









全文摘自:
https://arxiv.org/pdf/2012.04150.pdf
1. 摘要
Arbitrary-oriented objects widely appear in natural scenes, aerial photographs(航拍), remote sensing images(遥感), etc., and thus arbitrary-oriented object detection has received considerable attention
Many current rotation detectors use plenty of anchors with different orientations to achieve spatial alignment with ground truth boxes.
许多旋转检测器使用大量具有不同方向的 Anchor 来实现与GT的空间对齐。
之前的现象:
Intersection-over-Union (IoU) is then applied to sample the positive and negative candidates
for training.
本文发现的痛点:
However, we observe that the selected positive anchors cannot always ensure accurate detections after regression, while some negative samples can achieve accurate localization.
It indicates that the quality assessment of anchors through IoU is not appropriate, and this further leads to inconsistency between classification confidence and localization accuracy.
这表明通过 IoU 对 anchor 的质量评估是不合适的,换句话说,这是导致分类置信度和定位精度之间的不一致的一个原因。(我喜欢这样翻译)
关于这个问题 [分类置信度和定位精度之间的不一致] ,我之前也浏览过这篇文章:
Rethinking the Misalignment Problem in Dense Object Detection
本文提出的方法以及达到的目标:
In this paper, we propose a dynamic anchor learning (DAL) method,
which utilizes the newly defined matching degree to comprehensively(全面) evaluate the localization potential of the anchors and carries out a more efficient label assignment process.
它利用新定义的匹配度来综合评估锚点的定位潜力,并进行更有效的标签分配过程。
In this way, the detector can dynamically select high-quality anchors to achieve accurate object detection, and the divergence between classification and regression will be alleviated.
这样检测器就可以动态选择高质量的 anchor 来实现准确的目标检测,从而缓解分类和回归之间的分歧。
本文达到的结果:
With the newly introduced DAL, we can achieve superior detection performance for arbitrary-oriented objects with only a few horizontal preset anchors.
使用 DAL,我们只需几个水平预设 anchors 就可以实现对任意方向目标的检测。
Experimental results on three remote sensing datasets HRSC2016, DOTA, UCAS-AOD as well as a scene text dataset ICDAR 2015 show that our method achieves substantial improvement compared with the baseline model.
Besides, our approach is also universal for object detection using horizontal bound box.
The code and models are available at https://github.com/ming71/DAL.
本文的方法也可以用在水平方向bbox的检测上.
2. 引言
一些客套话:
Object detection is one of the most fundamental and challenging problem in computer vision.
In recent years, with the development of deep convolutional neural networks (CNN), tremendous successes(巨大的成功) have been achieved on object detection (Ren et al. 2015; Dai et al. 2016; Redmon et al. 2016; Liu et al. 2016).
使用 anchor 的目的:
Most detection frameworks utilize preset horizontal anchors to achieve spatial alignment with groundtruth(GT) box.
噢噢噢噢,这就是 anchor-base中 标签分配的意思啊:
Positive and negative samples are then selected through a specific strategy during training phase, which is called label assignment.
然后在训练阶段通过特定策略选择正负样本,这称为标签分配。
旋转目标检测(定向目标检测) 的客套话:
Since objects in the real scene tend to appear in diverse orientations, the issue of oriented object detection has gradually received considerable attention.
引入额外的 方向预测 和 预设的旋转 anchors 来实现定向目标检测
There are many approaches have achieved oriented object detection by introducing the extra orientation prediction and preset rotated anchors (Ma et al. 2018; Liao, Shi, and Bai 2018).
输入 IoU 与 输出 IoU
These detectors often follow the same label assignment strategy as general object detection frameworks. For simplicity, we call the IoU between GT box and anchors as input IoU, and the IoU between GT box and regression box as output IoU.
这些检测器通常遵循与 水平目标检测框架 相同的标签分配策略。
为简单起见,我们将 GT box 和 anchors 之间的 IoU 称为输入 IoU,将 GT box 和回归框之间的 IoU 称为输出 IoU。
The selected positives tend to obtain higher output IoU compared with negatives, because their better spatial alignment(空间对齐) with GT provides sufficient semantic knowledge, which is conducive(有利于) to accurate classification and regression.
