









 本文档详细介绍了在Windows系统中配置TensorRT的步骤,包括使用Python API检查精度支持和利用trtexec命令行工具进行模型转换。对于精度转换,需先了解GPU的CUDA计算能力以确定支持的精度模式。遇到网络动态shape问题时,推荐使用trtexec进行转化,提供示例命令行参数以完成不同精度的模型构建。
本文档详细介绍了在Windows系统中配置TensorRT的步骤,包括使用Python API检查精度支持和利用trtexec命令行工具进行模型转换。对于精度转换,需先了解GPU的CUDA计算能力以确定支持的精度模式。遇到网络动态shape问题时,推荐使用trtexec进行转化,提供示例命令行参数以完成不同精度的模型构建。
linux 环境类似,本篇针对 Windows 环境
按照这篇文章配置一下 TensorRT 的环境:
TensorRT windows10 安装过程记录
方法一:代码转化
可以直接用TensorRT Python API 中的 onnx Parser 来读取然后序列化模型并保存
但是,在这个过程中,实际上已经进行了构建,或者直接说,就是 build 过程,所以要进行精度转换到TF32、FP32或者INT8,就要在保存之前搞定。
要进行转换之前,先看看你的平台是否支持对应的精度:
-
要么根据你的显卡型号,在这里查看一下你的
CUDA计算能力版本—> CUDA计算能力表,然后更根据该版本,来查阅是否支持对应的精度 --> 硬件支持的精度模式
举个例子,我是 GTX1650Ti的显卡:
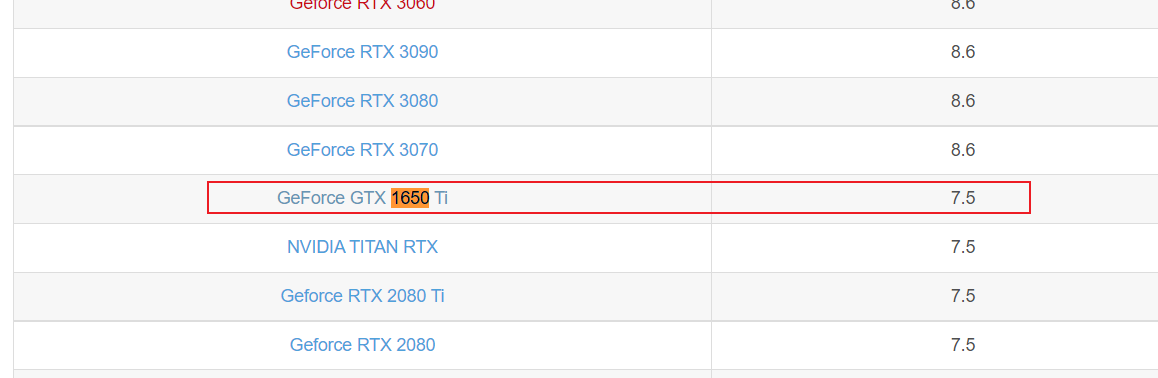
计算能力是7.5,然后查阅这个表格:
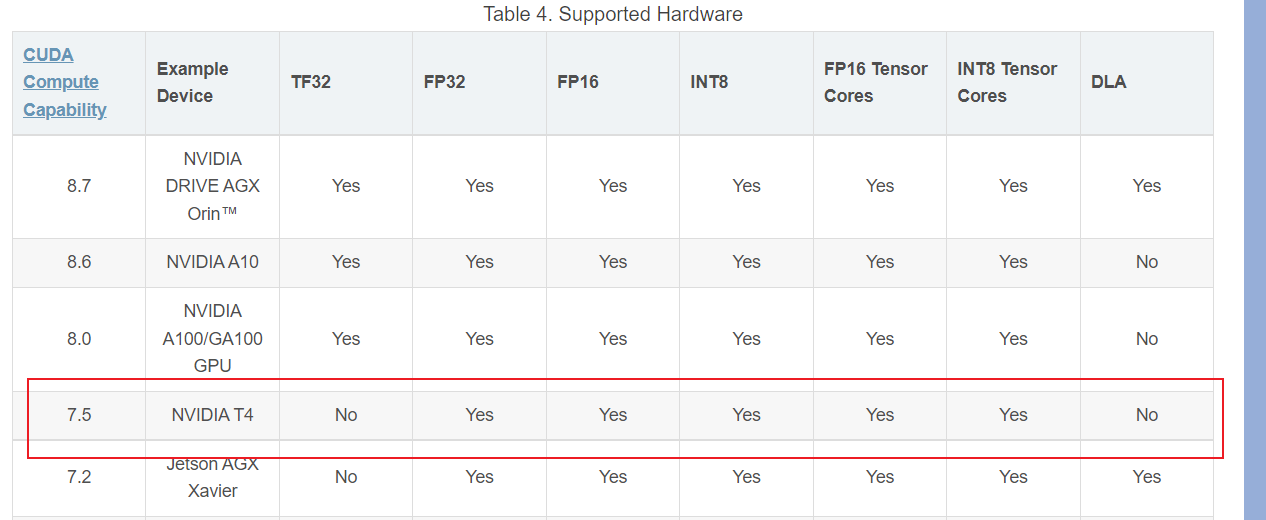
可以看到,该版本的卡不支持 TF32 和 DLA -
要么,根据 该博客的 API 来创建一个 builder,然后用这仨API来看看是否支持对应的精度:
import tensorrt as trt
logger = trt.Logger(trt.Logger.WARNING)
builder = trt.Builder(logger)
>>> builder.platform_has_fast_fp16
True
>>> builder.platform_has_fast_int8
True
>>> builder.platform_has_tf32
False
以上是GTX 1650Ti最后的精度支持情况
知道了精度支持情况,接下来,根据这篇博客的内容:Python API解析 的第一部分来进行转化即可
转化过程中,如何指定精度,可以参考这篇博客:
https://blog.csdn.net/HaoZiHuang/article/details/125830788
稍微提示一下,如果你不知道 Config 对象在哪,他是在 builder 已经创建之后才实例化的:
config = builder.create_builder_config()
额,还是参考这篇Python API解析
用脚本转换和用 onnx2trt 转化,都有同一个问题:
[07/29/2022-16:50:05] [TRT] [E] 4: [network.cpp::validate::2965] Error Code 4: Internal Error (Network has dynamic or shape inputs, but no optimization profile has been defined.)
