






第一章
数据库
1 创建CREATE DATABASE
CREATE DATABASE db_mr;
CREATE SCHEMA db_admin1;
2 创建指定字符集的数据库
CHARACTER SET = utf8;
COLLATE utf8_general_ci;
DROP DATABASE IF EXISTS db_mr;
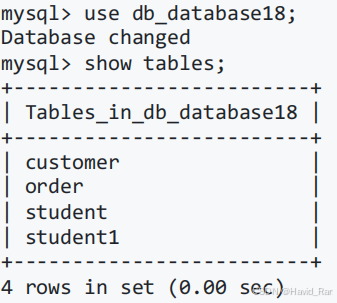
SHOW DATABASES LIKE 'db_%';3 SHOW命令查看MySQL服务器中的所有数据库信息
SHOW DATABASES|SCHEMAS
[LIKE '模式' WHERE 条件];
SHOW DATABASES like 'db_%'
SHOW DATABASES like 'db_'
4 选择数据库
use 库名
5 修改数据库
可以修改被创建数据库的相关参数
ALTER DATABASE或者ALTER SCHEMA语句
ALTER DATABASE | SCHEMA 数据库名
DEFAULT CHARACTER SET = 字符集
DEFAULT COLLATER = 较对规则名称
6 删除数据库
DROP DATABASE|SCHEMA IF EXISTS 数据库名;


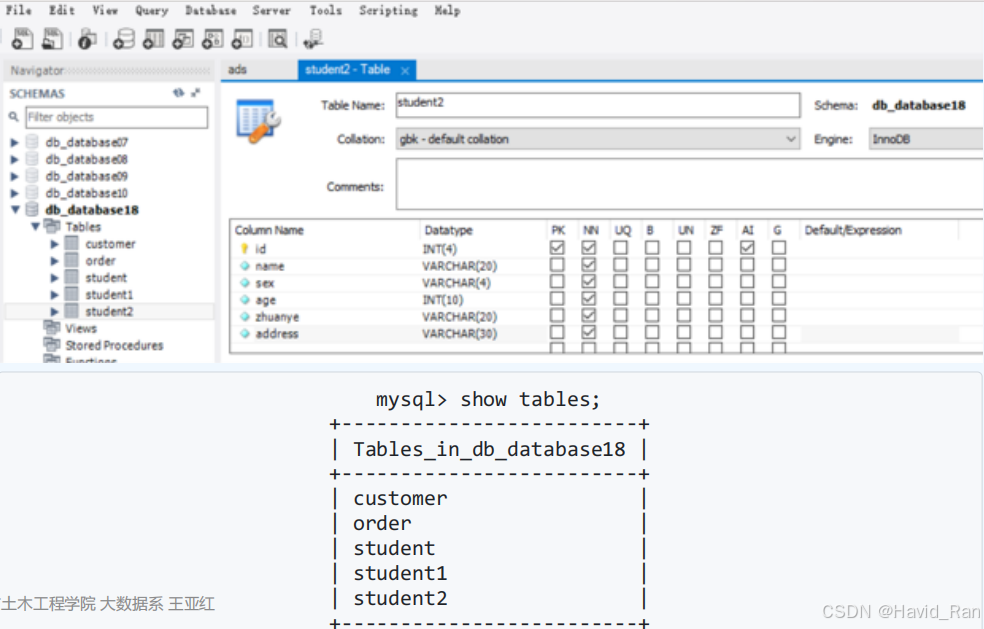
创建数据表
CREATE TEMPORARY TABLE IF NOT EXISTS 数据表名
[(create_definition,…)][table_options] [select_statement]
CREATE TABLE 数据表名(列名1 属性,列名2 属性…);数据表
任务:
1 查看表结构 SHOW COLUMNS
SHOW [FULL] COLUMNS FROM 数据表名 [FROM 数据库名];
或
SHOW [FULL] COLUMNS FROM 数据表名.数据库名;
DESCRIBE 数据表名;DESCRIBE 数据表名 列名;2 修改表结构
ALTER [IGNORE] TABLE 数据表名 alter_spec[,alter_spec]...| table_options
IGNORE可选项,如果出现重复关键行,则只执行一行,其他重复的行被删除。
alter_spec子句:用于定义要修改的内容。
ADD [COLUMN] create_definition [FIRST | AFTER column_name ]MODIFY [COLUMN] create_definition任务1:
CHANGE [COLUMN] old_col_name create_definition任务2:
DROP [COLUMN] col_name任务3:
RENAME [AS] new_tbl_name任务4:
3 重命名表
RENAME TABLE 数据表名1 To 数据表名2
4 复制表
CREATE TABLE [IF NOT EXISTS] 数据表名
{LIKE 源数据表名 | (LIKE 源数据表名)}

CREATE TABLE news3 AS SELECT * FROM news;5 删除表
DROP TABLE语句的基本语法格式如下:
DROP TABLE [IF EXISTS] 数据表名;
数据表小结
MySQL存储引擎
查询MySQL中支持的存储引擎
SHOW ENGINES;SHOW VARIABLES LIKE 'storage_engine%';小知识理解:主键、外键
MySQL数据类型
1 数字类型


2 字符串类型


3 日期和时间数据类型

第二章
基本查询语句 SELECT
1 SELECT语句的基本语法
select selection_list from 数据表名 where primary_constraint group by grouping_columns
order by sorting_cloumns //如何对结果进行排序
having secondary_constraint //查询时满足的第二条件
limit count //限定输出的查询结果

2 查询表中的一列或多列

3 从一个表或多个表中获取数据

select 表名+列名 ......
单表查询
2.1 查询所有字段
SELECT * FROM 表名2.2 查询指定字段
SELECT 字段名 FROM 表名;
2.3 查询指定数据 WHERE

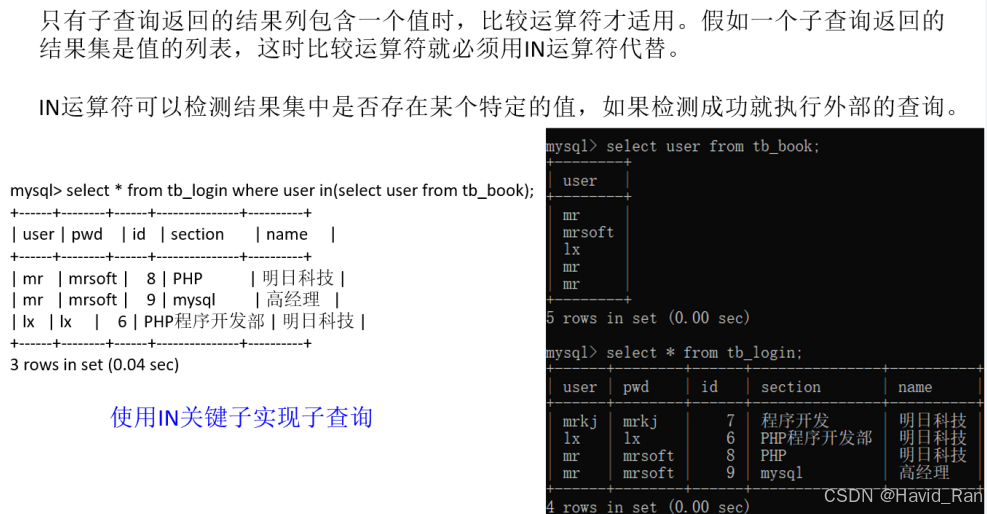
2.4 带IN关键字的查询
SELECT * FROM 表名 WHERE 条件 [NOT] IN(元素1,元素2,…,元素n);
2.5 带BETWEEN AND的范围查询
SELECT * FROM 表名 WHERE 条件 [NOT] BETWEEN 取值1 AND 取值2
2.6 带LIKE的字符匹配查询

一、%
表示任意0个或多个字符,可匹配任意类型和长度的字符。有些情况下是中文,需用两个百分号(%%)表示
例 :
- 将 u_name 为“张三”、“张猫三”、“三脚猫”、“唐三藏”等有“三”的记录全找出来
SELECT * FROM [user] WHERE u_name LIKE ‘%三%’ - 如果须要找出 u_name 中既有“三”又有“猫”的记录,请运用 and 条件
SELECT * FROM [user] WHERE u_name LIKE ‘%三%’ AND u_name LIKE ‘%猫%’ - 虽然能搜索出“三脚猫”,但不能搜索出符合条件的“张猫三”
SELECT * FROM [user] WHERE u_name LIKE ‘%三%猫%’二、 _
表示任意单个字符。匹配单个任意字符,它常用来限定表达式的字符长度语句
例
- 只找出“唐三藏”这样 u_name 为三个字且中间一个字是“三”的;
SELECT * FROM [user] WHERE u_name LIKE ‘三’ - 只找出“三脚猫”这样 name 为三个字且第一个字是“三”
SELECT * FROM [user] WHERE u_name LIKE ‘三__’;
三、[ ]
表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个
例 :
- 找出“张三”、“李三”、“王三”(而非“张李王三”);
SELECT * FROM [user] WHERE u_name LIKE ‘[张李王]三’ -
SELECT * FROM [user] WHERE u_name LIKE ‘老[1-9]’四、[^]
表示不在括号所列之内的单个字符。其取值和 [ ] 相同,但它要求所匹配对象为指定字符以外的任一个字符
例 :
- 将找出不姓“张”、“李”、“王”的“赵三”、“孙三”等;
排除“老1”到“老4”,寻找“老5”、“老6”、……SELECT * FROM [user] WHERE u_name LIKE ‘[^张李王]三’SELECT * FROM [user] WHERE u_name LIKE ‘老[^1-4]’;
2.7 用IS NULL关键字查询空值
IS [NOT] NULLmysql> SELECT books,row FROM tb_book WHERE row IS NULL;
+----------------------+------+
| books | row |
+----------------------+------+
| Java范例完全自学手册 | NULL |
| Android从入门到精通 | NULL |
+----------------------+------+
2 rows in set (0.00 sec)2.8 带关键字AND的多条件查询
select * from 数据表名 where 条件1 and 条件2 […AND 条件表达式n];
2.9 带OR的多条件查询
select * from 数据表名 where 条件1 OR 条件2 […OR 条件表达式n];
2.10 用DISTINCT关键字去除结果中的重复行
select distinct 字段名 from 表名;
2.11 用ORDER BY关键字对查询结果排序
ORDER BY 字段名 [ASC|DESC];
2.12 用GROUP BY关键字分组查询