选择的positives Anchor 与negatives Anchor 相比可能获得更高的输出IoU,因为它们与GT更好的空间对齐,提供了足够的语义知识,有利于准确的分类和回归。
本文痛点,与上文的假设不同:
However, we observe that the localization performance of the assigned samples is not consistent with the assumption mentioned above.
然而,我们观察到分配样本的定位性能与上述假设不一致。
As shown in Figure 1, the division of positive and negative anchors seems not always related to the detection performance.
如图 1 所示,正负锚的划分似乎并不总是与检测性能相关。

图一:就是 Anchor(红) 与 预测框(绿)的对比
高输入IoU Anchor并不一定产生好预测结果,在空间上对齐不佳的Anchor依旧可以预测的很好
Figure 1: Predefined anchor (red) and its regression box (green).
(a) shows that anchors with a high input IoU cannot guarantee perfect detection.
(b) reveals that the anchor that is poorly spatially aligned with the GT box still has the potential to localize object accurately.
Furthermore, we have counted the distribution of the anchor localization performance for all candidates to explore whether this phenomenon is universal.
此外,我们统计了所有候选者的 Anchor 定位性能分布,以探索这种现象是否普遍。
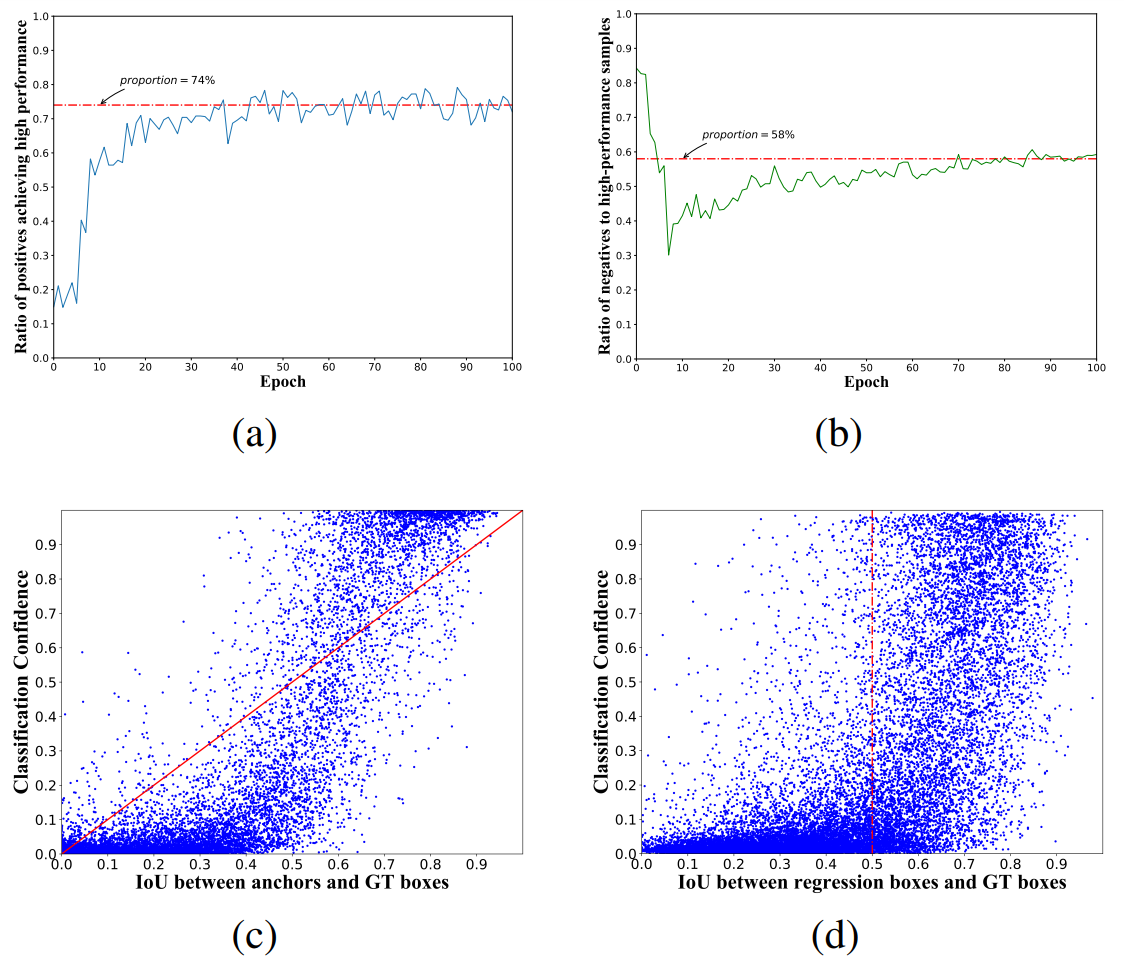
图二:
Figure 2: Analysis of the classification and regression capabilities of anchors that use input IoU for label assignment.
