









转载地址:手把手教你用Keras进行多标签分类(附代码)(程思衍、付宇帅)
英文原文:Multilabel Classification with Keras(Adrian Rosebrock)
源代码:百度云链接 | 提取码:tuby
本文将通过拆解SmallVGGNet的架构及代码实例来讲解如何运用Keras进行多标签分类。
本文的灵感来源于我收到的一封来自PyImageSearch的读者Switaj的邮件。他写到:
你好,Adrian,感谢PyImageSearch,感谢你每周都分享你的知识。我正在构建一个时尚图像的搜索引擎,我需要你的帮助。使用我的app,用户可以上传一张他们喜欢的服饰的图片(如衬衫、裙子、裤子、鞋类),我的系统将会返回相似的物品并附上购买链接。
问题是我需要训练一个分类器来将物品分到不同的类别中:
服饰类别:衬衫、裙子、裤子、鞋类等
颜色:红、蓝、黑等
质地:棉、羊毛、丝、麻等
我已经为这三个不同的类别训练了三个不同的卷积神经网络(下文将称为CNN),效果非常好。
是否有办法让这三个CNN合并为一个CNN呢?或者至少训练一个神经网络来完成三项分类任务?
我不想在if / else代码的级联中单独应用它们,这些代码使用不同的网络,具体取决于先前分类的输出。
谢谢你的帮助
Switaj提出了一个美妙的问题:
Keras深度神经网络是否有可能返回多个预测?
如果可以,它是如何完成的?
基于Keras的多标签分类问题
本文将分为4个部分。
- 在第一部分,我将讨论我们的多标签分类数据集(以及如何快速构建属于你自己的数据集)。
- 之后我们将简要讨论SmallerVGGNet,它是我们将要实现的一个用于多标签分类的Keras神经网络结构。
- 紧接着我们将构建SmallerVGGNet并应用我们的多标签分类数据集来训练他。
- 最后,我们将基于样例图片测试我们的神经网络,并讨论何时使用多标签分类问题最为合适,包括您需要注意的一些注意事项。
我们的多标签分类数据集

本教程旨在模仿本文先前提到的Switaj’s的问题(尽管我们基于本文对它进行了简化)。上图为我们将用于今天的Keras多标签分类教程的数据集,即我们将使用Keras来训练一个多标签分类器来预测衣服的颜色以及类别。
我们的数据集由2167张图片组成,它们来自6个不同的种类,包括:
- 黑色牛仔裤(344张图片)
- 蓝色裙子(386张图片)
- 蓝色牛仔裤(356张图片)
- 蓝色衬衫(369张图片)
- 红色裙子(380张图片)
- 红色衬衫(332张图片)
我们的卷积神经网络的目标是同时预测颜色和服饰类别。
构建该数据集通过遵循我之前发布过的博文:How to (quickly) build a deep learning image dataset。下载图片以及手动为该6个类别剔除不相关图片的整个过程将耗费大概30分钟。当你在尝试构建你自己的深度学习数据集时,请确保你遵循了上述教程链接——它将帮助你快速启动构建你自己的数据集。
多标签分类项目结构
请直接访问本文的“下载”处以获得源代码及文件。一旦你解压缩了zip文件,你将会看到如下的目录结构:

在该zip文件的根目录下,你会看到6个文件及3个文件夹。我们将用到的重要文件(基于它们本文出现的大致顺序)包括:
- search_bing_api.py:此脚本使我们能够快速构建深度学习图像数据集。你不需要运行这段脚本因为图片数据集已经囊括在zip文件中。我附上这段脚本仅为保证(代码的)完整性。
- train.py:一旦我们拥有了数据,我们将应用train.py训练我们的分类器。
- fashion.model:我们的train.py脚本将会将我们的Keras模型保存到磁盘中。我们将在之后的classify.py脚本中用到它。
- mlb.pickle:一个由train.py创建的scikit-learn MultiLabelBinarizer pickle文件——该文件以顺序数据结构存储了各类别名称。
- plot.png:训练脚本会生成一个名为plot.png的图片文件。如果你在你自己的数据集上训练,你便需要查看这张图片以获得正确率/风险函数损失及过拟合情况。
- classify.py:为了测试我们的分类器,我写了classify.py。在你将模型部署于其他地方(如一个iphone的深度学习app或是树莓派深度学习项目)之前,你应该始终在本地测试你的分类器。
本项目中的三个文件夹为:
- dataset:该文件夹包含了我们的图片数据集。每个类别拥有它自己的子文件夹。我们这样做以保证(1)我们的数据在结构上工整有序(2)在给定图片路径后能更容易地提取类别标签名称。
- pyimagesearch:这是装有我们的Keras神经网络的模块。由于这是一个模块,它包含了固定格式的
__init__.py。另外一个文件smallervggnet.py,它包含组装神经网络本身的代码。 - examples:该文件夹包含了7个样例图片。我们将基于keras,应用classify.py对每一个样例图片执行多标签分类。
如果这些(文件)看起来太多了,别担心!我们将会按照我所提出的顺序逐个回顾。
我们用于多标签分类的Keras神经网络架构