GROUP_CONCAT()函数
group_concat( [DISTINCT] 要连接的字段 [Order BY 排序字段 ASC/DESC] [Separator ‘分
隔符’] )GROUP BY 与 GROUP_CONCAT()函数一起使用


mysql> select * from tb_book;
+----+----------------------+----------+--------+------+--------+
| id | books | talk | user | row | sort |
+----+----------------------+----------+--------+------+--------+
| 1 | PHP开发典型模块大全 | Java | mr | 12 | 模块类 |
| 2 | Java项目开发全程实录 | Java | mrsoft | 95 | 项目类 |
| 3 | Java Web从入门到精通 | Java Web | lx | 1 | 基础类 |
| 4 | Java范例完全自学手册 | Java | mr | NULL | 范例类 |
| 27 | Android从入门到精通 | Android | mr | NULL | 基础类 |
+----+----------------------+----------+--------+------+--------+
5 rows in set (0.00 sec)
mysql> select id, books,talk, user from tb_book group by user,talk;
+----+----------------------+----------+--------+
| id | books | talk | user |
+----+----------------------+----------+--------+
| 3 | Java Web从入门到精通 | Java Web | lx |
| 27 | Android从入门到精通 | Android | mr |
| 1 | PHP开发典型模块大全 | Java | mr |
| 2 | Java项目开发全程实录 | Java | mrsoft |
+----+----------------------+----------+--------+
4 rows in set (0.04 sec)2.13 用LIMIT限制查询结果的数量


3. 聚合函数查询
3.1 COUNT()函数

3.2 SUM()函数

3.3 AVG()函数
mysql> select avg(row) from tb_book;
+----------+
| avg(row) |
+----------+
| 36.0000 |
+----------+
1 row in set (0.00 sec)3.4 MAX()函数
mysql> select max(row) from tb_book;
+----------+
| max(row) |
+----------+
| 95 |
+----------+
1 row in set (0.01 sec)3.5 MIN()函数
mysql> select min(row) from tb_book;
+----------+
| min(row) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)4.高级查询
4.1 连接查询
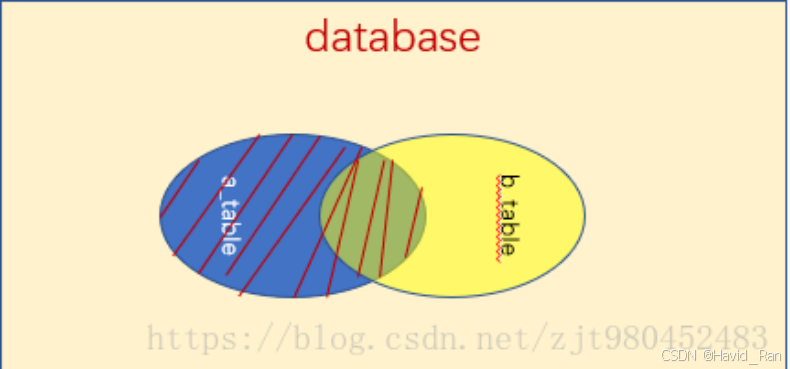
4.1.1内连接查询

select A表列名1,B表列名2 from 表1,表2 where A表.列名=B表.列名4.1.2外连接查询


SELECT columns
FROM left_table
LEFT JOIN right_table ON left_table.common_column = right_table.common_column;
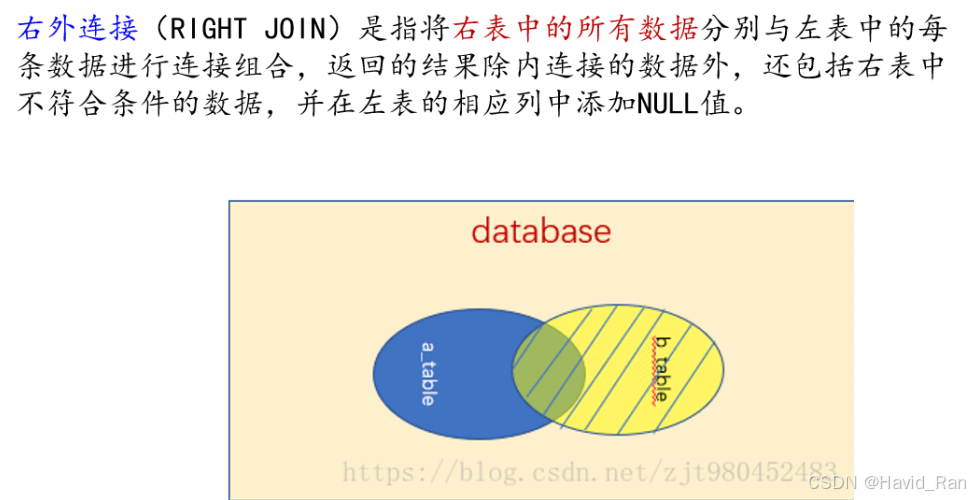
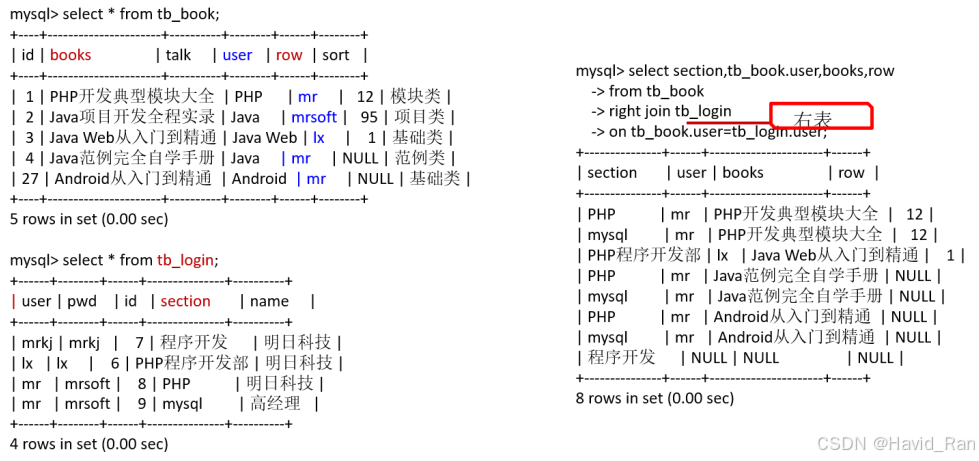
SELECT columns
FROM left_table
RIGHT JOIN right_table ON left_table.common_column = right_table.common_column;
4.1.3复合条件连接查询

SELECT columns
FROM table1
JOIN table2 ON (condition1 AND condition2)

4.2子查询
SELECT employee_name
FROM employees
WHERE department_id IN (SELECT department_id FROM departments WHERE location_id = 1000);

SELECT product_name, price
FROM products
WHERE price > (SELECT AVG(price) FROM products);

SELECT department_name
FROM departments d
WHERE EXISTS (SELECT * FROM employees e WHERE e.department_id = d.department_id);

SELECT employee_name, salary
FROM employees
WHERE salary > ANY (SELECT salary FROM employees WHERE department_id = 10);

SELECT employee_name, salary
FROM employees
WHERE salary > ALL (SELECT salary FROM employees WHERE department_id = 20);
4.3合并查询结果
UNION 和 UNION ALL 是 SQL 中用来合并多个查询结果的操作符,但它们之间有一些关键区别:
-
去重:
UNION会自动去除重复的记录,只返回唯一的结果集。UNION ALL则会返回所有记录,包括重复的记录。
-
性能:
- 因为
UNION需要检查并去除重复记录,它的性能通常比UNION ALL要差,尤其是在处理大型数据集时。 UNION ALL不进行去重检查,因此执行速度较快。
- 因为
-
使用场景:
- 如果你需要确保结果中没有重复的记录,应该使用
UNION。 - 如果你需要保留所有记录,包括重复的,或者在你确信结果集中不会有重复时,可以使用
UNION ALL。
- 如果你需要确保结果中没有重复的记录,应该使用



4.4定义表和字段的别名


1. 给列起别名
SELECT column_name AS alias_name FROM table_name;
示例:
SELECT first_name AS "First Name", last_name AS "Last Name" FROM employees;
2. 给表起别名
SELECT a.column_name FROM table_name AS a;
示例:
SELECT e.first_name, e.last_name FROM employees AS e;
3. 在聚合函数中使用
SELECT COUNT(*) AS total_employees FROM employees;
4. 在JOIN语句中使用
SELECT a.column_name, b.column_name FROM table_a AS a JOIN table_b AS b ON a.id = b.a_id;

4.5使用正则表达式查询
MySQL 使用 REGEXP 或 RLIKE 来进行正则表达式匹配。
示例:查找包含数字的名字
SELECT name FROM employees WHERE name REGEXP '[0-9]';
Oracle 提供了 REGEXP_LIKE 函数用于正则表达式的匹配。
示例:查找包含特定模式的电子邮件地址
SELECT email FROM users WHERE REGEXP_LIKE(email, '^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$');




5 函数
1. 常用函数
MySQL函数
数学函数
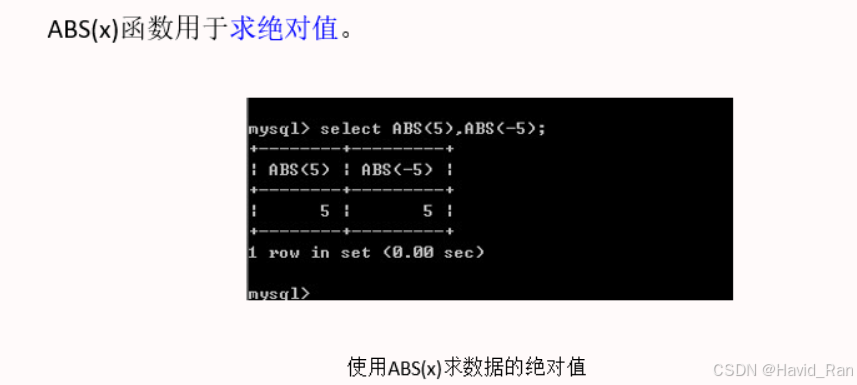
FLOOR(X)函数
RAND()函数