(a) Only 74% of the positive sample anchors can localize GT well after regression (with output IoU higher than 0.5), which illustrates that many false positive samples are introduced.
(说明引入了假正样本——false positive samples)
(输出IoU大于0.5的输出框才是好框)
(b) Only 42% of the high-quality detections (output IoU is higher than 0.5) come from matched anchors, which implies that quite a lot of negative anchors (58% in this example) have the potential to achieve accurate localization.
你这个42%不是负例中没有完成输出IoU大于0.5的比例么,为啥变成整体的了,哪里说明的
(c) Current label assignment leads to a positive correlation between the classification confidence and the input IoU.
当前标签分配导致分类置信度和输入 IoU 之间存在正相关。
(d) High-performance detection results exhibit a weak correlation between the localization ability and classification confidence, which is not conducive to selecting accurate detection
results through classification score during inference.
定位能力和分类置信度之间的相关性较弱,不利于在推理过程中通过分类置信度准确选择检测结果
(这里再次说明分类与回归的misalignment)
As illustrated in Figure 2(a), a considerable percentage (26%) of positive anchors are poorly aligned with GT after regression, revealing that the positive anchors cannot ensure accurate localization.
表明正 Anchor 不能确保准确的定位
Besides, more than half of the candidates that achieve high-quality predictions are regressed from negatives (see Figure 2(b)) which implies that a considerable number of negatives with high localization potential have not been effectively used.
这意味着相当多的具有高定位潜力的负 Anchor 没有得到有效使用。
In summary, we conclude that the localization performance does not entirely depend on the spatial alignment between the anchors and GT.
结论:定位性能并不完全取决于锚点和 GT 之间的空间对齐。
Besides, inconsistent localization performance before and after anchor regression further lead to inconsistency between classification and localization, which has been discussed in previous work (Jiang et al. 2018; Kong et al. 2019; He et al. 2019).
Anchor 回归前后不一致的定位性能进一步导致分类和定位之间的不一致,这在之前的工作中已经讨论过
As shown in Figure 2(c), anchor matching strategy based on input IoU induces a positive correlation between the classification confidence and input IoU. However, as discussed above, the input IoU is not entirely equivalent to the localization performance.
基于输入 IoU 的 Anchor 匹配策略在分类置信度和输入 IoU 之间产生正相关。 然而,如上所述,输入 IoU 并不完全等同于定位性能。
Therefore, we cannot distinguish the localization performance of the detection results based on the classification score.
因此,我们无法根据分类分数来区分检测结果的定位性能。
The results in Figure 2(d) also confirm this viewpoint (证实了这一观点): a large number of regression boxes with high output IoU are misjudged(误判) as background.
图二(d)中,分类置信度小于某一值(比如0.5)则会被判定为背景
到这里想说一下,这个图二真的是nice,很好地说明了分类和回归的misalignment
到这里开始说自己的方法了
To solve the problems, we propose a Dynamic Anchor Learning(DAL) method for better label assignment and further improve the detection performance.
Firstly, a simple yet effective standard named matching degree(标准匹配度) is designed to assess the localization potential of anchors(评估anchors的定位潜力), which comprehensively considers the prior information of spatial alignment, the localization ability and the regression uncertainty.
