







文章目录
实验三、scikit-learn决策树算法
一、实验目的
1. 熟悉掌握决策树的原理
2. 使用scikit-learn库中的对应函数实现决策树分类。
二、能力图谱
三、实验工具
1. Anaconda
2. sklearn
四、实验内容
scikit-learn决策树算法类库内部实现是使用了调优过的CART树算法,既可以做分类,又可以做回归。分类决策树的类对应的是DecisionTreeClassifier。
1.对鸢尾花数据集建立决策树
(1) 鸢尾花数据集
在Sklearn机器学习包中,集成了各种各样的数据集,包括前面的糖尿病数据集,这里引入的是鸢尾花卉(Iris)数据集,它是很常用的一个数据集。鸢尾花有三个亚属,分别是山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。
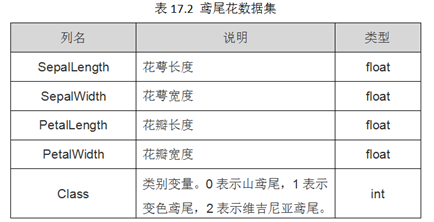
该数据集一共包含4个特征变量,1个类别变量。共有150个样本,iris是鸢尾植物,这里存储了其萼片和花瓣的长宽,共4个属性,鸢尾植物分三类。如表17.2所示:
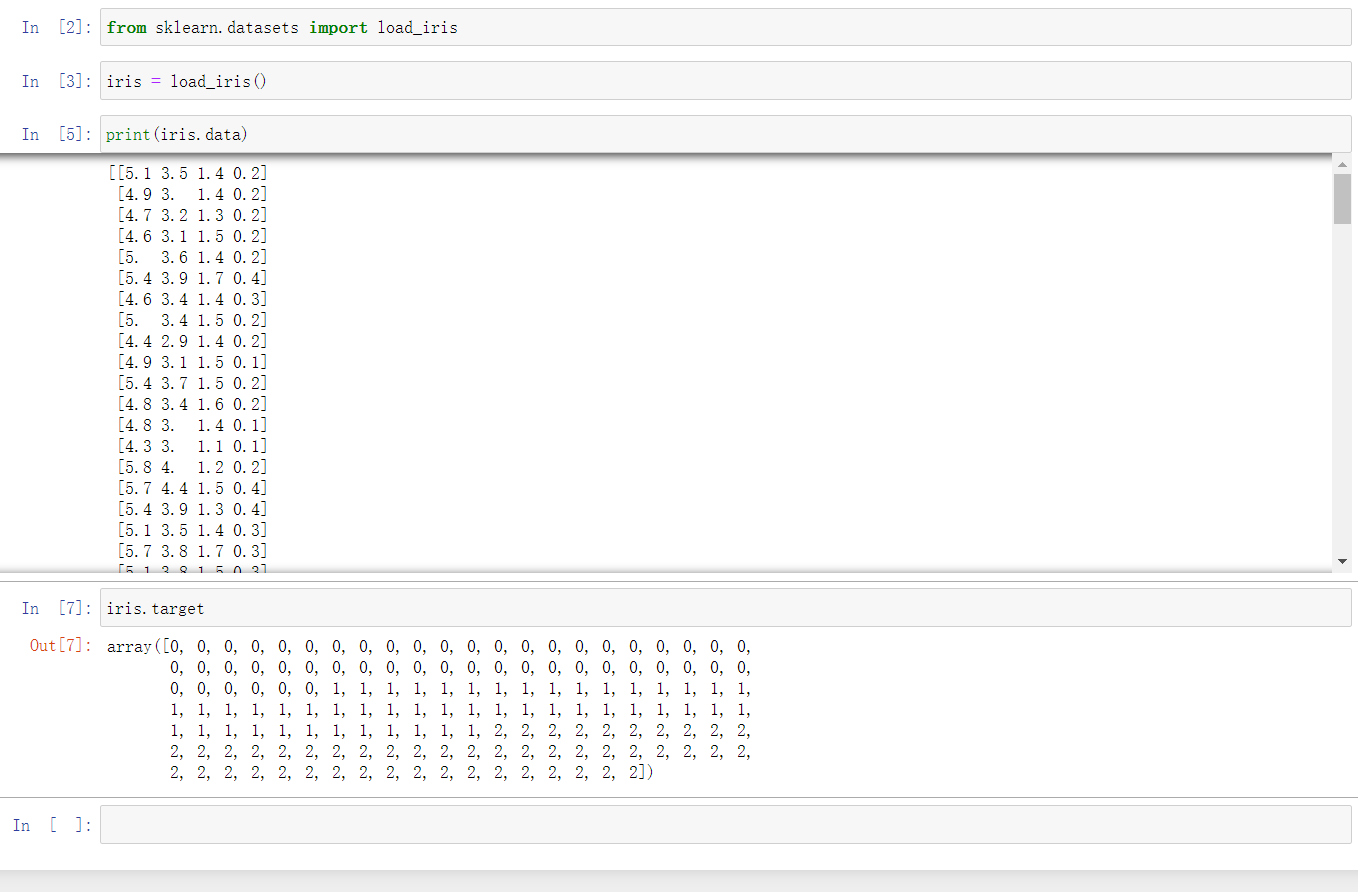
iris里有两个属性iris.data,iris.target。data是一个矩阵,每一列代表了萼片或花瓣的长宽,一共4列,每一行代表某个被测量的鸢尾植物,一共采样了150条记录。
from sklearn.datasets import load_iris #导入数据集iris
iris = load_iris() #载入数据集
print iris.data
#[n_samples,n_features]
iris.target
(2) 决策树分类
(1)导入模块
(2)载入iris数据集
(3)提取特征
(4)输出结果
#导入模块
import numpy as np
%matplotlib auto
import matplotlib.pyplot as plt
from sklearn import 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1403
1403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









