







遥感第二篇读了DAL,也是本校自动化专业前辈的工作。本篇也是参考了其自己的博客用于学习和总结,附上链接。个人认为这篇的流畅程度+严谨程度要胜过S2ANet。
总体理解
S2ANet从网络结构入手,主要是通过Align Conv解决旋转框检测的问题;而DAL则是从训练时的Label Assignment过程入手,提出新的"match degree"(md,匹配度)来作为label assignment的指标,同时利用md修改了Loss(Matching Sensitive Loss, MSL)“增强分类器对高质量样本的识别效果,从而解决Motivation中提到的分类回归不一致的问题”。因此DAL文章的实验中看到了S2ANet+DAL这样的组合结果,说明其作为模块的嵌入性很好。
我认为本文的一大亮点就是先通过统计的方法在一个数据集上做出实验,说明问题确实存在,再将自己的改进方法应用,得到一个更好的结果。同时,做了很多数据集的测试(见论文),还有将其改进到前人工作的结果。工作量很大,但要非说不好的话,就是Idea改一下网络结构应该就能上更高的顶会。(个人猜测因为是自动化的学生,学习不少最优化的理论,我也是上过zfm老师的课,里面md设置和Loss都很最优化理论。也许是对网络结构的研究不是很深入,希望通过改变评估方法,或者说目标函数的方式让网络有更好的泛化性且更容易收敛。如果能建更好的模型就妙极了。)
文章内容摘录
Abstract
先标注出文中作者定义的两个比较关键的名词:Input IoU(指GT box和anchor之间);Output IoU(指的是GT box和regression box之间)。
论文的核心观点就是对原来用IoU作label Assignment(不懂这个什么一丝的看这篇,https://zhuanlan.zhihu.com/p/395386669)的这一过程发出质疑,现象就是:因为旋转框检测中,一些高IoU的anchor并不一定能保证准确定位,反而一些低IoU的anchor也能一定程度做好的回归定位。Figure 1做了很好的阐述。
作者就提出了一个matching degree来重新评估anchor的质量,以此改进label assignment的过程。注意,作者说他用的是传统horizontal anchor,并在很多数据集和模型做了实现,效果很好很universal。
Intro
开头也是惯例介绍OD问题,一句话也说明什么是label Assignment。介绍之前的工作很多都用旋转anchor或者是orientation预测等方法。然后提出以上方法都使用相同的label Assign方法,但是这个方法经过作者的统计,发现了以下问题:
原作者的blog,这部分原作写的太妙了。这种实验精神很值得学习。我这里直接引用以下。第一条对应a,b图,第二条对应c图,第三条对应d图。
(1)74%左右的正样本anchor回归的pred box后依然是高质量样本(IoU>0.5);近一半的高质量样本回归自负样本,这说明负样本还有很大的利用空间,当前基于输入IoU的label assignment选正样本的效率并不高,有待优化。
(2)基于输入IoU的标签分配会诱导分类分数和anchor初始定位能力成正相关。而我们期望的结果是pred box的分类回归能力成正相关。划分样本的时候指定的初始对齐很好的为正样本,其回归后就算产生了不好的预测结果,分类置信还是很高,因为分类回归任务是解耦的;反之很多初始对齐不好的anchor被分成负样本,即使能预测好,由于分数很低,无法在inference被输出。
(3)进一步统计了预测结果的分布如d,可以看到在低IoU区间分类器表现还行,能有效区分负样本,但是高IoU区间如0.7以上,分类器对样本质量的区分能力有限。【问:表面上右半区密密麻麻好像分类器完全gg的样子,但是我们正常检测器并没有出现分类回归的异常高分box的定位一般也不赖,为什么?一是由于很多的IoU 0.5以上的点都是负样本的,即使定位准根本不会被关注到;二是预测的结果中,只要有高质量的能被输出就行了,其他都会被NMS掉,体现在图中就是右上角可以密密麻麻无所谓,但右下角绝不能有太多点。】
————————————————
版权声明:本文为CSDN博主「ming7771」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/mingqi1996/article/details/111250036