上图被我称为“SmallerVGGNet”的类VGGNet神经网络,我们将用它基于Keras训练一个多标签深度学习分类器。
本教程中我所用到的CNN架构是SmallerVGGNet,一个简化版本的VGGNet。VGGNet最先由Simonyan和Zisserman在他们2014年的论文:Very Deep Convolutional Networks for Large Scale Image Recognition中提出。
为了完整性,我们将在本教程中实现SmallerVGGNet;然而,我将有关架构/代码的长篇大论转移至我之前的一篇文章——如果你有任何关于架构的问题或是想要了解更多细节,请参阅参阅该文章。如果你希望设计你自己的模型,你会希望有一本我的书:Deep Learning for Computer Vision with Python。
请确保你通过文末的“下载”处获得了源代码和样例图片。获得之后,打开在pyimagesearch模块下的smallervggnet.py文件, 继续:
从第二至第十行代码,我们引入了Keras模块并于此开始建立我们的SmallerVGGNet类:
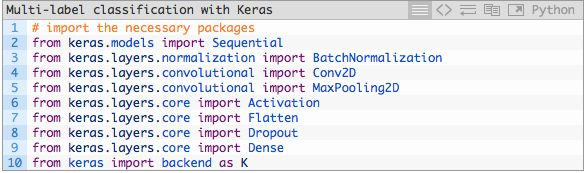
我们的SmallerVGGNet类从第12行开始被定义,随后我们在第14行定义构建函数,用于组装卷积神经网络。

- 该构建方法规定需要4个参数——width,height,depth以及classes;width指定一张输入图片的通道(channels)数量,classes是种类(并不是他们所属的标签)数量(整数)。我们将在我们的训练脚本中应用这些参数来举例说明输入规格为96×96×3的模型。
- 可选参数finalAct(默认值为“softmax”)将会在神经网络底部被应用。将这个值由softmax改为sigmoid将允许我们基于Keras执行多标签分类。请记住这个行为与我们在之前文章中实现的SmallerVGGNet不同——我们在这里加入是为了控制执行简单二分类或者是多类分类。
- 之后,我们输入build的程序主体,初始化模型(第17行)并在第18行至第19行将架构默认值设置为
channels_last(方便切换为支持channels_first,实现于第23-25行)。
让我们构建第一个CONV ==> RELU ==> POOL模块:
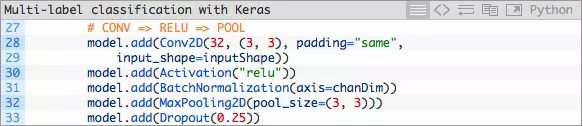
- 我们的CONV层拥有32个卷积核大小为3×3的滤波器以及RELU(Rectified Linear Unit)激活函数。我们在这之后使用批标准化,最大池化,以及25%的遗忘率(Dropout)。
- Dropout是一个随机切断当前神经网络层节点与下一神经网络层节点间链接的过程。这个随机断开的过程自然地帮助神经网络降低了过拟合的可能性,得益于没有任何一个节点会被分配以预测某个特定的类别、对象、边缘或是角落。
紧接着我们有两组(CONV ==> RELU)*2 ==> POOL模块:

- 请注意本模块中过滤器、卷积核以及池化大小的变化,这些变化将会共同运作从而逐渐减少空间大小但提升深度(depth)。
这些模块之后是我们唯一的FC ==> RELU层:

- 全连接层被放置在神经网络的最末端(在第57-64行由Dense声明)。
- 第65行对于我们的多标签分类非常重要——finalAct指明我们使用的是针对于单标签分类的“softmax”激活函数,还是针对于今天我们提出的多标签分类的sigmoid激活函数。请参考本脚本smallervggnet.py的第14行以及train.py的第95行。
实现我们的多标签分类Keras模型
既然我们已经实现了SmallerVGGNet,接下来让我们创建train.py,我们用于训练多标签Keras神经网络的脚本。
我强烈建议你重温一下先前的博文,今天的train.py脚本便是基于该文章。实际上你可能会想要在屏幕上并行查看它们以观测它们之间区别并阅读关于代码的详细解释。今天回顾将简洁明了。
打开train.py并插入下述代码:

在第2至第19行,我们导入了该脚本所需要的包和模块。第三行指定了一个matplotlib后端,基于此我们可以在后台保存我们所绘制的图片。
我将假定你已经安装了Keras,scikit-learn,matplotlib,imutils以及OpenCV。如果这是你的深度学习首秀,你有两个选择来确保你拥有正确的库和包:
- 已配置好的环境(你将在5分钟内准备就绪并执行代码,训练今天的这个神经网络的花费将少于一杯星巴克咖啡的价格)。
- 建立你自己的环境(需要时间,耐性以及持久性)。
我更喜欢在云端预先配置好的环境,你能够在云上启动、上传文件、训练+获取数据以及在几分钟之内终止程序。我推荐的两个预先配置好的环境:
- 使用Python预配置的Amazon AWS深度学习AMI
- 用于深度学习的Microsoft数据科学虚拟机(DSVM)
如果你坚持要建立你自己的环境(而且你有时间来调试及问题修复),我建议你遵循下列博文中的一个:
- 使用Python配置Ubuntu进行深度学习(仅限CPU)
- 使用Python(GPU和CPU)设置Ubuntu 16.04 + CUDA + GPU进行深度学习
- 使用Python,TensorFlow和Keras进行深度学习的macOS
既然你的环境已经准备就绪,而且你已经导入了相关包,那么让我们解析命令行参数:
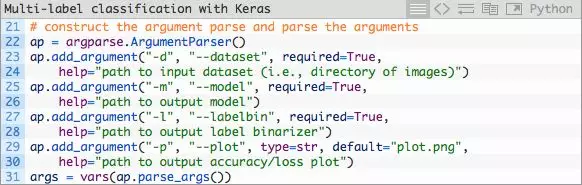
命令行参数之于脚本犹如参数之于函数——如果你不理解这个类比,你需要参阅命令行参数。
我们今天将会处理4个命令行参数:
- –dataset:输入的数据集路径。
- –model:输出的Keras序列模型路径。
- –labelbin:输出的多标签二值化对象路径。
- –plot:输出的训练损失及正确率图像路径。
如果你需要关于这些参数的结束,请务必参阅之前的博文。
让我们进一步讨论一些在我们训练过程中起到至关重要的作用的参数:

在第35-38行的这些参数定义了:
- 我们的神经网络将会训练75轮(epoch),通过反向传播不断提升模型表现从而学习数据背后的模式。
- 我们设置初始学习率为1e-3(Adam优化器的默认值)。
- Batch size是32。如果你拥有GPU,你应该根据你的GPU能力调整这个值,但我发现设置batch size为32能使这个项目执行的非常好。
- 如之前所言,我们的图片大小是96×96并包含3个通道。
之前的博文提供了更多细节。
紧接着,接下来的两个代码模块用于加载及预处理我们的训练数据:
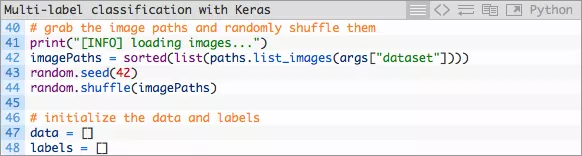
- 在这里我们获取imagePaths并将它们的顺序随机打乱,随后初始化data和labels数组。
然后我们将循环遍历imagePaths,预处理图像数据并解析多类标签。

- 首先我们将每张图片加载至内存。其次,我们在第54和第55行代码执行预处理(深度学习流水线中的重要一环)。我们将image添加在data的末尾。
- 第60和第61行针对我们的多标签分类问题将图片路径切分为多个标签。在第60的代码执行之后,一个拥有2个元素的数组被创建,随后在第61行中被添加至labels数据中。如下是一个在终端中经过分解的例子,你能从中了解多标签分词的过程:

如你所见,labels数组是一个“包含数组的数组”——labels中的每个元素都是一个包含两个元素的数组。每个数组对应两个标签这种架构是基于输入图片的文件路径构建的。
我们仍未完成预处理:

- 我们的data数据由利用Numpy数组存储的图片组成。在每一行代码中,我们将Python数组转换为Numpy数组并将像素值缩放于范围 [0,1] 之中。
- 我们也将标签转换为Numpy数组。
随后,然我们将标签二值化——下述模块对于本周的多类分类概念十分重要:
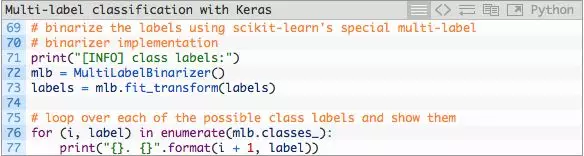
- 为了能够针对多类分类将标签二值化,我们需要运用scikit-learn库中的MultiLabelBinarizer类。你不能在多类分类问题上用标准的LabelBinarizer类。
- 第72和第73行代码将人可读的标签转换为包含各类对应编码的向量,该向量根据某类是否在图片中出现来决-定对应类的具体值。
这里是一个展现MultiLabelBinarizer如何将(“red”,“dress”)元组转换为一个有6个类别的向量的例子:

- One-hot编码将分类标签由一个整数转换为一个向量。同样的概念可以应用在第16和第17行代码上,除非这是一个two-hot编码。
- 请注意在Python命令行(为了不与train.py中的代码块混淆)中的第17行,有两个分类标签是“hot”(在数组中 用一个“1”表示),表明这各个标签的出现。在本例中,“dress”和“red”在数组中是“hot”(第14至第17行)。其他所有标签的值为“0”。
我们将数据分为训练集和测试集并初始化数据增强器。
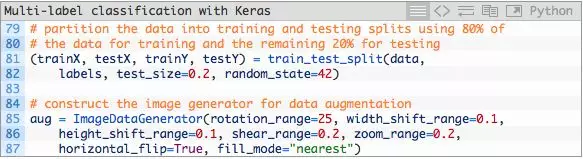
- 在机器学习实战中,将数据分为训练和测试集是一种很常见的做法——我把80%的图片分配为训练数据,20%为测试数据。这一过程在第81和82行中由scikit-learn进行处理。
- 我们的数据增强器对象在第85至第87中被初始化。当你的没类数据少于1000张图像时,数据增强是一个最好的实践也或许是一个“必须”的实践。
接下来,让我们建立模型并初始化Adam优化器:
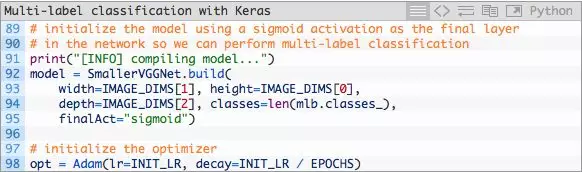
- 在第92至第95行中,我们构建SmallerVGGNet模型,finalAct=”sigmoid”这个参数指明我们将执行多标签分类。
随后,我们将编译模型并开始训练(取决于你的硬件,这可能会需要一段时间):

- 在第105行和第106行中,我们编译模型并使用二元交叉熵而不是类别交叉熵。
对于多标签分类问题,这可能看起来有些违背了直觉;然而,目标是将每个输出标签视作一个独立伯努利分布,而且我们需要独立地惩罚每个输出节点。 - 随后我们启动运用了数据增强生成器的训练过程(第110-114行)。
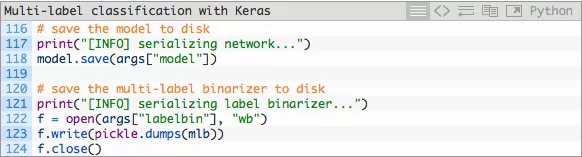
在完成训练之后我们可以将模型和标签二值化器储存至磁盘:
随后,我们绘制正确率及损失:

- 训练和验证的准确率+损失在第127-137行代码中绘画。该图片在第138行中被保存为一个图片文件。
在我看来,训练图像的绘制就跟模型本身一样重要。在我们满意并在博客上与你们分享之前,我通常会执行训练的几个迭代周期并查看图像是否无误。
在迭代过程中我喜欢讲图片存至硬盘上出于几个原因:
- 我在一个无界面的后台服务器上运行代码,也并不想依赖于X-forwarding
- 我不想忘记保存图片(即使我正在使用X-forwarding或是我正使用一个拥有图形化界面的机器)。
回想我们在上面将脚本的第三行改变了matplotlib的后端,就是为了帮助我们将图片储存至硬盘上。
为多标签分类训练一个Keras神经网络
请不要忘了使用本文底下的“下载”处来下载代码、数据集和预先训练好的模型(以防你不想自己训练模型)。
如果你想要自己训练模型,请打开终端。在那里,打开项目路径并执行如下命令:

如你所见,我们将模型训练了75个epoch,实现了:
- 98.57% 训练集上的多标签分类正确率
- 98.42% 测试集上的多标签分类正确率
训练图在图3中展示:

图3:我们的Keras深度学习多标签分类在训练集和测试集中的正确率/损失。
在新图片上应用Keras多标签分类
既然我们的多标签分类Keras模型已经训练好了,让我们将它应用在测试集之外的图片上。
这段脚本和我之前的博文中的classify.py中的十分相似,请务必小心多标签的区别。
当你准备好了以后,在项目路径下创建一个新的名为classify.py的文件并加入如下代码(或是遵循“下载”处所包含的文件)。

- 在第2-9行中,我们导入本脚本需要的包。尤其是Keras和OpenCV,我们在这个脚本中将用到它们。
- 随后在第12-19行,我们进一步将三个要求的命令行参数分词。
在这之后,我们加载并预处理输入图片:
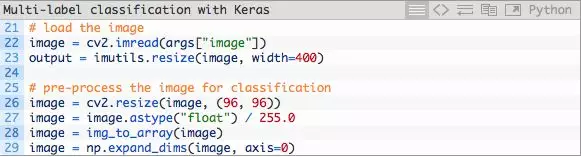
我们使用与训练数据相同的同一标准小心预处理图片。
随后,让我们加载模型+多标签二值化器并将图片分类:

- 我们在第34-35行代码中,从磁盘将模型和多标签二值化器加载至内存中。
随后我们分类(经过预处理的)图片(第40行)并通过如下方式解析出相关性最大的前两个类的标签索引:
- 基于相关概率将数组索引按降序排序
- 获取前两个类标签的索引,这便是我们的神经网络所作出的最好的两个预测。
如你需要,你可以修改这段代码以返回更多的类标签。我也建议你对概率设置阈值,并且只返回那些置信程度 > N%的标签。
然后我们将对每一个输出图像准备类标签+相关的置信值。

- 第44-48行的循环将可能性最大的两个多标签预测及相应的置信值绘制在输出图片上。
- 相似地,第51和第52行代码将所有的预测打印在终端上。这对于调试过程非常有用。
- 最后,我们在屏幕上显示输出图片(第55行和第56行代码)。
Keras多标签分类结果
让我们用命令行参数将classify.py执行。你不用为了传递新图片经由CNN而修改上述代码。你只需要按照下述步骤在终端中应用命令行参数。
让我们来试一张红色裙子的图片——请注意在运行过程中被处理的三个命令行参数:
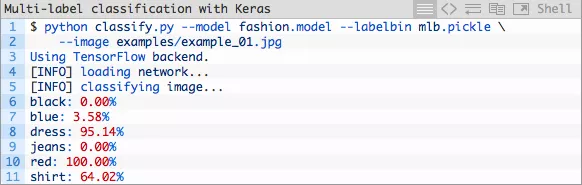

图片4:这张红色裙子的照片被我们的Keras多标签分类深度学习脚本由分类器正确分为“红色”和“裙子”。
我们成功了!请注意这两个类(“红色”和“裙子”)是如何被标注为高置信程度的。
现在让我们来试一条蓝色裙子:
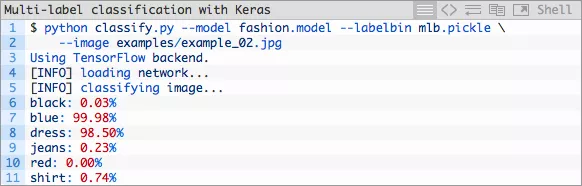

图片5:“蓝色”和“裙子”类标签在我们的Keras多标签图片分类项目的第二次测试中正确给出。
这条蓝色裙子对我们的分类器来说并不是什么难事。我们有了一个好的开端,让我们来试一张红色T恤:
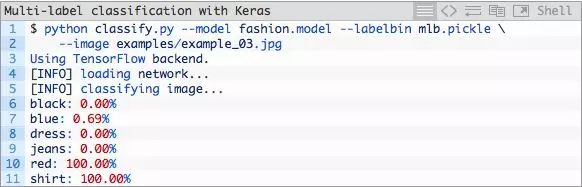