[07/29/2022-16:50:05] [TRT] [E] 2: [builder.cpp::buildSerializedNetwork::636] Error Code 2: Internal Error (Assertion engine != nullptr failed. )
网络存在动态shape的问题,我至今没有解决,所以一直用 trtexec 来转换(也就是下边的方法二)
方法二:命令行转化
还记的我在这篇博客中提到一嘴的 trtexec 吗
命令行转化,就没有那么花里胡哨:
trtexec --onnx=output.onnx --saveEngine=outfp32.engine --workspace=2048 --minShapes=x:1x3x224x224 --optShapes=x:1x3x224x224 --maxShapes=x:1x3x224x224
trtexec --onnx=output.onnx --saveEngine=outfp16.engine --workspace=2048 --minShapes=x:1x3x224x224 --optShapes=x:1x3x224x224 --maxShapes=x:1x3x224x224 --fp16
trtexec --onnx=output.onnx --saveEngine=outfpi8.engine --workspace=2048 --minShapes=x:1x3x224x224 --optShapes=x:1x3x224x224 --maxShapes=x:1x3x224x224 --int8
trtexec --onnx=output.onnx --saveEngine=outfpbest.engine --workspace=2048 --minShapes=x:1x3x224x224 --optShapes=x:1x3x224x224 --maxShapes=x:1x3x224x224 --best
上边共有4行,分别是 fp32、fp16、int8 和 最优策略
最后一个 --best , 一般无脑选择这个就OK了,TensorRT的算法会自动去找最快的
然而实际上,不是你指定 --int8 他就一定是int8的,只是首选项是 --int8,具体可以再去看这篇关于精度的介绍:TensorRT 中 Reduced Precision, 看不懂的话就去看英文原文吧…
稍微说说其他参数:
--onnx=output.onnx # 要转化的 onnx 模型
--saveEngine=outfp32.engine # 输出的位置
--workspace=2048 # 设置工作区大小,单位是 MB
--minShapes=x:1x3x224x224 # 这是要校准模型的最小输入,输入张量名称为 `x`
--optShapes=x:1x3x224x224
--maxShapes=x:1x3x224x224
其实,我也不知道下边这三怎么翻译,hxd凑合着看吧:
--minShapes=spec Build with dynamic shapes using a profile with the min shapes provided
--optShapes=spec Build with dynamic shapes using a profile with the opt shapes provided
--maxShapes=spec Build with dynamic shapes using a profile with the max shapes provided
主要是前几个参数,后几个不重要hh


















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









