







须知
我是一个代码小白(代码菜鸟),最近在学习机械学习和深度学习,也学习了有一段时间,但是没有发过博客,所以想挑战一下自己,也希望可以和大家多多交流(大佬轻点喷)
数据处理
数据说明:我是网上找的iris数据,共100个样本,我取70个为训练样本,30个为测试样本。每个样本为5个数据(4个数值和1个标签)链接:https://pan.baidu.com/s/1yXNUJSxo3X2cl6kKdwsluQ 提取码:ikpf

读取代码实现:
iris = pandas.read_csv("iris.txt",header=0,sep = ',')
shuffled_rows = np.random.permutation(iris.index)# #打乱数据顺序
# permutation不直接在原来的数组上进行操作,而是返回一个新的打乱顺序的数组,并不改变原来的数组。
iris.index = =shuffle_rows
m = iris.shape[0]#读取样本数
X = iris.iloc[0:int(m*0.7),:]#按照新的索引值进行排序
X.index = range(int(m*0.7))
Y = iris.iloc[int(m*0.7):m,:]
Y.index = range(m-int(m*0.7))
'''分出训练集和测试集'''
#训练集
x_train = X.iloc[:,0:4]#0,1,2,3列
y_train = X['species']#指定列
#测试集
x_test = Y.iloc[:,0:4]
y_test = Y['species']
# 将Iris-versicolor类标签设置为1,Iris-virginica设置为0
y_train = np.asarray((y_train=='Iris-versicolor').values.astype(int))
y_test = np.asarray((y_test== 'Iris-versicolor').values.astype(int))`
定义神经网络
learning_rate = 0.5
maxepochs = 10000
convergence_thres = 0.00001
hidden_units = 8
def sigmoid_activation(x, theta):
x = np.asarray(x)#array和asarray都可以将结构数据转化为ndarray,但是主要区别就是当数据源是ndarray时,array仍然会copy出一个副本,占用新的内存,但asarray不会。
theta = np.asarray(theta)
return 1 / (1 + np.exp(-np.dot(theta.T, x)))
class NNet3:
# 初始化必要的几个参数
def __init__(self, learning_rate=0.5, maxepochs=1e4, convergence_thres=1e-5, hidden_layer=4):
self.learning_rate = learning_rate
self.maxepochs = int(maxepochs)
self.convergence_thres = 1e-5
self.hidden_layer = int(hidden_layer)
# 计算最终的误差
def _multiplecost(self, X, y):
# l1是中间层的输出,l2是输出层的结果
l1, l2 = self._feedforward(X)
'''注意:这里的l2是(1,70),而y为(70,1),两个导入最大似然函数为(1,70)'''
# 计算误差,这里的l2是前面的h
inner = y * np.log(l2) + (1-y) * np.log(1-l2)
#inner就是最大似然函数的输出值了其shape为(1,70)跟l2是一样的维度,这里就是所谓输出值与实际值的误差了
# 添加符号,将其转换为正值
return -np.mean(inner)
# 前向传播函数计算每层的输出结果
def _feedforward(self, X):
# l1是中间层的输出
l1 = sigmoid_activation(X.T, self.theta0).T
# print('l1.shape', l1.shape)#l1.shape (70, 8)里面有很多转置,但最后输出的形状是我们想要的
# 为中间层添加一个常数列
l1 = np.column_stack([np.ones(l1.shape[0]), l1])#np.column_stack的作用是将两个矩阵按照列进行合并,在之前加多一列
# print('l1.shape', l1.shape)#此时l1.shape = (70,9)偏置值为1
# 中间层的输出作为输出层的输入产生结果l2
l2 = sigmoid_activation(l1.T, self.theta1)
#l2.shape = (1,70)
return l1, l2
# 传入一个结果未知的样本,返回其属于1的概率
def predict(self, X):
_, y = self._feedforward(X)
return y
# 学习参数,不断迭代至参数收敛,误差最小化
def learn(self, X, y):
nobs, ncols = X.shape#nobs =70,ncols = 4
'''#normal第一个值为loc:概率分布的均值,对应着整个分布的中心center
第二个值为scale:概率分布的标准差,对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高
第三个值为:size,int or tuple of ints'''
self.theta0 = np.random.normal(0,0.01,size=(ncols,self.hidden_layer))
self.theta1 = np.random.normal(0,0.01,size=(self.hidden_layer+1,1))#考虑到偏置值bias,因此+1
# print(self.theta0.shape)#(4, 8)
# print(self.theta1.shape)#(9, 1)
self.costs = []
cost = self._multiplecost(X, y)#返回最大似然函数的损失值,为单个数,正值
'''这里的损失值=sum(每个样本代入神经网络,算出最大似然函数值).mean()。'''
self.costs.append(cost)
costprev = cost + self.convergence_thres+1
counter = 0
# Initialize model\
#model就是将NNet3实例化后的对象
model = NNet3(learning_rate=learning_rate, maxepochs=maxepochs,
convergence_thres=convergence_thres, hidden_layer=hidden_units)
model.learn(x_train, y_train)
#将训练模型定义为一个类别
具体完整函数在百度云中,函数中主要是对维度的把控,按照z = w.T*x + b计算输出值,采用激活函数为sigmoid函数,因为注释写的比较详细,按照主函数看下来应该看得懂,虽然代码可读性不高。
反向传播函数如下
**## 这里根据反向传播函数更新权重**
for counter in range(self.maxepochs):
# 计算中间层和输出层的输出
# l1是中间层的输出,l2是输出层的结果
l1, l2 = self._feedforward(X)
# 首先计算输出层的梯度,再计算中间层的梯度
l2_delta = (y-l2) * l2 * (1-l2)
l1_delta = l2_delta.T.dot(self.theta1.T) * l1 * (1-l1)
# print('l2_delta.shape',l2_delta.shape)
# print('11_delta.shape',l1_delta.shape)
# 原来更新参数
self.theta1 += l1.T.dot(l2_delta.T) / nobs * self.learning_rate
self.theta0 += X.T.dot(l1_delta[:,1:]) / nobs * self.learning_rate#y因为theta0没有偏置值,故要把之前加的的一列1去掉
counter += 1
costprev = cost
cost = self._multiplecost(X, y) # get next cost
self.costs.append(cost)
if np.abs(costprev-cost) < self.convergence_thres and counter > 500:
break
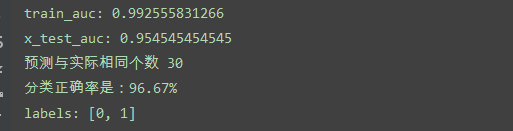
结果
可以将训练完的模型,重新对训练集进行预测,将y_train与结果进行对比。将测试集也放入模型中,其结果如下所示:

学习心得:
1. 首先就是文档的读取,我采用的是pandas的读取函数,pandas有三种 数据结构,分别是Series(一维数组),DataFrame(二维数据),Panel(三维数据,或者多维数据)
S = pd. Series([],index = []),D = pd.DataFrame(‘x’:[],index = [],colums=[])

Txt = pd.read_csv(dataset,sep=’’,header =0/None,index = Ture/False)
Dataset= 数据集,sep = 分隔符,默认为‘,’有的分隔符为一个或多个空格,sep = ‘/s+’。header(数据的列索引):如果保留就为0,没有就None。
Txt = pd.read_table()读取表格跟上述类似,间隔符 = ‘/t’,存储也类似,其函数为:Txt.to_excel,txt.to_csv等等
2. 有时候文本是有规律的,需要我们进行打乱,我们可以打乱数据集的索引,然后分割数据集,再重新赋值新的索引
方法一:l=numpy.random.permulation(dataset.index)
dataset.index = l#更新dataset的索引
m=int(dataset.shape[0]0.7)
X = dataset.iloc[0:m,:]
X.index = range(m))#然后分割后在赋值新的索引。
注意:permulation:作用是随机打乱原来的顺序,但不在原来的数据打乱,而是生成新的数组,因此不改变原来的数组。
而shuffle是在原来的基础上进行打乱
方法二:np.random.shuffle()
L = np.random.shuffle(dataset.index)
X_train = dataset.loc[range(int(dataset.shape[00.7])),:]#执行命令完就已经按照range排序了
3. pandas中iloc和loc的区别
dataset.iloc[],按照行或列来定位
dataset.loc[],按照行索引或列索引来取
其两者都是以0为开始的
4..np.column_stack(l1,l2)的作用是将两个矩阵按照列进行合并.
np.random.normal(loc,scale,size)
#normal第一个值为loc:概率分布的均值,对应着整个分布的中心center
第二个值为scale:概率分布的标准差,对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高
第三个值为:size,int or tuple of ints
5.反向传播
误差的计算–>权值的更新















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