PI()函数
TRUNCATE(X,Y)函数
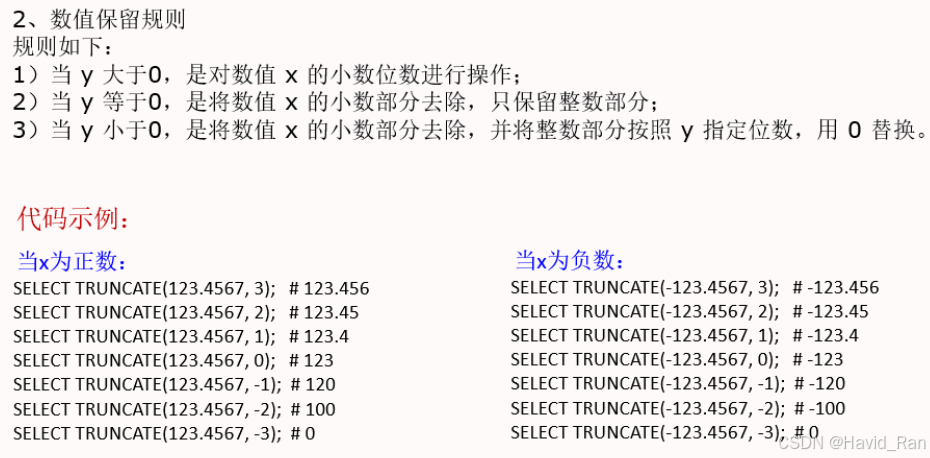
练习
SELECT TRUNCATE(1.31,1), TRUNCATE(1.99,1), TRUNCATE(1.99,0), TRUNCATE(19.99,-1);
ROUND{(X)和(X,Y)}函数
练习
【1】使用ROUND(x)函数对操作数进行四舍五入操作,输入语句如下:
SELECT ROUND(-1.14),ROUND(-1.67), ROUND(1.14),ROUND(1.66);
【2】使用ROUND(x,y)函数对操作数进行四舍五入操作,结果保留小数点后面指定y位,
输入语句如下:
SELECT ROUND(1.38, 1), ROUND(1.38, 0), ROUND(232.38, -1), round(232.38,-2);
SQRT(X)函数

字符串函数
字符串函数是MySQL中最常用的一类函数,主要用于处理表中的字符串。
INSERT(s1,x,len,s2)函数


UPPER(s),UCASE(s)函数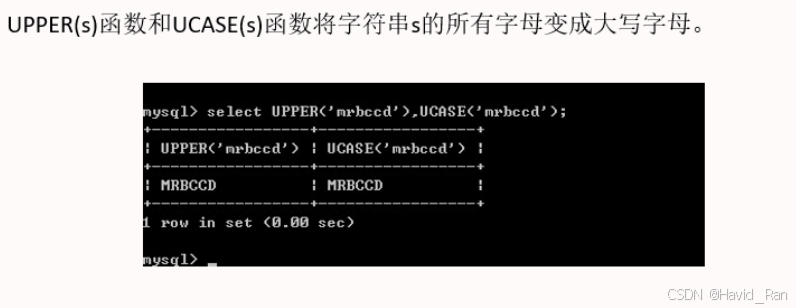
LOWER(s),LCASE(s)函数
LEFT(s,n)函数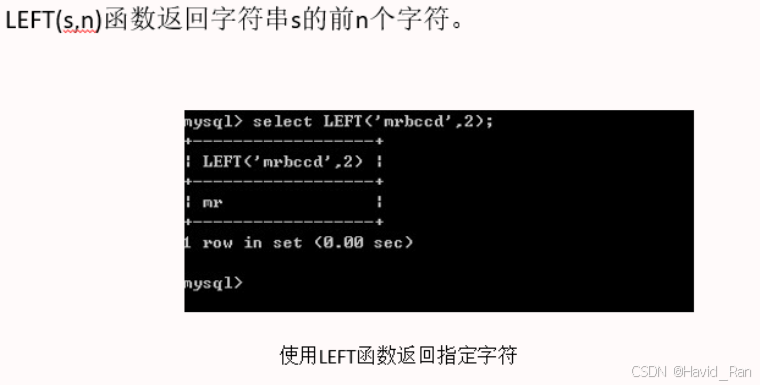
RIGHT(s,n)函数
CONCAT()函数
CONCAT_WS()函数

RTRIM(s)函数
RTRIM(s)函数将去掉字符串s结尾处(右边)的空格。

SUBSTRING(s,n,len)函数
SUBSTRING(s,n,len)函数从字符串s的第n个位置开始获取长度为len的字符串。
REVERSE(s)函数
REVERSE(s)函数将字符串s的顺序反过来。 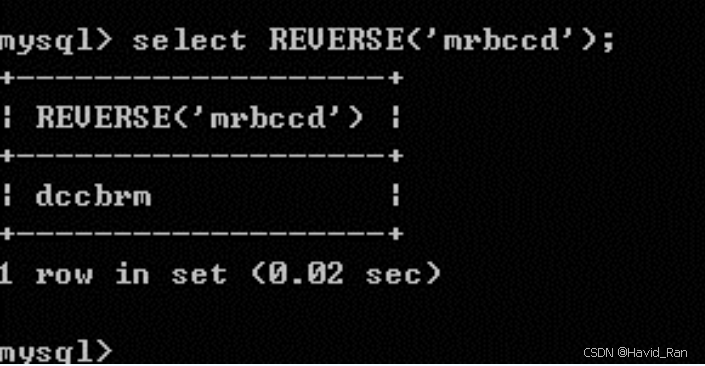
FIELD(s,s1,s2,…)
FIELD(s,s1,s2,…)函数返回第一个与字符串s匹配的字符串的位置。 
LOCATE(s1,s)、POSITION(s1 IN s)和INSTR(s,s1)函数
在MySQL中,可以通过LOCATE(s1,s)、POSITION(s1 IN s)和INSTR(s,s1)函数获取子字符串
相匹配的开始位置。这3个函数的语法格式如下。

日期和时间函数
日期和时间函数是MySQL中另一最常用的函数, 主要用于对表中日期和时间数据的处理。
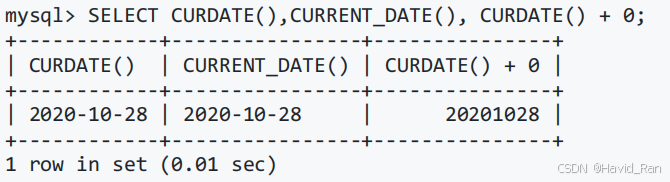
CURDATE()和CURRENT_DATE()函数
获取当前日期。
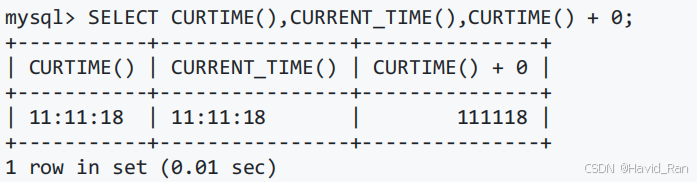
CURTME()和CURRENT_TIME()
获取当前时间。
NOW()
NOW()函数获取当前日期和时间。还有CURRENT_TIMESTAMP()函数、LOCALTIME()函
数、SYSDATE()函数和LOCALTIMESTAMP()函数也同样可以获取当前日期和时间。
DATEDIFF(d1,d2)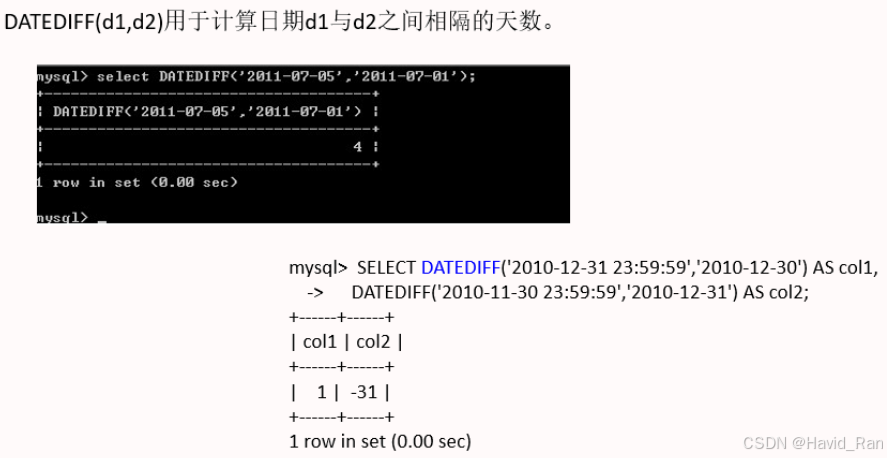
DATE_FORMAT()
DATE_FORMAT() 函数用于以不同的格式显示日期/时间数据。
DATE_FORMAT(date,format)
date 参数是合法的日期。format 规定日期/时间的输出格式。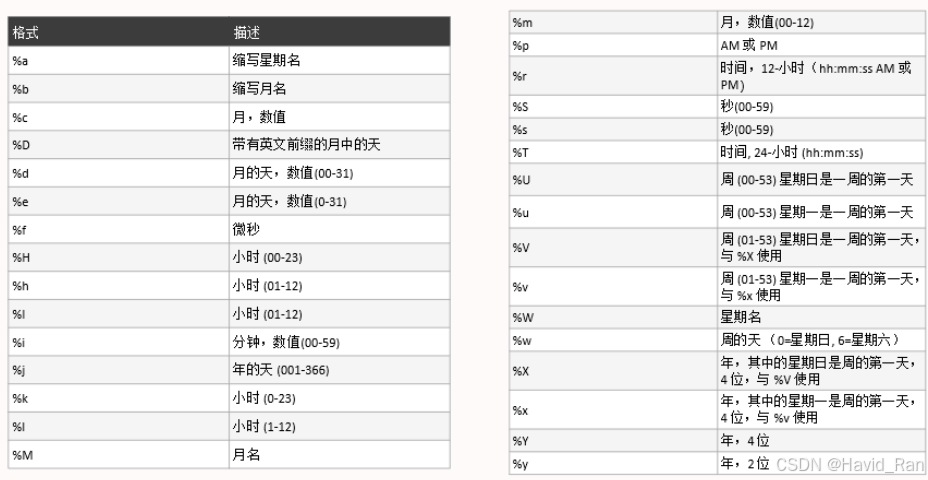

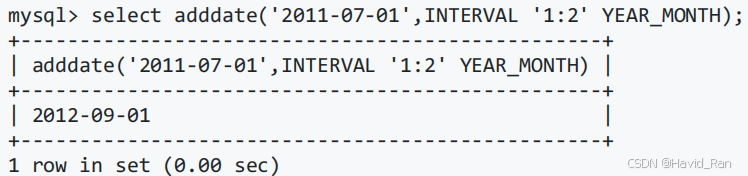
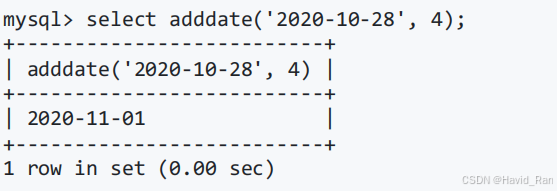
ADDDATE(d,n)
ADDDATE(d,INTERVAL expr type)