红色Polo衫的结果很棒。
如果是一件蓝色衬衫又会是怎样呢?
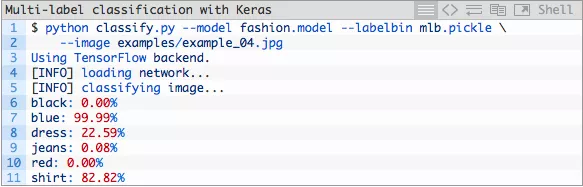

图片7:深度学习+多标签+Keras分类正确计算出了一件蓝色衬衫。
我们的模型非常确信它看到了蓝色,但有些许不自信它碰到了一件衬衫。话虽这么说,这仍然是一个正确的多标签分类!
让我们看看我们是否能够用一条蓝色牛仔裤骗过我们多标签的分类器:
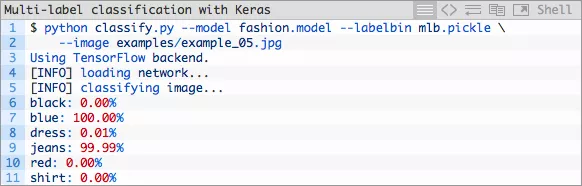

图片8:该深度学习多标签分类结果证明了这条牛仔裤可以同时被正确的分类为“蓝色”和“牛仔裤”。
让我们试试黑色牛仔裤:
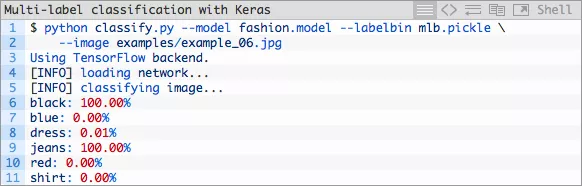

图片9:在该Keras深度学习多标签分类实验中,“牛仔裤”和“黑色”这两个标签都正确了。
我没法100%保证这是一条牛仔裤(在我看来他们更像是打底裤/紧身牛仔裤),但是我们的多标签确是能100%保证!
让我们最后来是一条黑色裙子(example_07.jpg)。当我们的神经网络已经学会如何预测“黑色牛仔裤”、“蓝色牛仔裤”、“蓝色裙子”和“红色裙子”时,它是否也能够被用来分类一条“黑色裙子”?
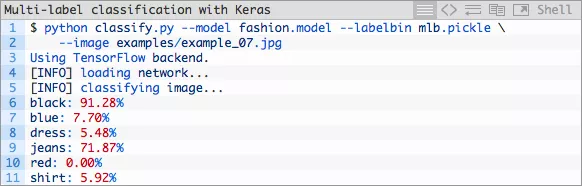

图片10:在这里发生了什么?我们的多类标签出错了。颜色被标注为“黑色”但是比起说这张图是一张“裙子”的图片,我们的分类器拥有更高的信心说这张图是一张“牛仔裤”的图片。
这是因为我们的神经网络在训练集中从来没有看见过这样的组合。请看底下的“总结”部分以获得更详尽的解释。
噢不——我们的分类器犯了个大错!我们的分类器报告说该模特身着黑色牛仔裤然而她实际穿着的黑色裙子。
在这里发生了什么?
为什么我们的多类预测出错了?想要知道原因的话,请检阅底下的总结。
总结
在今天的博文中,你学会了如何用Keras执行多标签分类。
应用Keras执行多标签分类是直观的,它包含两个主要的步骤:
- 在神经网络的最末端将softmax激活函数改为sigmoid激活函数。
- 将损失函数由分类交叉熵替换为二元交叉熵。
随后你便可以按平时的方法来训练该神经网络。
应用上述过程的最终结果是一个多类分类器。
你可以应用你的Keras多类分类器来预测多重标签,该过程仅需要一次的数据传递。
然而,你也需要考虑一些难点:你需要你想要预测的每种类别组合的训练数据。
正像是一个神经网络没法预测出一个它未曾训练过的类,你的神经网络没法预测出它未曾见过的多类标签组合。这个特性是由于神经网络内部神经元的激活函数。
如果你的神经网络同时经过:(1)黑色裤子(2)红色衬衫的训练,现在你希望预测“红色裤子”(你的数据集中没有“红色裤子”的图片),用于检测“红色”和“裤子”的神经元将会发生变化,但由于神经网络在之前从没见过这些数据/激活的组合,一旦他们到达了全连接层,你的输出预测就很有可能出错了(例如你可能会见到“红色”或者是“裤子”,但不太可能会同时见到这两个)。
再次重申,你的神经网络不能预测出它之前未曾训练过的数据(而且你也不该期望它能够预测出)。当你在训练你自己的多标签分类Keras神经网络时,请牢记这一点。
我希望你喜欢这篇博文!















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









