






顺序、折半、分块、哈希 四种查找算法分析
1. 顺序查找
设想有一个1M的数据,我们如何在里面找到我们想要的那个数据。此时数据本身没有特征,所以我们需要的那个数据可能出现在数组的各个位置,可能在数据的开头位置,也可能在数据的结束位置。这种性质要求我们必须对数据进行遍历之后才能获取到对应的数据。
int find(int array[], int len, int val)
{
if(array == NULL && length == 0) return -1;
for(int i=0;i<len;i++){
if(val == array[i])
return i;
}
return -1;
}分析:由于我们不清楚这个数据判断究竟需要多少次。但是,我们知道,这样一个数据查找最少需要1次,那么最多需要n次,平均下来可以看成是(1+n)/2,差不多是n的一半。我们把这种比较次数和n成正比的算法复杂度记为o(n)。
2. 二分查找
如果数据排列地非常整齐,那结果会是什么样的呢?就像在生活中,如果平时不注意收拾整齐,那么找东西的时候非常麻烦,效率很低;但是一旦东西放的位置固定下来,所有东西都归类放好,那么结果就不一样了,我们就会形成思维定势,这样查找东西的效率就会非常高。那么,对一个有序的数组,我们应该怎么查找呢?二分法就是最好的方法。
int BinaryFind(int array[], int len, int val)
{
if(array == NULL && length == 0) return -1;
int start = 0, end = len-1, middle=0;
while(start<=end){
middle = (start + end)/2; //取整
if(val == array[middle]) return middle;
else if(val > array[middle]) start = middle+1;
else end = middle-1;
}
return -1;
}分析:上面我们说到普通的数据查找算法复杂度是o(n)。那么我们可以用上面一样的方法判断一下算法复杂度。这种方法最少是1次,那么最多需要多少次呢?我们发现最多需要log(n+1)/log(2)即可。
3. 二叉搜索树
二叉搜索树是二分查找的二叉树实现,二叉搜索树每个结点都有作为搜索依据的关键码,,所有结点的管家吗互不相同;左子树(若存在)上的所有结点的关键码都小于根结点的关键码;右子树(若存在)上的所有结点的关键码都大于根结点的关键码;左子树和右子树也是二叉搜索树。
typedef struct _NODE
{
int data;
struct _NODE* left;
struct _NODE* right;
}NODE;
const NODE* find_data(const NODE* pNode, int data){
if(NULL == pNode)
return NULL;
if(data == pNode->data)
return pNode;
else if(data < pNode->data)
return find_data(pNode->left, data);
else
return find_data(pNode->right, data);
}4. Hash表
typedef struct _LINK_NODE
{
int data;
struct _LINK_NODE* next;
}LINK_NODE;
LINK_NODE* hash_find(LINK_NODE* array[], int mod, int data)
{
int index = data % mod;
if(NULL == array[index])
return NULL;
LINK_NODE* pLinkNode = array[index];
while(pLinkNode){
if(data == pLinkNode->data)
return pLinkNode;
pLinkNode = pLinkNode->next;
}
return pLinkNode;
}分析:hash表因为不需要排序,只进行简单的归类,在数据查找的时候特别方便。查找时间的大小取决于mod的大小。mod越小,那么hash查找就越接近于普通查找;那么hash越大呢,那么hash一次查找成功的概率就大大增加。
5.分块查找
分块查找是顺序查找的一种改进方法。
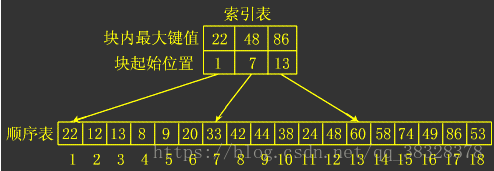
首先须要对数组进行分块,分块查找须要建立一个“索引表”。索引表分为m块,每块含有N/m个元素,块内是无序的,块间是有序的,比如块2中最大元素小于块3中最小元素。
先用二分查找索引表。确定须要查找的keyword在哪一块,然后再在对应的块内用顺序查找。
分块查找又称为索引顺序查找。时间复杂度:O(log(m)+N/m)
要求是顺序表,分块查找又称索引顺序查找,它是顺序查找的一种改进方法。
算法思想:
将n个数据元素"按块有序"划分为m块(m ≤ n)。
每一块中的结点不必有序,但块与块之间必须"按块有序";
即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字;
而第2块中任一元素又都必须小于第3块中的任一元素,……
/**
* 分块查找
*
* @param index
* 索引表,其中放的是各块的最大值
* @param st
* 顺序表,
* @param key
* 要查找的值
* @param m
* 顺序表中各块的长度相等,为m
* @return
*/
public static int blockSearch(int[] index, int[] st, int key, int m) {
// 在序列st数组中,用分块查找方法查找关键字为key的记录
// 1.在index[ ] 中折半查找,确定要查找的key属于哪个块中
int i = binarySearch(index, key);
if (i >= 0) {
int j = i > 0 ? i * m : i;
int len = (i + 1) * m;
// 在确定的块中用顺序查找方法查找key
for (int k = j; k < len; k++) {
if (key == st[k]) {
System.out.println("查询成功");
return k;
}
}
}
System.out.println("查找失败");
return -1;
}















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