综合考虑空间对齐的先验信息、定位能力和回归不确定性
After that, we adopt matching degree for training sample selection, which helps to eliminate(消除) false-positive samples and dynamically mine potential high-quality candidates, as well as suppress the disturbance(干扰) caused by regression uncertainty.
采用匹配度进行训练样本选择,这有助于消除假阳性样本,动态挖掘潜在的高质量候选者,同时抑制回归不确定性带来的干扰。
Next, we propose a matching-sensitive(匹配敏感) loss function to further alleviate(缓解) the inconsistency between classification and regression, making the classifier more discriminative for proposals with high localization performance, and ultimately achieving high-quality detection.
接下来,我们提出了一种匹配敏感的损失函数,以进一步缓解分类和回归之间的不一致性,使分类器对具有高定位性能的 proposals 更具辨别力,最终实现高质量的检测。
Extensive(广泛) experiments on public datasets, including remote sensing datasets HRSC2016, DOTA, UCAS-AOD, and scene text dataset ICDAR 2015, show that our method can achieve stable and substantial(坚实) improvements for arbitraryoriented object detections.
Integrated with our approach, even the vanilla one-stage detector can be competitive with state-of-the-art methods on several datasets.
集成了我们的方法后,即使是普通的一阶段检测器也可以在多个数据集上与最先进的方法竞争。
对 hbb 也是通用的:
In addition, experiments on ICDAR 2013 and NWPU VHR-10 prove that our approach is also universal(通用) for object detection using horizontal box.
很通用,可以任意集成,而且不会增加推理的计算成本
The proposed DAL approach is general and can be easily integrated(集成) into existing object detection pipeline without increasing the computational cost of inference.
总结一下本文的贡献:
Our contributions are summarized as follows:
We observe that the label assignment based on IoU between anchor and GT box leads to suboptimal localization ability assessment, and further brings inconsistent classification and regression performance.
我们观察到基于anchor和GT box之间IoU的标签分配导致 定位能力评估 不理想,并进一步带来不一致的分类和回归性能。
提出 matching degree 来评估 localization potential of anchors.
提出了一种基于该度量的新型 label assignment method (标签分配方法),以实现高质量的检测。
The matching degree is introduced to measure the localization potential of anchors.
A novel label assignment method based on this metric is proposed to achieve highquality detection.
提出一个 matching-sensitive loss,缓解分类和回归之间相关性较弱的问题,提高对高质量proposals的辨别能力
The matching-sensitive loss is proposed to alleviate the problem of the weak correlation between classification and regression, and improves the discrimination ability of high-quality proposals.
3. Related Work
Arbitrary-Oriented Object Detection
Label Assignment
4. Proposed Method
(1). Rotation Detector Built on RetinaNet
RetinaNet baseline
ResNet50 backbone
The real-time inference is essential for arbitrary-oriented object detection in many scenarios. Hence we use the one-stage detector RetinaNet (Lin et al. 2017b) as the baseline model.
It utilizes ResNet-50 as backbone, in which the architecture similar to FPN (Lin et al. 2017a) is adopted to construct a multi-scale feature pyramid. Predefined horizontal anchors are set on the features of each level P 3 P_3 P3, P 4 P_4 P4, P 5 P_5 P5, P 6 P_6 P6, P 7 P_7 P7.
Note that rotation anchor is not used here, because it is inefficient and unnecessary, and we will further prove this point in the next sections. Since the extra angle parameter is introduced, the oriented box is represented in the format of ( x , y , w , h , θ ) (x, y, w, h, \theta) (x,y,w,h,θ).