SUBDATE(d,n)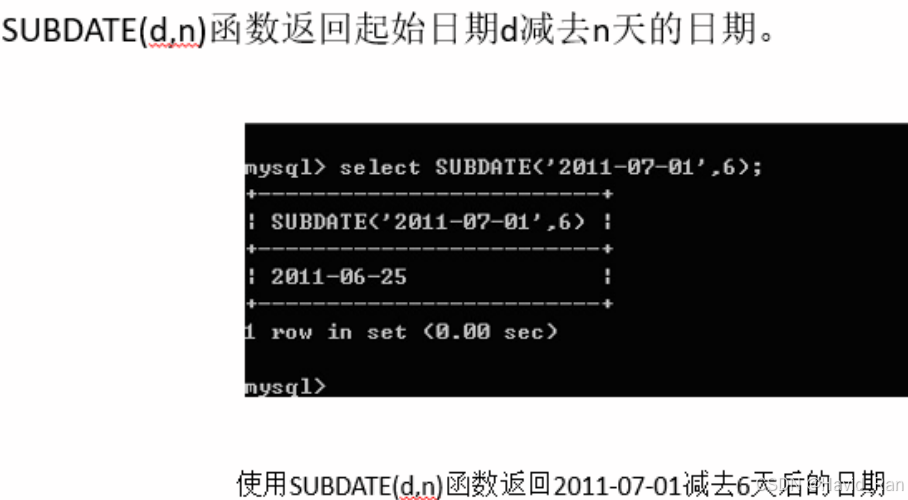
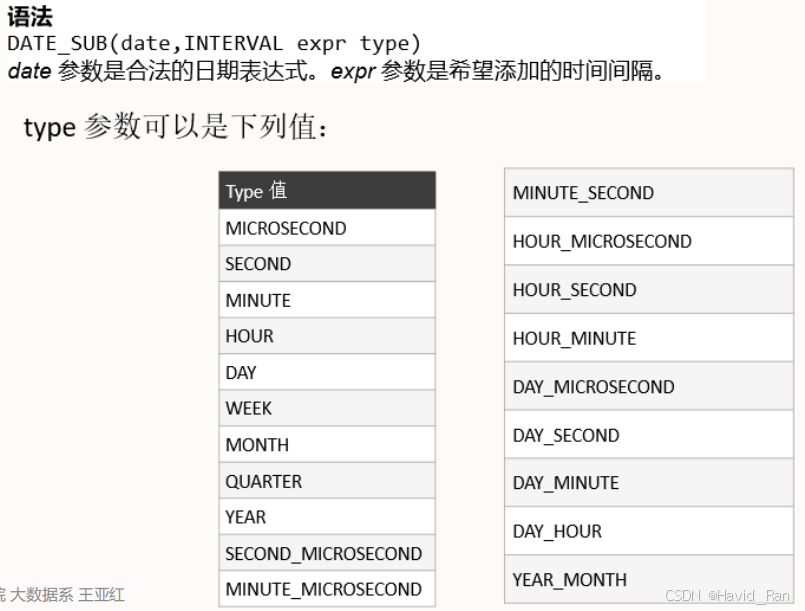

条件判断函数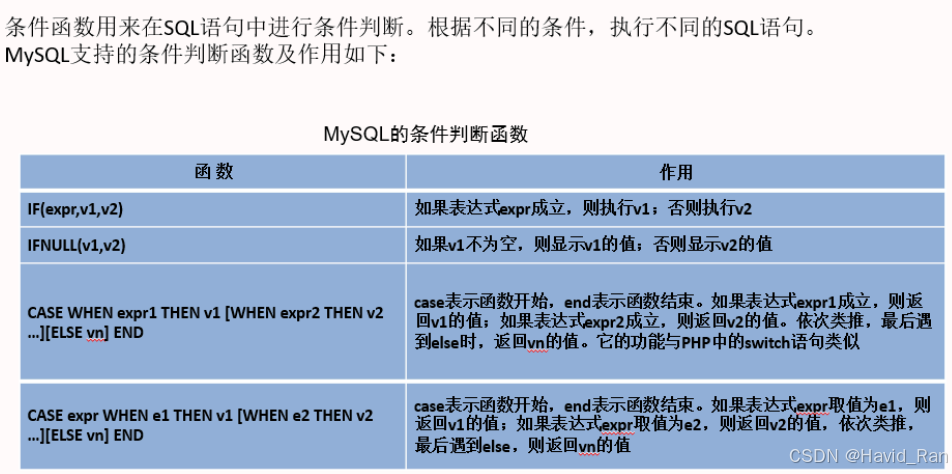
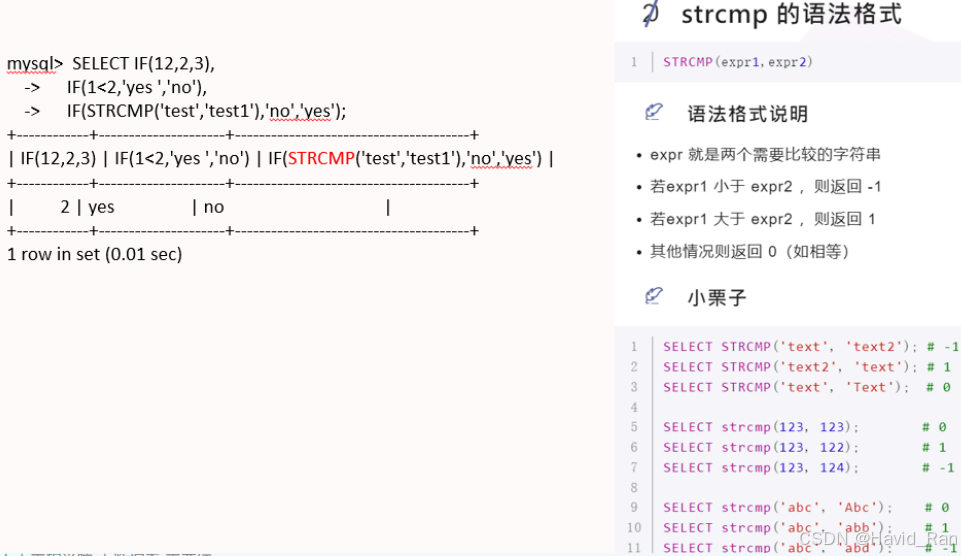

系统信息函数
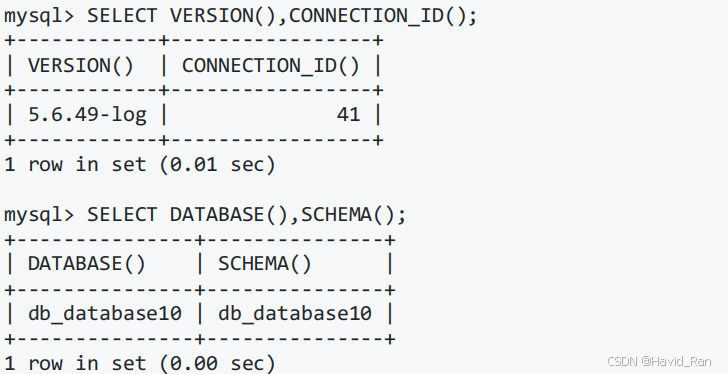
获取MySQL版本号、连接数和数据库名的函数
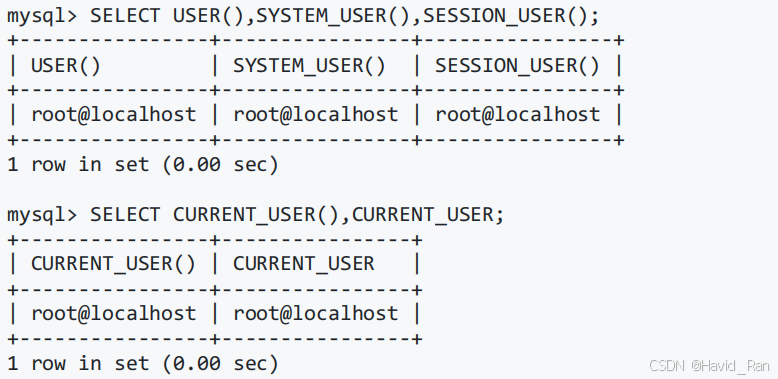
获取用户名的函数
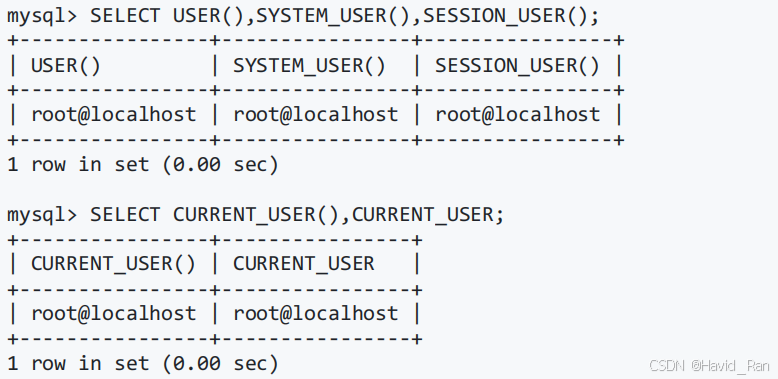
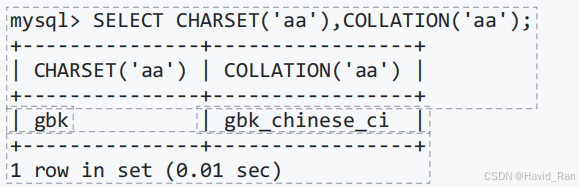
获取字符串的字符集和排序方式的函数

