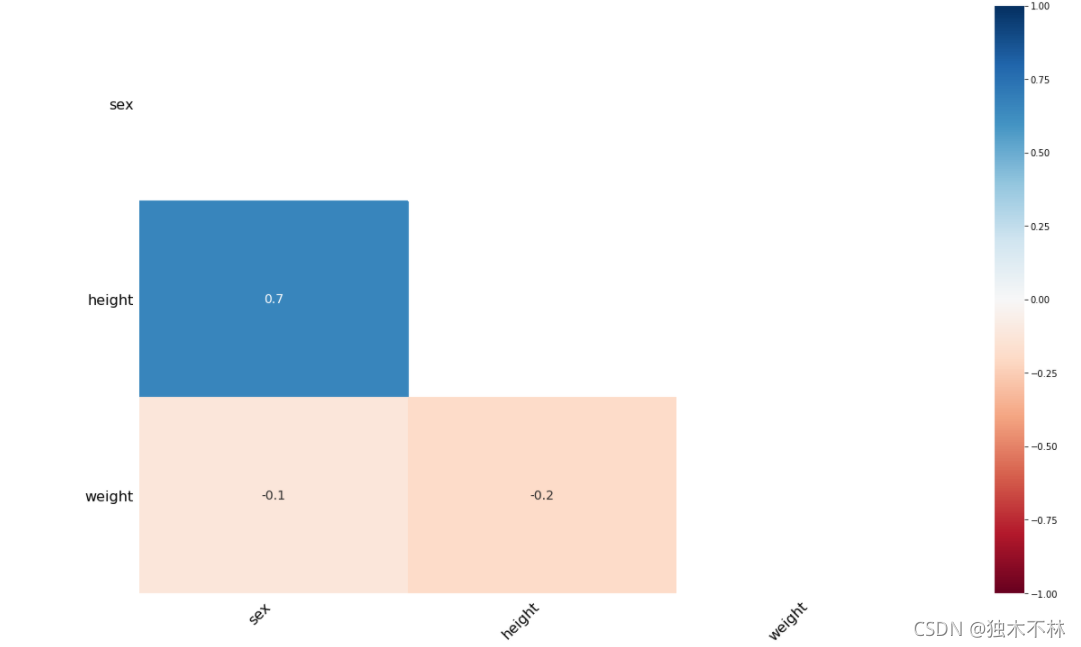
2、缺失值的处理
2.1 删除法-df.dropna()
删除法是指将缺失值所在的观测行删除(前提是缺失行的比例非常低,如5%以内),或者删除缺失值所对应的变量(前提是该变量中包含的缺失值比例非常高,如70%左右)
data.dropna() #直接删除含有缺失值的行
data.dropna(axis=1) #直接删除含有缺失值的列
data.dropna(how="all") #直接删除全是缺失值的行
data.dropna(thresh=4) #删除缺失值后剩余数值的数量至少有4个的行
data.dropna(subset=['C']) #删除含有缺失值的特定的列2.2 填补法
2.2.1 替换法
替换法是指直接利用缺失变量均值,中位数,众数等。或者可以用空值、自定义数值、向前向后填补,其好处是缺失值的处理速度快,弊端是易产生有偏估计,导致缺失值替换的准确性下降。
注:由于众数可能存在多个,要考虑到这点
注:向前后填补要考虑到第/最后一行为空值情况
方法一:fillna()
df.fillna(0) #用0填充
df.fillna(method="pad") #用前一个数值填充,ffill,
df.fillna(value={"age":df["age"].mode()[0]}) #用该列第一个众数填充
df["age"].fillna(df["age"].mean())
df["age"].fillna(df["age"].interpolate())方法二:Imputer
from sklearn.preprocessing import Imputer
imr = Imputer(missing_values='NaN', strategy='mean', axis=0)#均值填充缺失值
imr = imr.fit(df)
imputed_data = imr.transform(df.values)2.2.2 插值法
在X个范围内求出一个值填至缺失值中,如拉格朗日插值法
def f(s,n,k=5):#s=df,n缺失值位置,k范围=5
y = s[list(range(n-k,n+1+k))]#y求出缺失值前5后5的df数值
y = y[y.notnull()]#确保里面没有nan
return(lagrange(y.index,list(y))(n))#lagrange计算出第n个值
for i in range(len(df)):
if df.isnull()[i]:
data[i] = f(df,i)
print(f(df,i)) 2.2.3 预测法
插补法则是利用有监督的机器学习方法(如回归模型、树模型、网络模型等)对缺失值作预测,其优势在于预测的准确性高,缺点是需要大量的计算,导致缺失值的处理速度大打折扣。
a.把需要填充的某列作为新特征列Label_A
b.选出与Label_A相关性强的组成模型
c.非缺失值作为训练集,缺失值作为测试集
d.连续性数据用回归预测,离散型进行分类学习
dataset['Label_A']=dataset['A'] #a
dataset.corr() #b
x_trian,y_train,x_test,y_test = train_test_split(x,y) #c,x是b中相关性较强的特征列,y是结果列
lr = LinearRegression()
lr.fit(x_train, y_train)
y_train_pred = lr.predict(x_train)
print('>>>在训练集中的表现:', r2_score(y_train_pred, y_train))
y_valid_pred = lr.predict(x_valid)
print('>>>在验证集中的表现:', r2_score(y_valid_pred, y_valid))
y_test_pred = lr.predict(test.iloc[:, :2])
test.loc[:, 'Label_petal_length'] = y_test_pred
df_no_nan = pd.concat([train, test], axis=0)
















 548
548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