注意这里没有使用旋转 Anchor,因为它效率低且没有必要,我们将在下一节进一步证明这一点。
For bounding box regression, we have:
t x = ( x − x a ) / w a , t y = ( y − y a ) / h a t w = log ( w / w a ) , t h = log ( h / h a ) t θ = tan ( θ − θ a ) \begin{array}{rlr} t_{x} & =\left(x-x_{a}\right) / w_{a}, & t_{y}=\left(y-y_{a}\right) / h_{a} \\ t_{w} & =\log \left(w / w_{a}\right), & t_{h}=\log \left(h / h_{a}\right) \\ t_{\theta} & =\tan \left(\theta-\theta_{a}\right) & \end{array} txtwtθ=(x−xa)/wa,=log(w/wa),=tan(θ−θa)ty=(y−ya)/hath=log(h/ha)
where x , y , w , h , θ x, y, w, h, \theta x,y,w,h,θ denote center coordinates(中心坐标), width, height and angle, respectively.
x x x and x a x_a xa are for the predicted box and anchor, respectively (likewise for y , w , h , θ y, w, h, \theta y,w,h,θ).
Given the ground-truth box offsets t ∗ = ( t x ∗ , t y ∗ , t w ∗ , t h ∗ , t θ ∗ ) \boldsymbol{t}^{*}=\left(t_{x}^{*}, t_{y}^{*}, t_{w}^{*}, t_{h}^{*}, t_{\theta}^{*}\right) t∗=(tx∗,ty∗,tw∗,th∗,tθ∗) , the multitask loss is defined as follows
L = L c l s ( p , p ∗ ) + L r e g ( t , t ∗ ) L=L_{c l s}\left(p, p^{*}\right)+L_{r e g}\left(\boldsymbol{t}, \boldsymbol{t}^{*}\right) L=Lcls(p,p∗)+Lreg(t,t∗)in which the value p p p and the vector t \boldsymbol{t} t denote predicted classification score and predicted box offsets, respectively.
p p p是预测的分类分数, t \boldsymbol{t} t是 pred 预测框的偏移量
Variable p ∗ p^{*} p∗ represents the class label for anchors ( p ∗ = 1 p^{*}=1 p∗=1 for positive samples and p ∗ = 0 p^{*}=0 p∗=0 for negative sample)
p ∗ p^{*} p∗是 anchors 的类别标签 ( p ∗ = 1 p^{*}=1 p∗=1 是正例 Anchor, p ∗ = 0 p^{*}=0 p∗=0 是负例)
(2). Dynamic Anchor Selection
Some researches (Zhang et al. 2019; Song, Liu, and Wang 2020) have reported that the discriminative features required to localize objects are not evenly distributed on GT, especially for objects with a wide variety of orientations and aspect ratios.
定位目标所需的判别特征在 GT 上分布不均,尤其是对于具有多种方向和纵横比的目标
Therefore, the label assignment strategy based on spatial alignment, i.e., input IoU, leads to the incapability to capture the critical feature demanded for object detection
基于空间对齐的标签分配策略,即输入 IoU,导致无法捕获目标检测所需的关键特征
An intuitive(直观) approach is to use the feedback of the regression results, that is, the output IoU to represent feature alignment ability and dynamiclly guide the training process.
一种直观的做法是利用回归结果的反馈,即输出 IoU 来表示特征对齐能力并动态指导训练过程
Several attempts (Jiang et al. 2018; Li et al. 2020) have been made in this respect.
In particular, we tentatively select the training samples based on output IoU and use it as soft-label for classification.
特别是,我们根据输出 IoU 初步选择训练样本并将其用作分类的软标签。
However, we found that the model is hard to converge(收敛) because of the following two issues:
Anchors with high input IoU but low output IoU are not always negative samples, which may be caused by not sufficient training.
输入IoU高 但 输出IoU低 的 Anchors 并不总是负样本,这可能是由于训练不足造成的。The unmatched low-quality anchors that accidentally achieve accurate localization performance tend to be misjudged as positive sample
The above analysis shows that regression uncertainty interferes(干扰) with the credibility of the output IoU for feature alignment(输出 IoU 对特征对齐的可信度).
这里说一下前人对回归不确定性的研究:Regression uncertainty has been widely discussed in many previous work (Feng, Rosenbaum, and Dietmayer 2018; Choi et al. 2019; Kendall and Gal 2017; Choi et al. 2018), which represents the instability and irrelevance in the regression process.
这代表了回归过程中的不稳定性和不相关性
We discovered in the experiment that it also misleads(误导) the label assignment.