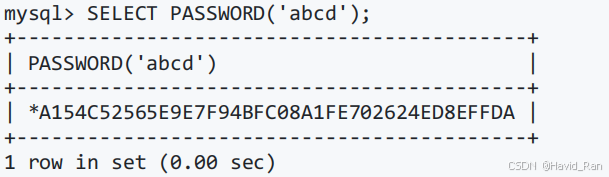
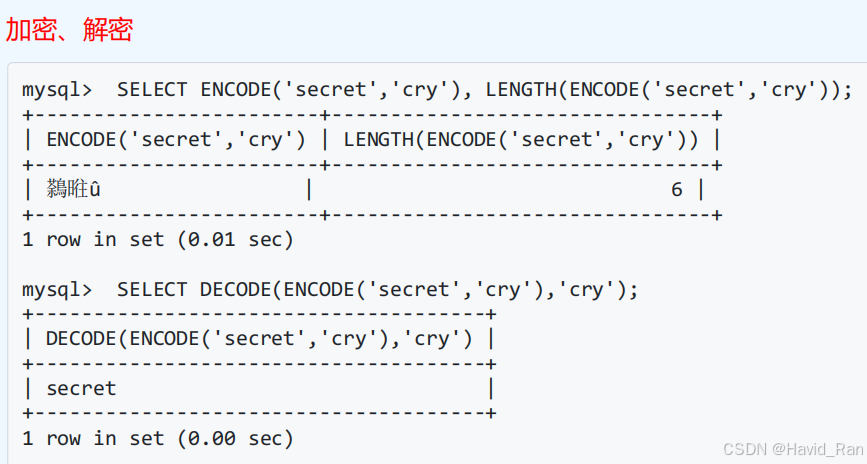
加密函数
加密函数PASSWORD(str)
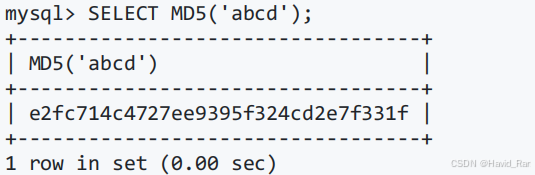
加密函数MD5(str)
其他函数
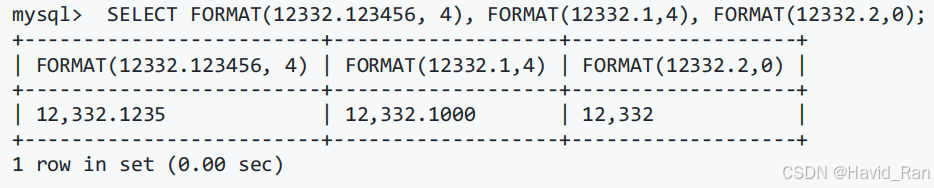
格式化函数FORMAT(x,n)
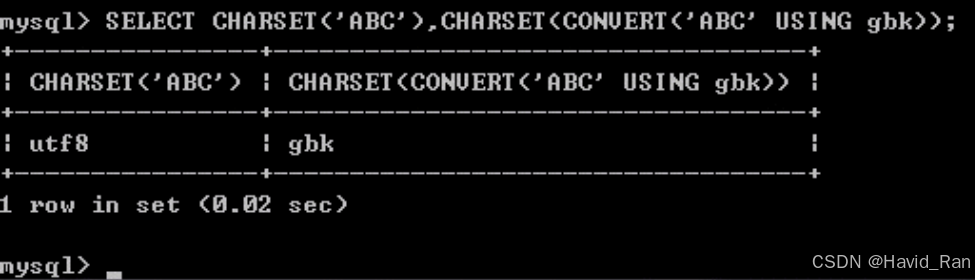
改变字符集的函数
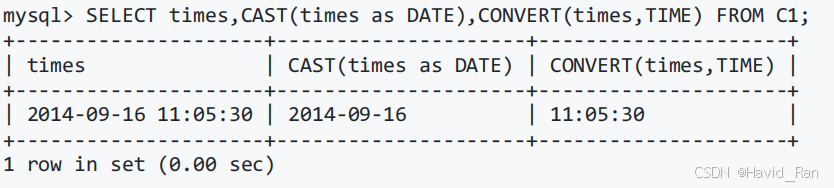
改变字段数据类型的函数
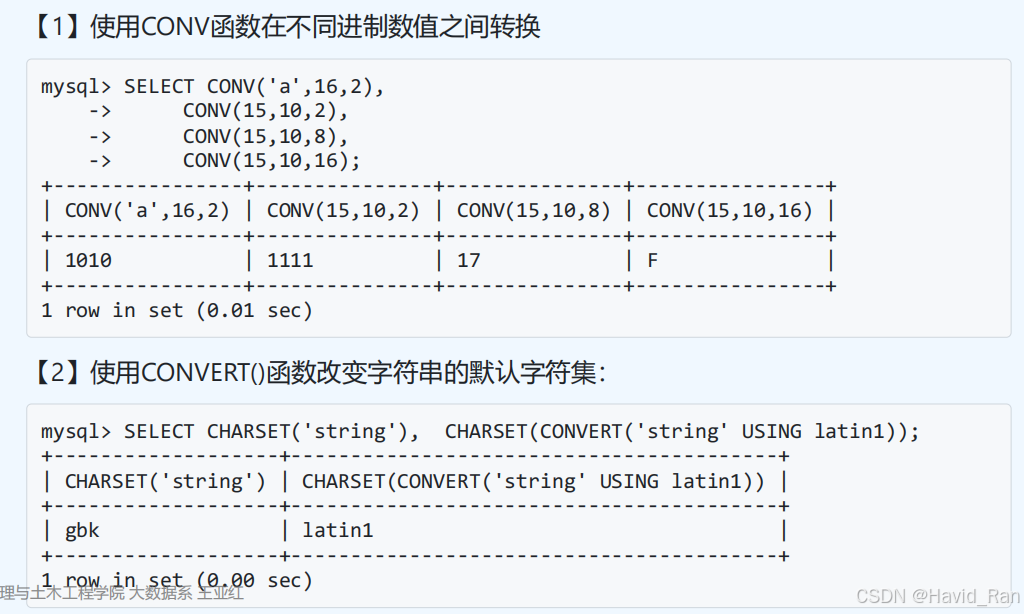
6 数据备份
使用mysqldump命令备份

直接复制整个数据库目录
使用mysqlhotcopy工具快速备份

7数据恢复
使用mysql命令还原
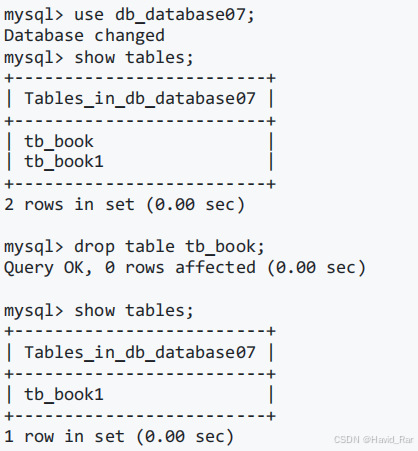

直接复制到数据库目录
8数据库迁移
相同版本的MySQL数据库之间的迁移
不同数据库之间的迁移
9表的导出和导入
用SELECT ...INTO OUTFILE导出文本文件
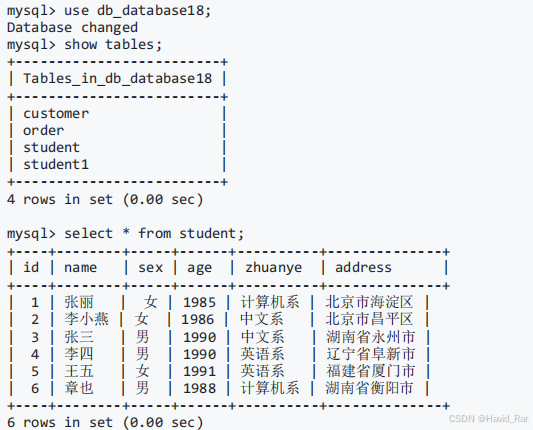

用mysqldump命令导出文本文件
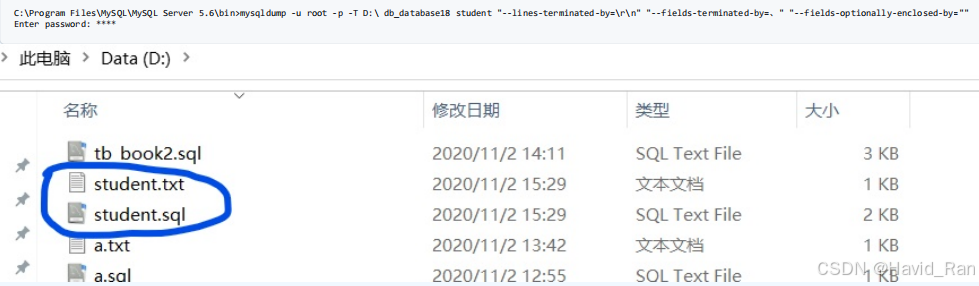

用mysql命令导出文本文件

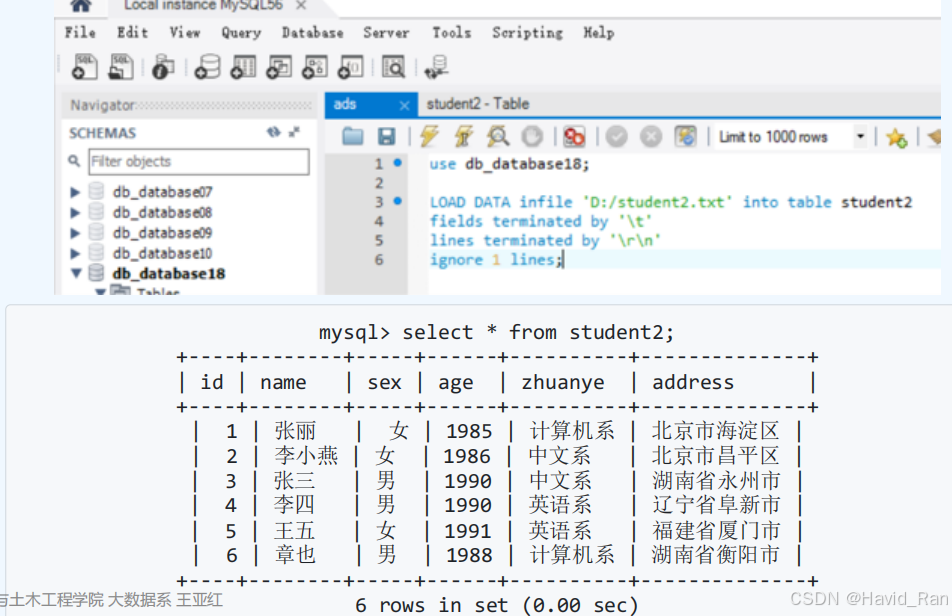
用LOAD DATA INFILE命令将文本文件导入到数据表
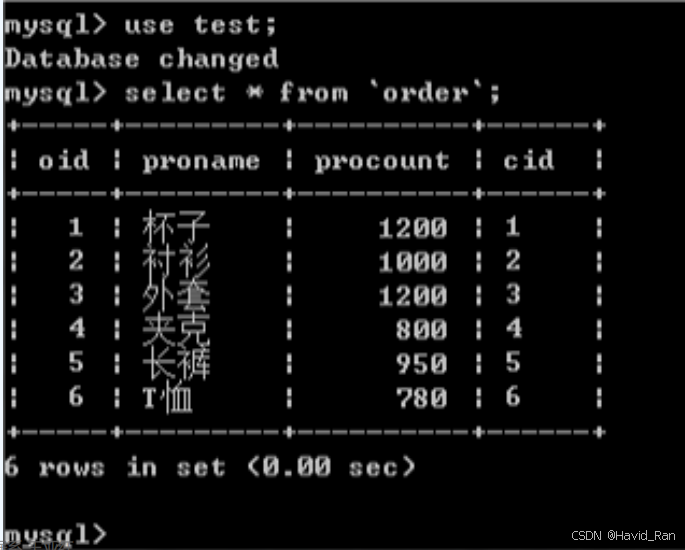
用mysqlimport命令导入文本文件

