







话不多说,先放代码
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torch.nn.functional as F
import torch.optim as optimizer
import numpy as np
import torchvision
import torch.utils.data
from torchvision import datasets,transforms
input_size = 28
batch_size = 64
num_classes = 10
num_epochs = 3
learning_rate = 0.001
train_dataset = datasets.MNIST(root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='.data', train=False, transform=transforms.ToTensor(), download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential\
(
nn.Conv2d\
(
in_channels=1,
out_channels=16,
kernel_size=5,
stride=1,
padding=2,
),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
)
self.conv2 = nn.Sequential\
(
nn.Conv2d(16,32,5,1,2),
nn.ReLU(),
nn.MaxPool2d(2),
)
self.out = nn.Linear(7 * 7 * 32, 10, bias=True)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
out = self.out(x)
return out
# 实例化开始训练
net = CNN()
print(torch.cuda.is_available())
# print(net)
loss_func = nn.CrossEntropyLoss()
my_optimizer = optimizer.Adam(net.parameters(), lr=learning_rate)
def cal_rights(predictions, targets):
pred = torch.max(predictions.data, dim=1)[1]
rights = sum(pred == targets.data) / float(len(pred))
return rights
for epoch in range(num_epochs):
train_rights = []
for batch_idx, (data, target) in enumerate(train_loader):
net.train()
data.to(device)
output = net(data)
my_optimizer.zero_grad()
loss = loss_func(output, target)
loss.backward()
my_optimizer.step()
rights = cal_rights(output,target)
train_rights.append(rights)
# 测试
if batch_idx % 100 == 0:
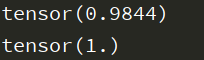
print(train_rights[-1])
# net.eval()
val_rights = []
for i, (eval_data, eval_target) in enumerate(test_loader):
eval_output = net(eval_data)
rights = cal_rights(eval_output, eval_target)
val_rights.append(rights)
print(val_rights[-1])
模型分类成功率在98%以上
仍然存在的问题
1、转移到GPU上面始终无法实现。
2、对于数据集处理如DataLoader的掌握仍然不到位。
接下来任务:
尝试pytorch实现yolo算法
















 1406
1406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