Specifically, highquality samples cannot be effectively utilized, and the selected false-positive samples would cause the unstable training.
具体来说,就是 不能有效利用高质量的样本,选择的假阳性样本会导致训练不稳定
Unfortunately, neither the input IoU nor the output IoU used for label assignment can avoid the interference caused by the regression uncertainty.
不幸的是,无论是用于标签分配的输入 IoU 还是输出 IoU 都无法避免回归不确定性带来的干扰.
引出 matching degree (MD) 该指标用来衡量 localization capacity.
Based on the above observations, we introduce the concept of matching degree (MD), which utilizes the prior information of spatial matching, feature alignment ability and regression uncertainty of the anchor to measure the localization capacity, which is defined as follows
m d = α ⋅ s a + ( 1 − α ) ⋅ f a − u γ md=\alpha \cdot s a+(1-\alpha) \cdot fa-u^{\gamma} md=α⋅sa+(1−α)⋅fa−uγ
where
- s a sa sa denotes a priori of spatial alignment, whose value is equivalent to input IoU.
- f a fa fa represents the feature alignment capability calculated by IoU between GT box and regression box. (这不就是那个输出IoU??)
- α \alpha α and γ \gamma γ are hyperparameters used to weight the influence of different items.
- u u u is a penalty term, which denotes the regression uncertainty during training.
It is obtained via the IoU variation before and after regression:
u = ∣ s a − f a ∣ u=|sa - fa| u=∣sa−fa∣
The suppression of interference during regression is vital for high-quality anchor sampling and stable training.
回归过程中干扰的抑制对于高质量的 anchor 采样和稳定训练至关重要
Variation of IoU before and after regression represents the probability of incorrect anchor assessment.
回归前后 IoU 的变化代表了 Anchor 评估不正确的概率
Note that our construction of the penalty term for regression uncertainty is very simple, and since detection performance is not sensitive to the form of u , the naive, intuitive yet effective form is employed.
请注意,我们为回归不确定性构建的惩罚项非常简单,并且由于检测性能对 u u u 的形式不敏感,因此采用了朴素、直观但有效的形式
这个回归不确定性就是回归前后 IoU 的变化
With the newly defined matching degree, we conduct dynamic anchor selection for superior label assignment.
使用新定义的匹配度(matching degree, MD),我们进行动态 Anchor 选择以进行更好的标签分配
In the training phase, we first calculate matching degree between the GT box and anchors, and then the anchors with matching degree higher than a certain threshold (set to 0.6 in our experiments) are selected as positives, while the rest are negatives.
在训练阶段,我们首先计算GT box和anchors之间的匹配度,然后将匹配度高于一定阈值(我们实验中设置为0.6)的anchors选择为正例,其余为负例。
After that, for GT that do not match any anchor, the anchor with the highest matching degree will be compensated as positive candidate.
之后,对于不匹配任何anchor的GT,匹配度最高的anchor将被补偿为正候选。
To achieve more stable training, we gradually adjust the impact of the input IoU during training. The specific adjustment schedule is as follows:
α ( t ) = { 1 , t < 0.1 5 ( α 0 − 1 ) ⋅ t + 1.5 − 0.5 ⋅ α 0 , 0.1 ≤ t < 0.3 α 0 , t ≥ 0.3 \alpha(t)=\left\{\begin{array}{ll} 1, & t<0.1 \\ 5\left(\alpha_{0}-1\right) \cdot t+1.5-0.5 \cdot \alpha_{0}, & 0.1 \leq t<0.3 \\ \alpha_{0}, & t \geq 0.3 \end{array}\right. α(t)=⎩ ⎨ ⎧1,5(α0−1)⋅t+1.5−0.5⋅α0,α0,t<0.10.1≤t<0.3t≥0.3
where t = iters Max_Iteration t=\frac{\text { iters }}{\text {Max\_Iteration }} t=Max_Iteration iters , M a x _ I t e r a t i o n Max\_Iteration Max_Iteration is the total number of iterations, and α 0 \alpha_0 α0 is the final weighting factor that appears in Eq. (3).
