使用 Faiss 创建 Index ,利用 <id, feature vector> 数据生成索引。
针对待检索图片,使用模型提取图片特征向量,然后使用 Index 检索 TopK 相似图片的 id。
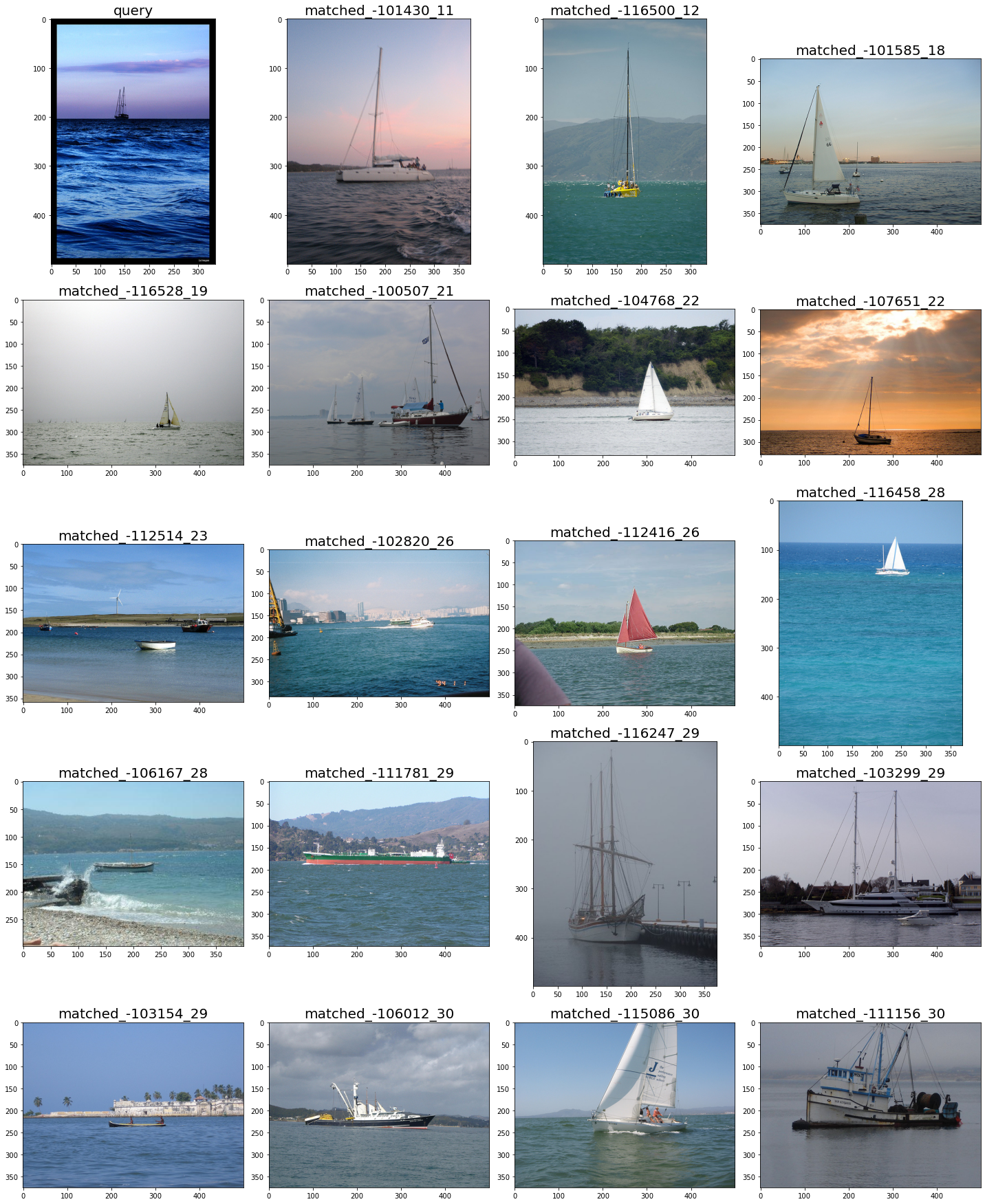
可视化检索结果
1. 导包
import os
import time
import torch
import faiss
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from torchvision import models, transforms
from torch.utils.data import DataLoader, Dataset
%matplotlib inline
GPU 加速
device = torch.device('cuda'if torch.cuda.is_available()else'cpu')print(device)# cuda
2.自定义数据集
transform = transforms.Compose([
transforms.Resize((256,256)),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])])classMyDataset(Dataset):def__init__(self, data_path, transform=None):super().__init__()
self.transform = transform
self.data_path = data_path
self.data =[]
img_path = os.path.join(data_path,'img.txt')withopen(img_path,'r', encoding='utf-8')as f:for line in f.readlines():
line = line.strip()
img_name = os.path.join(data_path, line)
img = Image.open(img_name)if img.mode =='RGB':
self.data.append(line)def__getitem__(self, idx):# take the data sample by it's index
img_path = os.path.join(self.data_path, self.data[idx])# read image
img = Image.open(img_path)# apply the transformif self.transform:
img = self.transform(img)# return the image and index
dict_data ={'index': idx,'img': img
}return dict_data
def__len__(self):returnlen(self.data)
# 加载预训练模型defload_model():
model = models.resnet18(pretrained=True)
model.to(device)
model.eval()return model
# 定义 特征提取器deffeature_extract(model, x):
x = model.conv1(x)
x = model.bn1(x)
x = model.relu(x)
x = model.maxpool(x)
x = model.layer1(x)
x = model.layer2(x)
x = model.layer3(x)
x = model.layer4(x)
x = model.avgpool(x)
x = torch.flatten(x,1)return x
model = load_model()for idx, batch inenumerate(val_dataloader):
img = batch['img']# 图片数据表示 --> 图片特征
index = batch['index']
img = img.to(device)
feature = feature_extract(model, img)
feature = feature.data.cpu().numpy()
imgs_path =[os.path.join(img_folder, val_dataset.data[i]+'.txt')for i in index]assertlen(feature)==len(imgs_path)for i inrange(len(imgs_path)):
feature_list =[str(f)for f in feature[i]]
img_path = imgs_path[i]withopen(img_path,'w', encoding='utf-8')as f:
f.write(" ".join(feature_list))print('*'*60)print(idx * batch_size)
4.图片向量化
# 获取图片特征¶defimg2feat(pic_file):
feat =[]withopen(pic_file,'r', encoding='utf-8')as f:
lines = f.readlines()
feat =[float(f)for f in lines[0].split()]return feat
ids =[]
data =[]
img_folder ='VOC2012'#'VOC2012_small/'
img_path = os.path.join(img_folder,'img.txt')withopen(img_path,'r',encoding='utf-8')as f:for line in f.readlines():
img_name = line.strip()
img_id = img_name.split('.')[0]
pic_txt_file = os.path.join( img_folder,"{}.txt".format(img_name))ifnot os.path.exists(pic_txt_file):continue
feat = img2feat(pic_txt_file)
ids.append(int(img_id))
data.append(np.array(feat))# 构建数据<id,data>
ids = np.array(ids)
data = np.array(data).astype('float32')
d =512# feature 特征长度(模型的结果) print(" 特征向量记录数: ",data.shape)print(" 特征向量ID的记录数:",ids.shape)
特征向量记录数: (17125,512)
特征向量ID的记录数: (17125,)



























 1012
1012

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