10 Python API
1安装
2 查询
前面的代码实现了数据库的连接,但该代码需要优化。
import pymysql
pymysql.install_as_MySQLdb()
import MySQLdb
class MysqlSearch(object):
def __init__(self):
self.get_conn()
def get_conn(self):
try:
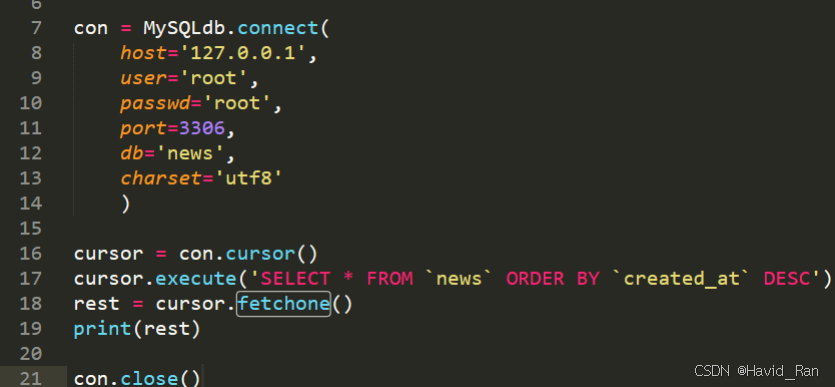
self.conn = MySQLdb.connect(
host='127.0.0.1',
user='root',
passwd='root',
db='news',
port=3306,
charset='utf8'
)
except MySQLdb.Error as e:
print('Error: %s' % e)
def close_conn(self):
try:
if self.conn:
# 关闭链接
self.conn.close()
except MySQLdb.Error as e:
print('Error: %s' % e)
def get_one(self):
# 准备SQL
sql = 'SELECT * FROM `news` WHERE `types` = %s ORDER BY `created_at` DESC;'
# 找到cursor(中间人)
cursor = self.conn.cursor()
# 执行SQL
cursor.execute(sql, ('百家', ))#元组
# 拿到结果
rest = cursor.fetchone()
# 处理数据
# 暂且执行
print(rest)
# 关闭cursor/连接
cursor.close()
self.close_conn()
#return rest
def get_more(self):
# 准备SQL
sql = 'SELECT * FROM `news` WHERE `types` = %s ORDER BY `created_at` DESC;'
# 找到cursor
cursor = self.conn.cursor()
# 执行SQL
cursor.execute(sql, ('百家', ))
# print(dir(cursor))
# 拿到结果
rest = [dict(zip([k[0] for k in cursor.description], row))
for row in cursor.fetchall()]
# 处理数据
# 关闭cursor/链接
cursor.close()
self.close_conn()
return rest
def main():
obj = MysqlSearch()
#obj.get_one()
rest = obj.get_one()
print(rest['title'])
# rest = obj.get_more()
# for item in rest:
# print(item)
# print('------')
if __name__ == '__main__':
main()
import pymysql
pymysql.install_as_MySQLdb()
import MySQLdb
class MysqlSearch(object):
def __init__(self):
self.get_conn()
def get_conn(self):
try:
self.conn = MySQLdb.connect(
host='127.0.0.1',
user='root',
passwd='root',
db='news',
port=3306,
charset='utf8'
)
except MySQLdb.Error as e:
print('Error: %s' % e)
def close_conn(self):
try:
if self.conn:
# 关闭链接
self.conn.close()
except MySQLdb.Error as e:
print('Error: %s' % e)
def get_one(self):
# 准备SQL
sql = 'SELECT * FROM `news` WHERE `types` = %s ORDER BY `created_at` DESC;'
# 找到cursor(中间人)
cursor = self.conn.cursor()
# 执行SQL
cursor.execute(sql, ('百家', ))#元组
print(cursor.rowcount)
print("************************************************")
print(dir(cursor))
print("************************************************")
print(cursor.description)
rest = cursor.fetchone()
# 关闭cursor/连接
cursor.close()
self.close_conn()
#return rest
def get_more(self):
# 准备SQL
sql = 'SELECT * FROM `news` WHERE `types` = %s ORDER BY `created_at` DESC;'
# 找到cursor
cursor = self.conn.cursor()
# 执行SQL
cursor.execute(sql, ('百家', ))
# print(dir(cursor))
# 拿到结果
rest = [dict(zip([k[0] for k in cursor.description], row))
for row in cursor.fetchall()]
# 处理数据
# 关闭cursor/链接
cursor.close()
self.close_conn()
return rest
def main():
obj = MysqlSearch()
obj.get_one()
# rest = obj.get_one()
# print(rest['title'])
# rest = obj.get_more()
# for item in rest:
# print(item)
# print('------')
if __name__ == '__main__':
main()3获取多条数据
import pymysql
pymysql.install_as_MySQLdb()
import MySQLdb
class MysqlSearch(object):
def __init__(self):
self.get_conn()
def get_conn(self):
try:
self.conn = MySQLdb.connect(
host='127.0.0.1',
user='root',
passwd='root',
db='news',
port=3306,
charset='utf8'
)
except MySQLdb.Error as e:
print('Error: %s' % e)
def close_conn(self):
try:
if self.conn:
# 关闭链接
self.conn.close()
except MySQLdb.Error as e:
print('Error: %s' % e)
def get_one(self):
# 准备SQL
sql = 'SELECT * FROM `news` WHERE `types` = %s ORDER BY `created_at` DESC;'
# 找到cursor(中间人)
cursor = self.conn.cursor()
# 执行SQL
cursor.execute(sql, ('百家', ))#元组
# 拿到结果
rest = dict(zip([k[0] for k in cursor.description], cursor.fetchone()))
# 处理数据
# 关闭cursor/链接
cursor.close()
self.close_conn()
return rest
def get_more(self):
# 准备SQL
sql = 'SELECT * FROM `news` WHERE `types` = %s ORDER BY `created_at` DESC;'
# 找到cursor
cursor = self.conn.cursor()
# 执行SQL
cursor.execute(sql, ('百家', ))
# 拿到结果
rest = [dict(zip([k[0] for k in cursor.description], row))
for row in cursor.fetchall()]
# 处理数据
# 关闭cursor/链接
cursor.close()
self.close_conn()
return rest
def main():
obj = MysqlSearch()
#obj.get_one()
# rest = obj.get_one()
# print(rest['title'])
rest = obj.get_more()
for item in rest:
print(item)
print('------')
if __name__ == '__main__':
main()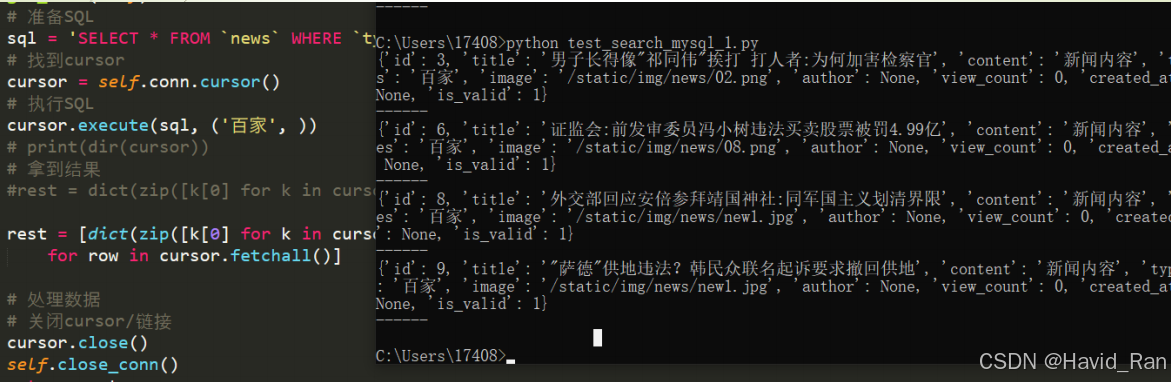
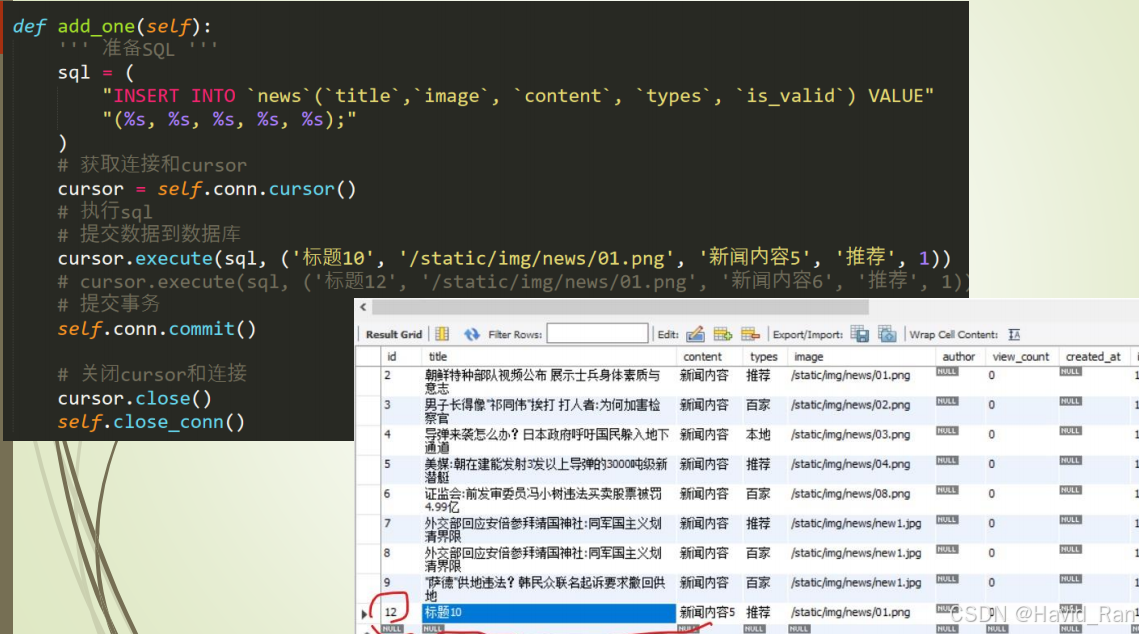
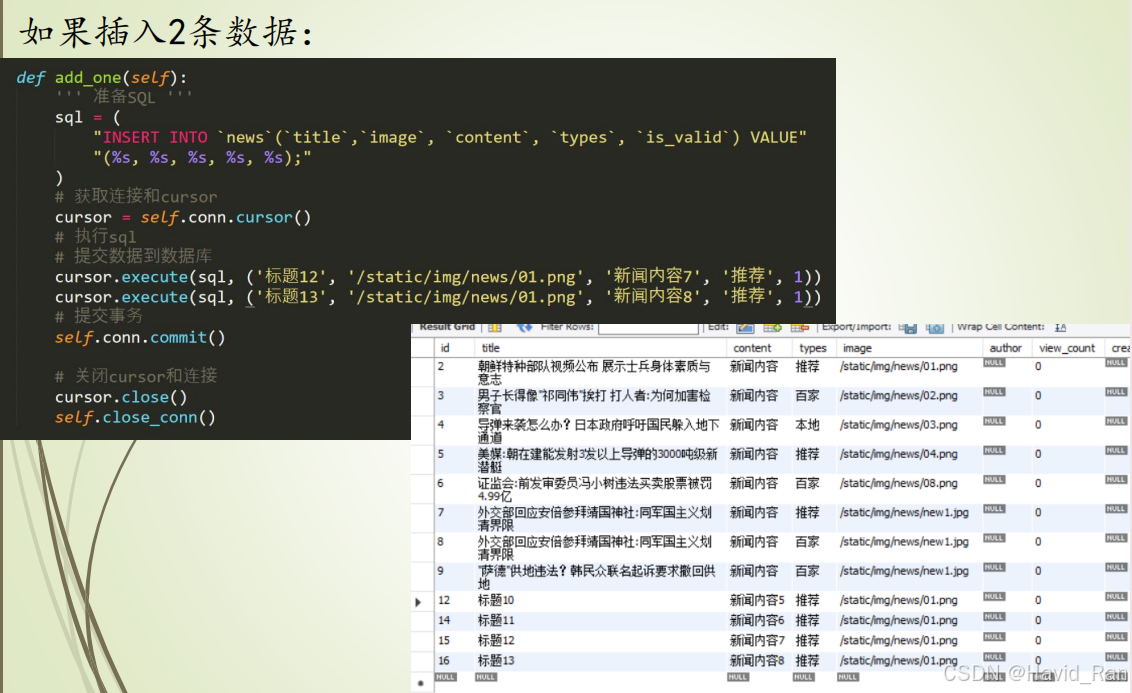
4 新增数据到数据库
11 ORM SQLAlchemy
常见数据类型
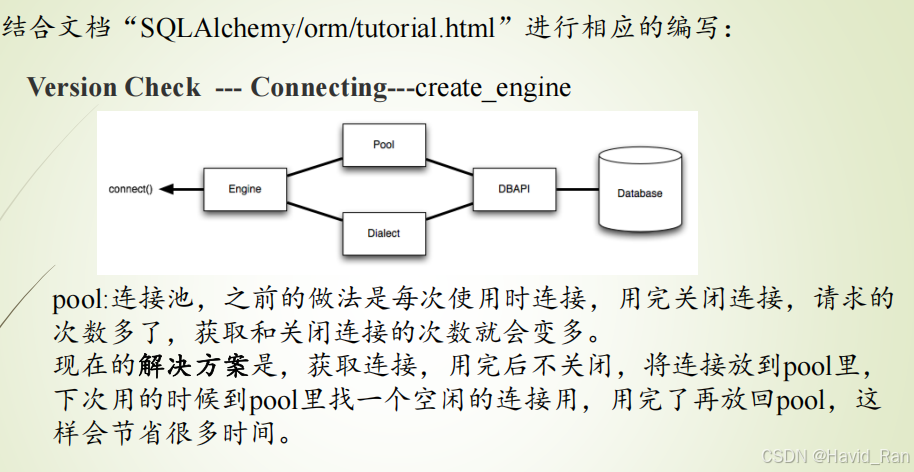
1
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, DateTime, Boolean
engine = create_engine("mysql://root:root@localhost:3306/news_test")#此处的数据库为了便于区分,新建一个news_test
Base = declarative_base()
class News(Base):#继承基类
''' 新闻类型 '''
__tablename__ = 'news'
id = Column(Integer, primary_key=True)
title = Column(String(200), nullable=False)
content = Column(String(2000), nullable=False)
types = Column(String(10), nullable=False)
image = Column(String(300))
author = Column(String(20))
view_count = Column(Integer)
created_at = Column(DateTime)
is_valid = Column(Boolean)2
#!/usr/bin/python
#coding=utf-8
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
from sqlalchemy import Column, Integer, String, DateTime, Boolean
engine = create_engine("mysql://root:@127.0.0.1:3308/news?charset=utf8")
Session = sessionmaker(bind=engine)
Base = declarative_base()
class News(Base):
''' 新闻类型 '''
__tablename__ = 'news'
id = Column(Integer, primary_key=True)
title = Column(String(200), nullable=False)
content = Column(String(2000), nullable=False)
types = Column(String(10), nullable=False)
image = Column(String(300))
author = Column(String(20))
view_count = Column(Integer)
created_at = Column(DateTime)
is_valid = Column(Boolean)
class MysqlOrmTest(object):
def __init__(self):
self.session = Session()
def add_one(self):
''' 添加数据 '''
new_obj = News(
title='ORM标题',
content='content',
types="百家"
)
self.session.add(new_obj)
self.session.commit()
return new_obj
def get_one(self):
''' 获取一条数据 '''
return self.session.query(News).get(1)
def get_more(self):
''' 获取多条数据 '''
return self.session.query(News).filter_by(is_valid=1)
def update_data(self):
''' 修改数据 '''
obj = self.session.query(News).get(38)
obj.is_valid = 0
self.session.add(obj)
self.session.commit()
return obj
def delete_data(self):
''' 删除数据 '''
# 获取要删除的数据
data = self.session.query(News).get(39)
self.session.delete(data)
self.session.commit()
def main():
obj = MysqlOrmTest()