(3). Matching-Sensitive Loss
To further enhance the correlation between classification and regression to achieve high-quality arbitrary-oriented detection,
为了进一步增强分类和回归之间的相关性以实现高质量的任意方向检测,
we integrate the matching degree into the training process and propose the matching-sensitive loss function(MSL).
The classification loss is defined as:
L c l s = 1 N ∑ i ∈ ψ F L ( p i , p i ∗ ) + 1 N p ∑ j ∈ ψ p w j ⋅ F L ( p j , p j ∗ ) L_{c l s}=\frac{1}{N} \sum_{i \in \psi} F L\left(p_{i}, p_{i}^{*}\right)+\frac{1}{N_{p}} \sum_{j \in \psi_{p}} w_{j} \cdot F L\left(p_{j}, p_{j}^{*}\right) Lcls=N1i∈ψ∑FL(pi,pi∗)+Np1j∈ψp∑wj⋅FL(pj,pj∗)
where ψ \psi ψ and ψ P \psi_P ψP respectively represent all anchors and the positive samples selected by the matching degree threshold.
其中 ψ \psi ψ和 ψ P \psi_P ψP分别代表所有 anchors 和 匹配度阈值选择的正样本。
N N N and N p N_p Np denote the total number of all anchors and positive anchors, respectively.
F L ( ⋅ ) FL(·) FL(⋅) is focal loss defined in RetinaNet (Lin et al. 2017b).
w j w_j wj indicates the matching compensation(补偿) factor, which is used to distinguish positive samples of different localization potential.
这是其实就是匹配度?? 继续往下看,不是,是匹配度加个常数
For each groundtruth g g g, we first calculate its matching degree with all anchors as m d \boldsymbol{md} md.
对每一个GT计算所有anchor的匹配度.
Then positive candidates can be selected according to a certain threshold, matching degree of positives is represented as m d p o s md_{pos} mdpos, where m d p o s ⊆ m d \boldsymbol{md}_{pos} \subseteq \boldsymbol{m d} mdpos⊆md.
然后可以根据一定的阈值选择正例,正例的匹配度表示为 m d p o s md_{pos} mdpos,其中 m d p o s ⊆ m d \boldsymbol{md}_{pos} \subseteq \boldsymbol{md} mdpos⊆md。
Supposing that the maximal matching degree for g g g is m d m a x md_{max} mdmax, the compensation value is denoted as Δ m d \Delta md Δmd, we have
Δ m d = 1 − m d max \Delta m d=1-\boldsymbol{md}_{\max } Δmd=1−mdmax
After that, Δ m d \Delta md Δmd is added to the matching degree of all positives to form the matching compensation factor
w = m d p o s + Δ m d \boldsymbol{w}=\boldsymbol{m} \boldsymbol{d}_{p o s}+\Delta m d w=mdpos+Δmd
With the well-designed matching compensation factor, the detector treats positive samples of different localization capabilit distinctively.
通过精心设计的匹配补偿因子,检测器区分不同定位能力的正样本。
In particular, more attention will be paid to candidates with high localization potential for classifier.
特别是,将更加关注具有高定位潜力的候选分类器。
Therefore, high-quality predictions can be taken through classification score, which helps to alleviate the inconsistency between classification and regression.
因此,可以通过分类得分进行高质量的预测,这有助于缓解分类和回归之间的不一致。
Since matching degree measures the localization ability of anchors, and thus it can be further used to promote highquality localization.
由于匹配度衡量了anchors的定位能力,因此可以进一步用于促进高质量的定位。
We formulate the matching-sensitive regression loss as follows:
L r e g = 1 N p ∑ j ∈ ψ p w j ⋅ L smooth L 1 ( t j , t j ∗ ) L_{r e g}=\frac{1}{N_{p}} \sum_{j \in \psi_{p}} w_{j} \cdot L_{\text {smooth }_{L_{1}}}\left(\boldsymbol{t}_{\boldsymbol{j}}, \boldsymbol{t}_{\boldsymbol{j}}^{*}\right) Lreg=Np1j∈ψp∑wj⋅Lsmooth L1(tj,tj∗)
where L s m o o t h L 1 L_{smooth_{L1}} LsmoothL1 denotes the s m o o t h − L 1 smooth-{L1} smooth−L1 loss for regression.
