







文章目录
前言
最近准备入门图像识别领域,在了解图像识别的基本原理之后但是苦于一直不知道该如何开始自己的第一个项目, 在看了几种不同的网课之后,终于发现了《深度学习应用开发-TensorFlow实践》。这是大学mooc的一门课,讲解浅显易懂,并且很容易上手。
程序源码:https://github.com/hu669293657/Tensorflow/tree/main
环境
Win10
Python3.9
Tensorflow2.6.0
PyCharm Community Edition 2021.2
一、基本原理和概念
1.线性回归
线性回归是来自于统计学的一个方法。函数的定义说的是 独立参数 x 和 非独立参数 y之间的对应关系。例如本文使用的例子:y=2x+1。
2.回归分析
在统计学中,回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。
3.机器学习系统
通过学习如何组合输入信息来对未见过的数据做出有用的预测。
4.监督式机器学习
是一个机器学习中的方法,可以由训练资料中学到或建立一个模式(函数 / learning model),并依此模式推测新的实例。本文就是利用监督式机器学习来解决线性回归预测的问题。
5.标签和特征
标签是我们要预测的真实事物:y线性回归中的y变量。
特征是指用于描述数据的输入变量:xi,线性回归中的{x1,x2,…,xn)变量
6.超参数
在机器学习中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。
7.梯度下降法
这个方法在网上有很多专业的解释,但是对于初学者可能要花比较长的时间理解,在这里我说一下我的理解,可能不是很准确但是应该会好理解一点。对于本题中的线性方程y=2x+1,其中x和y已经给定,当我们让机器来预测这个方程时,即预测y=wx+b中的w和b。如图:

y轴是损失,即我们预测的w与真实的w的误差;x轴为权重,即我们现在的w。我们令w为一个初始值,即起点,通过不断得调整那个小圆珠在黑线上的位置,直到那个小圆珠到达了最底下的位置,即那一点导数非常接近于0。我们就认为我们预测的w和真实的w差距最小。所以我们就要一点点来调整小圆珠,在这过程中速度既不能太快也不能太慢,太快的话小圆珠就会像个摆钟一样在最低点反复横跳,太慢的话时间也就太长了也不太好。
二、进入实战
1.准备数据
第一步就是准备数据,正所谓巧妇难为无米之炊。通过设置w=2.0,b=1.0,并加入一个噪声,噪声最大振幅为0.4,否则就是y=2x+1的那条直线了,代码如下(示例):
导入相关库
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
生成数据集,*x_data.shape为100
x_data = np.linspace(-1,1,100)
np.random.seed(5) #设置随机数种子,来保证我们的随机数都是一样的
y_data = 2*x_data+1.0+np.random.randn(*x_data.shape)*0.4 #用*把x.shape设置为实参
利用matplotlib画出生成结果
plt.scatter(x_data,y_data) #画出随机生成数据的散点图
plt.plot(x_data, 2*x_data+1.0,color='red',linewidth=3) #画出我们想要学习到的线性函数 y=2x+1

2.构建模型
通过模型执行,将实现前向计算(预测计算),返回y,y=wx+b。
def model(x,w,b):
return tf.multiply(x, w)+b
创建待优化变量w,b。设置初值,正是上文的小圆珠起点的位置。
#构建线性函数的斜率,变量w
w = tf.Variable(1.0)
#构建线性函数的截距,变量b
b = tf.Variable(0.0)
定义损失函数。
def loss(x,y,w,b):
err = model(x, w, b) - y #计算模型预测值和标签值的差异
squared_err = tf.square(err) #求平方,得出方差
return tf.reduce_mean(squared_err) #求均值,得出均方差
'''
采用均方差作为损失函数(第二种表达方式)
pred = model(x,w,b) pred是预测值,前向计算
loss = tf.reduce_mean(tf.square(y-pred))
以上就是y=1/n(y-y*)^2,当y越小时,即损失越小
'''
3.训练模型
设置训练超参数,其中学习率不能过大也不能过小。
train_epochs = 10 #迭代次数(训练轮数)
learning_rate = 0.01 #学习率
定义计算梯度函数。
#计算样本数据[x,y]在参数[w,b]点上的梯度
def grad(x,y,w,b):
with tf.GradientTape() as tape: #上下文管理器封装需要求导的计算步骤,
loss_ = loss(x, y, w, b)
return tape.gradient(loss_, [w, b]) #使用gradient()求导
执行训练。
step = 0 #记录训练步数
loss_list = [] #用于保存loss值的列表
display_step = 10 #控制训练过程中数据显示的频率,不是超参数
for epoch in range(train_epochs):
for xs, ys in zip(x_data, y_data):
loss_ = loss(xs, ys, w, b) #计算损失
loss_list.append(loss_) #保存本次损失计算结果
delta_w, delta_b = grad(xs, ys, w, b) #计算当前[w,b]的梯度
change_w = delta_w * learning_rate #计算变量w需要调整的量
change_b = delta_b * learning_rate #计算变量b需要调整的量
w.assign_sub(change_w) #变量w更新后的量
b.assign_sub(change_b) #变量b更新后的量
step = step + 1
if step % display_step == 0:
print("Trainging Epoch:{},Step:{},loss={}".format(epoch+1, step, loss_))
plt.plot(x_data, w.numpy() * x_data + b.numpy())
迭代训练结果:

从上图可以看出,本案例所拟合的模型较简单,训练5轮之后已经接近收敛对于复杂模型,需要更多次训练才能收敛。

4.进行预测
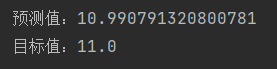
利用这个模型,进行一下预测,看看效果怎么样:
def pre_number(x_test):
predict = model(x_test, w.numpy(), b.numpy())
print("预测值:{}".format(predict))
target = 2 * x_test + 1.0
print("目标值:{}".format(target))
pre_number(5.0)
通过上面我们训练的模型,发现预测还是比较准确的。
总结
通过一个简单的例子介绍了利用Tensorflow实现机器学习的思路,重点讲解了下述步骤:
(1)生成人工数据集及其可视化
(2)构建线性模型
(3)定义损失函数
(4)(梯度下降)优化过程
(5)训练结果的可视化
(6)利用学习到的模型进行预测
第一次学习机器学习,可能有些地方做得还不好,欢迎各位大佬指正!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