所以得出一个结论:anchor和GT的对其程度和回归的准确度没有直接关系。
第二个问题就是cls和reg的inconsistency(这个在很多论文都有提到过)
因此作者提出一个新的matching degree:考虑到空间对齐的先验信息、坐标回归的能力以及回归的不确定性(这个没有太理解什么意思,但我直观理解就是最后的那个罚项的作用)。然后紧接说提出一个Loss:MSL,作用摘要提到过。
Related Work
这部分原作者blog没有写,我简单几句话带过。
Arbitrary-Oriented Object Detection
还是套话地讲当下主流检测器的方法,也基本上回顾了旋转检测的方法。认为前作的问题是没法正确评估anchor质量,也就是正负样本划分的问题。
Label Assignment
紧接上文,前人的工作有:主动筛选、Focal Loss、减少负样本的影响。有的用Input IoU、考虑label的noise影响、以及HAMBox、FreeAnchor用最大似然估计。
Proposed Method
Rotation Detector Built on RetinaNet
主要在RetinaNet基础上改了需要回归的输出,现在为(
x
x
x,
y
y
y,
w
w
w,
h
h
h,
θ
\theta
θ)这五元的结果。同时GTbox也是这样的形式。再次基础上定义了Loss:
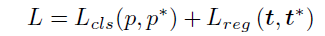
Dynamic Anchor Selection
这里主要讨论一个问题,就是能不能用output IoU作为判别正负样本的指标。作者做实验发现不行。主要因为:高input IoU,低output IoU的anchor,不一定是负样本,因为训练不足。同时,低质量的anchor(我认为此处指的是训练前IoU极低,训练后极高IoU,不能被认为成正样本。(这几句话其实不是很清楚,很实验的结果,很Intuitive。)
上述的问题,作者称之为regression uncertainty,前人的工作也有这方面的研究。
面对以上问题,作者提出了MD,公式为:
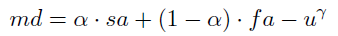
分别处理空间对齐的先验信息、坐标回归的能力以及回归的不确定性。sa,fa分别为input IoU和output IoU。md应该是越大越好,最后的
u
u
u应该是越小越好,定义为sa和fa之差的绝对值。这个罚项就用来确保“high quality anchor sampling and stable training”。在训练时,先计算GT和anchors之间的MD矩阵,以一个阈值划分正负样本。同时根据训练的轮数动态调整
α
\alpha
α。
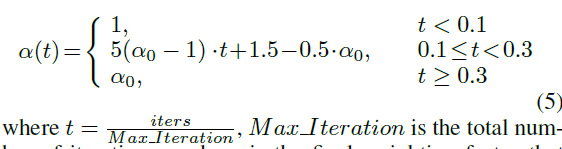
再然后就是比较核心的MSL(matching-sensitive Loss),也就是把之前的MD指标带进去。分为cls loss和reg loss:
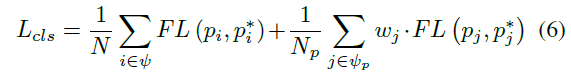

本质上分别是对Focal Loss和smooth L1的改进。用md的地方就是对于
ϕ
p
\phi_p
ϕp,对正样本进行补偿加权。好处引用原作者的博客:
补偿加权的方法相比直接加权有两个好处:
避免分类器对匹配度划定的负样本进行不合理的关注。比如在md补偿的策略下,一个低质量正样本可能导致很大的补偿值从而带来一堆低质量正样本;
由于匹配度是介于[0,1],直接加权将导致正样本被进一步稀释;
确保分类和回归任务对补偿的anchor的足够关注,每个样本至少有一个anchor能学好。例如对于某个gt最大md为0.2,直接加权将导致其loss贡献很小,本来就难匹配的目标更难学了。
————————————————
版权声明:本文为CSDN博主「ming7771」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/mingqi1996/article/details/111250036
具体实现就是先计算一个GT和anchors的MD(s)。然后通过阈值筛选正样本(其实就是anchors),得到最大的
m
d
m
a
x
md_{max}
mdmax。计算的到补偿值Δ
m
d
md
md=
(
1
−
m
d
m
a
x
)
(1-md_{max})
(1−mdmax)。然后
w
w
w=
m
d
p
o
s
md_{pos}
mdpos+Δ
m
d
md
md。
同时这个
w
w
w也被用到了reg loss里。
Loss的好处就如下图:可以看到cls和reg都在比较高的数值,有一定的性能上的相关性。

Experiments
Implementation Details
Ablation Study

可以看到,如果直接加Ouput IoU,精度反而下降。因为特征对齐的信息并不能被有效的利用,而且训练中Output IoU变化剧烈,所以其对应的系数一边画就容易不收敛。这样的实验也就验证了MD对anchor localization能力的区分,然后md加入Loss后,对高质量anchor的正向作用。
作者还对超参数设置做了些实验。

这部分分析引用下原作者的:
匹配度的设置实际上引入了两个额外的超参数,因此补充了敏感性实验如下。表中的结果和分析结论基本一致:当不确定性抑制项存在,α \alphaα合理减小会使特征对齐的影响增大,同时mAP增大,说明能够输出IoU能够有效指导样本划分过程。如果α \alphaα过大将使得空间对齐能力占主导地位,输出IoU带来的不稳定减小,此时不应施加很强的扰动惩罚,即减小γ \gammaγ的值,如α \alphaα=0.9时,γ \gammaγ从3减小到5,mAP从70.1提升到83.5。
此外,正如上面所说,其实s a sasa也就是正常的IoU完全可以不要,仅靠f a fafa和u uu就能取得更好的结果,但是很敏感anchor设置和γ \gammaγ取值以及u uu的形式,比较难调。
这为匹配度公式的参数调试提供一种思路:α \alphaα和γ \gammaγ应该同时增大或减小。此外观察不难发现,α \alphaα在0.3-0.5的效果是最好的,γ \gammaγ也大致可以确定。这个结论在其他数据集和其他anchor设置上也验证过,依然成立,论文篇幅有限这里没有予以展示。但是说实话,取值而言会有偏移,虽然不会太多但是还是要调一调,这个有点不快乐。
————————————————
版权声明:本文为CSDN博主「ming7771」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/mingqi1996/article/details/111250036















 4907
4907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