Matching compensation factor w w w is embedded into regression loss
to avoid the loss contribution of high-quality positives being submerged in the dominant loss of samples with poor spatial alignment with GT boxes.
匹配补偿因子 w w w被嵌入到回归损失中,以避免高质量正样本的 l o s s loss loss 被淹没在与GT框空间对齐不佳的样本的 l o s s loss loss中。
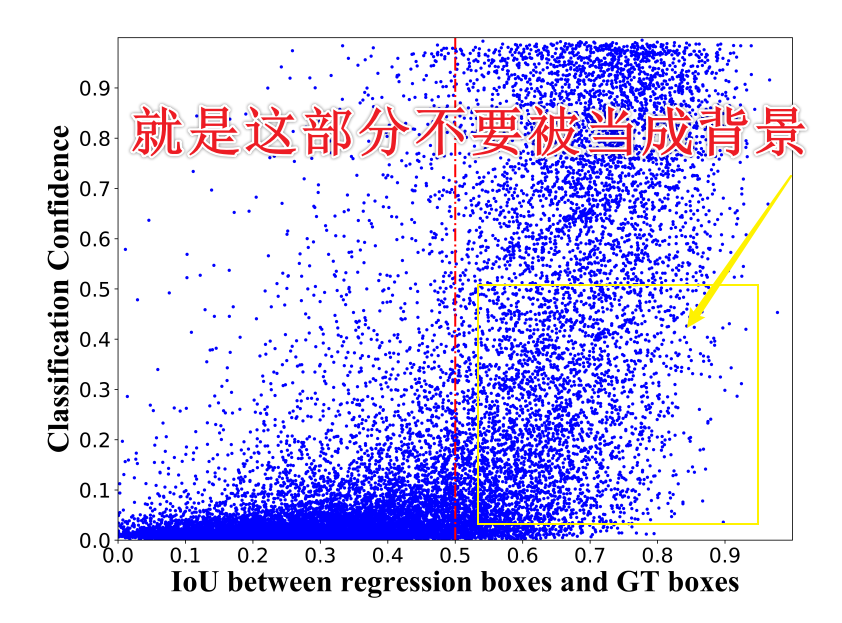
It can be seen from Figure 3(a) that the correlation between the classification score and the localization ability of the regression box is not strong enough, which causes the prediction results selected by the classification confidence to be sometimes unreliable.
从图3(a)可以看出,分类得分与回归框定位能力的相关性不够强,导致分类置信度选择的预测结果有时不可靠。
After training with a matching-sensitive loss, as shown in Figure 3(b), a higher classification score accurately characterizes the better localization performance represented by the output IoU, which verifies the effectiveness of the proposed method.
在使用匹配敏感损失进行训练后,如图 3(b) 所示,较高的分类分数准确地表征了输出 IoU 所代表的更好的定位性能,这验证了所提出方法的有效性。

Figure 3: The correlation between the output IoU and classification score with and without MSL(matching-sensitive loss).
图 3:输出 IoU 与有和没有 MSL 的分类分数之间的相关性。
有没有一种可能,不是你相关性变强了,而是你把不相关的过滤了??
5. Experiment
6. Conclusion
In this paper, we propose a dynamic anchor learning strategy to achieve high-performance arbitrary-oriented object detection.
Specifically, matching degree is constructed to comprehensively(全面) considers the spatial alignment, feature alignment ability, and regression uncertainty for label assignment.
Then dynamic anchor selection and matching-sensitive loss are integrated into the training pipeline to improves the high-precision detection performance and alleviate(缓解) the gap between classification and regression tasks.
Extensive experiments on several datasets have confirmed the effectiveness and universality of our method.
下一篇,我来写一写 RetinaNet, RetinaNet 的 Anchor,以及 matching-sensitive loss.














 2267
2267











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