# rest = obj.add_one()
# print(dir(rest))
# print(obj.get_one().title)
# print(obj.get_more().count())
# for row in obj.get_more():
# print(row.title)
# print(obj.update_data())
obj.delete_data()
if __name__ == '__main__':
main()3
import pymysql
pymysql.install_as_MySQLdb()
import MySQLdb
class MysqlSearch(object):
def __init__(self):
self.get_conn()
def get_conn(self):
try:
self.conn = MySQLdb.connect(
host='127.0.0.1',
user='root',
passwd='root',
db='news',
port=3306,
charset='utf8'
)
except MySQLdb.Error as e:
print('Error: %s' % e)
def close_conn(self):
try:
if self.conn:
# 关闭链接
self.conn.close()
except MySQLdb.Error as e:
print('Error: %s' % e)
def get_one(self):
# 准备SQL
sql = 'SELECT * FROM `news` WHERE `types` = %s ORDER BY `created_at` DESC;'
# 找到cursor(中间人)
cursor = self.conn.cursor()
# 执行SQL
cursor.execute(sql, ('百家', ))#元祖
# 拿到结果
rest = dict(zip([k[0] for k in cursor.description], cursor.fetchone()))
# 处理数据
# 关闭cursor/链接
cursor.close()
self.close_conn()
return rest
def get_more(self):
# 准备SQL
sql = 'SELECT * FROM `news` WHERE `types` = %s ORDER BY `created_at` DESC;'
# 找到cursor
cursor = self.conn.cursor()
# 执行SQL
cursor.execute(sql, ('百家', ))
# print(dir(cursor))
# 拿到结果
rest = [dict(zip([k[0] for k in cursor.description], row))
for row in cursor.fetchall()]
# 处理数据
# 关闭cursor/链接
cursor.close()
self.close_conn()
return rest
def get_more_by_page(self, page, page_size):
''' 分页查询数据 '''
offset = (page - 1) * page_size
# 准备SQL
sql = 'SELECT * FROM `news` WHERE `types` = %s ORDER BY `created_at` DESC LIMIT %s, %s;'
# 找到cursor
cursor = self.conn.cursor()
# 执行SQL
cursor.execute(sql, ('百家', offset, page_size))
# print(dir(cursor))
# 拿到结果
rest = [dict(zip([k[0] for k in cursor.description], row))
for row in cursor.fetchall()]
# 处理数据
# 关闭cursor/链接
cursor.close()
self.close_conn()
return rest
def main():
obj = MysqlSearch()
#obj.get_one()
# rest = obj.get_one()
# print(rest['title'])
# rest = obj.get_more()
# for item in rest:
# print(item)
# print('------')
rest = obj.get_more_by_page(1, 3)
for item in rest:
print(item)
print('------')
if __name__ == '__main__':
main()12 网易新闻实战
import pymysql
pymysql.install_as_MySQLdb()
from flask import Flask, render_template, flash, redirect, url_for, abort, request
from flask_sqlalchemy import SQLAlchemy
from datetime import datetime
import requests
import json
import re
import time
from random import choice
from requests.exceptions import RequestException
from fake_useragent import UserAgent
from sqlalchemy import text
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:1234567@localhost:3306/db_database08?charset=utf8mb4'
db = SQLAlchemy(app)
app.config["SECRET_KEY"] = 'd6f96a238e074f9dba7330d471951373'
class News(db.Model):
__tablename__ = 'news'
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(200), nullable=False)
content = db.Column(db.String(2000), nullable=False)
types = db.Column(db.String(10), nullable=False)
image = db.Column(db.String(300))
author = db.Column(db.String(20))
view_count = db.Column(db.Integer)
created_at = db.Column(db.DateTime)
is_valid = db.Column(db.Boolean)
def __repr__(self):
return '<News %r>' % self.title
def save_news_to_db():
def fetch_news_data():
url = 'https://3g.163.com/touch/reconstruct/article/list/BA10TA81wangning/0-20.html'
try:
response = requests.get(url)
response.raise_for_status()
json_data = response.text
json_data = json_data[json_data.index('artiList(') + len('artiList('):-1]
data = json.loads(json_data)
articles = data.get('BA10TA81wangning', [])
return articles
except Exception as e:
print(f"Error fetching news data: {e}")
return []
def clean_html_content(text):
""" 清理掉 <a> 标签内容,保留标签内的文本 """
text = re.sub(r'<a.*?>(.*?)</a>', r'\1', text, flags=re.DOTALL)
# 删除 <strong> 标签及其内容
text = re.sub('</strong>', '', text, flags=re.DOTALL)
text = re.sub('<strong>', '', text, flags=re.DOTALL)
# 删除 <figure> 标签及其内容
text = re.sub(r'<figure.*?>.*?</figure>', '', text, flags=re.DOTALL)
# 删除 <blockquote> 标签及其内容
text = re.sub(r'<blockquote.*?>.*?</blockquote>', '', text, flags=re.DOTALL)
return text
def extract_content(text):
clean_text = clean_html_content(text)
title_pattern = r'<title>(.*?)</title>'
title_match = re.search(title_pattern, clean_text, re.IGNORECASE)
title = title_match.group(1) if title_match else "标题未找到"
p_pattern = r'<p.*?>(.*?)</p>'
p_matches = re.findall(p_pattern, clean_text, re.IGNORECASE | re.DOTALL)
return title, p_matches
def fetch_full_content(url):
try:
headers = {'User-Agent': UserAgent().random}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
else:
print(f"Failed to fetch content from {url}")
return None
except RequestException as e:
print(f"Error fetching full content: {e}")
return None
# 获取新闻列表
news_data = fetch_news_data()
for news in news_data:
article_url = news.get("url")
full_content = ""
if article_url:
article_response = fetch_full_content(article_url)
if article_response:
# 提取标题和段落内容
title, paragraphs = extract_content(article_response)
full_content = f"标题: {title}\n" + "\n".join(paragraphs)
else:
print("无法获取文章的详细内容")
new_obj = News(
title=news.get('title'),
content=news.get('digest', 'No content available') + '\n' + full_content, # Store URL and full_content
types=news.get('type', '娱乐'),
image=news.get('imgsrc'),
author=news.get('source', 'Unknown'),
view_count=news.get('replyCount', 0),
created_at=news.get('ptime', datetime.now()),
is_valid=True
)
db.session.add(new_obj)
db.session.execute(text("ALTER TABLE news AUTO_INCREMENT = 1;"))
db.session.commit()
@app.route('/')
def index():
news_list = News.query.all()
return render_template('index.html', news_list=news_list)
@app.route('/cat/<name>/')
def cat(name):
news_list = News.query.filter(News.types == name)
return render_template('cat.html', name=name, news_list=news_list)
@app.route('/detail/<int:pk>/')
def detail(pk):
new_obj = News.query.get(pk)
return render_template('detail.html', new_obj=new_obj)
@app.route('/admin/', methods=['GET', 'POST'])
@app.route('/admin/<int:page>', methods=['GET', 'POST'])
def admin(page=1):
if request.method == 'POST' and 'refresh' in request.form:
save_news_to_db()
flash("新闻已刷新")
return redirect(url_for('admin', page=page))
page_data = News.query.filter_by(is_valid=True).paginate(page=page, per_page=5)
return render_template('admin/index.html', page_data=page_data)
@app.route('/admin/add/', methods=('GET', 'POST'))
def add():
form = NewsForm()
if form.validate_on_submit():
new_obj = News(
title=form.title.data,
content=form.content.data,
image=form.image.data,
types=form.types.data,
created_at=datetime.now(),
)
db.session.add(new_obj)
db.session.commit()
flash("新增成功")
return redirect(url_for('admin'))
return render_template("admin/add.html", form=form)
@app.route('/admin/update/<int:pk>/', methods=('GET', 'POST'))
def update(pk):
obj = News.query.get(pk)
if obj is None:
abort(404)
form = NewsForm(obj=obj)
if form.validate_on_submit():
obj.title = form.title.data
obj.content = form.content.data
obj.news_type = form.types.data
db.session.add(obj)
db.session.commit()
flash("修改成功")
return redirect(url_for('admin'))
return render_template("admin/update.html", form=form)
@app.route('/admin/delete/<int:pk>/', methods=['GET', 'POST'])
def delete(pk):
""" 异步ajax删除 逻辑删除 """
new_obj = News.query.get(pk)
if not new_obj:
return 'no'
new_obj.is_valid = False
db.session.add(new_obj)
db.session.commit()
# 重排ID顺序
db.session.execute("SET @new_id = 0;")
db.session.execute("UPDATE news SET id = (@new_id := @new_id + 1) ORDER BY id;")
db.session.commit()
return 'yes'
if __name__ == '__main__':
app.run(debug=True)
13 MongoDB基础
MongoDB简介、基本概念
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编
MongoDB基本操作
1. 新增数据(Create)
> stu = { name: 'Jhon', age: 21, sex: "male" } > db.students.insert(stu)这会将一个包含姓名、年龄和性别的文档插入到 students 集合。
你也展示了如何插入新的数据:
> db.students.insert({ name: 'Amy' })> show dbs;
admin 0.000GB---指所用空间
config 0.000GB
local 0.000GB
mongodb_mysql 0.000GB
> use students---无需创建,使用即创建
switched to db students
> db---查看当前在用数据库
students
> stu={
... name:'Jhon',
... age:21,
... sex:"male"
... }
{ "name" : "Jhon", "age" : 21, "sex" : "male" }
> db.students.insert(stu)---将stu对象加入数据库
WriteResult({ "nInserted" : 1 })
>2. 查询数据(Read)
你使用了以下命令来查看 students 集合中的所有文档:
> db.students.find()> db.students.find()
{ "_id" : ObjectId("5fc5deecb306bbfe8da27368"), "name" : "Jhon", "age" : 21, "sex" :
"male" }
> db.students.insert({name:'Amy'})
WriteResult({ "nInserted" : 1 })
> db.students.find()
{ "_id" : ObjectId("5fc5deecb306bbfe8da27368"), "name" : "Jhon", "age" : 21, "sex" :
"male" }
{ "_id" : ObjectId("5fc5e049b306bbfe8da27369"), "name" : "Amy" }
> db.students.findOne()
{
"_id" : ObjectId("5fc5deecb306bbfe8da27368"),
"name" : "Jhon",
"age" : 21,
"sex" : "male"
}find() 方法用于查询集合中的所有数据。
你也使用了 findOne() 方法,它返回集合中的第一个文档:
> db.students.findOne()3. 修改数据(Update)
修改数据时,你使用了 update() 方法来更新文档中的某些字段:
> db.students.update({ name: 'Jhon' }, { name: 'JohnC' })这将 name 为 Jhon 的文档的姓名修改为 JohnC。
你还演示了如何用完整的文档进行更新:
> db.students.update({ name: 'Amy2' }, stu_update2)这个命令将找到 name 为 Amy2 的文档,并用 stu_update2 文档替换它。
> db.students.find()
{ "_id" : ObjectId("5fc5deecb306bbfe8da27368"), "name" : "Jhon", "age" : 21, "sex" :
"male" }
{ "_id" : ObjectId("5fc5e049b306bbfe8da27369"), "name" : "Amy" }
{ "_id" : ObjectId("5fc5e11db306bbfe8da2736a"), "name" : "Amy2", "age" : 16, "sex" :
"male" }
> db.students.update({name:'Jhon'},{name:'JohnC'})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.students.find()
{ "_id" : ObjectId("5fc5deecb306bbfe8da27368"), "name" : "JohnC" }
{ "_id" : ObjectId("5fc5e049b306bbfe8da27369"), "name" : "Amy" }
{ "_id" : ObjectId("5fc5e11db306bbfe8da2736a"), "name" : "Amy2", "age" : 16, "sex" :
"male" }
> stu_update2 = { "_id" : ObjectId("5fc5e11db306bbfe8da2736a"), "name" : "Amy2", "age" : 16,
"sex" : "male" }
{
"_id" : ObjectId("5fc5e11db306bbfe8da2736a"),
"name" : "Amy2",
"age" : 16,
"sex" : "male"
}
> stu_update2.name = "Amy3"
Amy3
> db.students.update({name:'Amy2'},stu_update2)
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.students.find()
{ "_id" : ObjectId("5fc5deecb306bbfe8da27368"), "name" : "JohnC" }
{ "_id" : ObjectId("5fc5e049b306bbfe8da27369"), "name" : "Amy" }
{ "_id" : ObjectId("5fc5e11db306bbfe8da2736a"), "name" : "Amy3", "age" : 16, "sex" :
"male" }
>4. 删除数据(Delete)
删除数据时,你使用了 remove() 方法:
> db.students.remove({ name: 'Amy' })这会删除 name 为 Amy 的文档。
如果删除所有文档,可以使用如下命令:
> db.students.remove({})这会清空 students 集合中的所有数据。
> db.students.find()
{ "_id" : ObjectId("5fc5deecb306bbfe8da27368"), "name" : "JohnC" }
{ "_id" : ObjectId("5fc5e049b306bbfe8da27369"), "name" : "Amy" }
{ "_id" : ObjectId("5fc5e11db306bbfe8da2736a"), "name" : "Amy3", "age" : 16, "sex" :
"male" }
> db.students.remove({name:'Amy'})
WriteResult({ "nRemoved" : 1 })
> db.students.find()
{ "_id" : ObjectId("5fc5deecb306bbfe8da27368"), "name" : "JohnC" }
{ "_id" : ObjectId("5fc5e11db306bbfe8da2736a"), "name" : "Amy3", "age" : 16, "sex" :
"male" }
> db.students.remove({ })
WriteResult({ "nRemoved" : 2 })
> db.students.find()总结:
- Create(新增):
insert()方法。 - Read(查询):
find()和findOne()方法。 - Update(修改):
update()方法。 - Delete(删除):
remove()方法。
在 MongoDB 中,AND 条件用于匹配同时满足多个查询条件的文档。MongoDB 默认支持 AND 条件,当你在 find() 查询中同时指定多个条件时,MongoDB 会自动将它们视为 AND 条件。
示例:使用 AND 条件查询
假设我们有一个 students 集合,包含以下文档:
{ "_id": 1, "name": "Jhon", "age": 21, "sex": "male" } { "_id": 2, "name": "Amy", "age": 22, "sex": "female" } { "_id": 3, "name": "Mike", "age": 21, "sex": "male" } { "_id": 4, "name": "Emma", "age": 22, "sex": "female" }我们希望查询年龄为 21 且性别为男性的学生,这就需要使用 AND 条件:
db.students.find({ age: 21, sex: "male" })这将返回所有同时满足这两个条件的文档(即,年龄为 21 且性别为 "male")。
解释:
- 在
find()方法中,多个查询条件(如{ age: 21, sex: "male" })会自动被视为 AND 条件。 - 上述查询会返回:
{ "_id": 1, "name": "Jhon", "age": 21, "sex": "male" } { "_id": 3, "name": "Mike", "age": 21, "sex": "male" }这两个文档都符合 age: 21 和 sex: "male" 的条件。
使用 $and 显式指定 AND 条件
你也可以使用 $and 操作符来显式指定多个条件,特别是在需要组合更复杂的查询时。$and 操作符接受一个数组,数组中的每个元素是一个查询条件对象。
例如,如果我们想查询年龄为 21 且性别为男性的学生,可以显式使用 $and 操作符:
db.students.find({ $and: [ { age: 21 }, { sex: "male" } ] })
这条查询与上面那个默认 AND 查询的效果相同,都会返回:
{ "_id": 1, "name": "Jhon", "age": 21, "sex": "male" } { "_id": 3, "name": "Mike", "age": 21, "sex": "male" }
使用多个 AND 条件
如果你要查询多个条件,可以继续在 $and 数组中添加更多的查询对象。例如,查询年龄为 21 且性别为男性,且名字包含 "M" 的学生:
db.students.find({ $and: [ { age: 21 }, { sex: "male" }, { name: /M/ } ] })这个查询会返回:
{ "_id": 3, "name": "Mike", "age": 21, "sex": "male" }- 默认情况下,在 MongoDB 的
find()查询中使用多个条件时,它们会自动作为 AND 条件处理。 - 如果需要更复杂的 AND 查询,可以使用
$and操作符来显式指定多个条件。 $and可以帮助你组合任意多个查询条件,支持灵活的查询逻辑。
在 MongoDB 中,OR 条件用于匹配至少满足其中一个查询条件的文档。与 AND 条件类似,OR 条件可以通过使用 $or 操作符显式指定。MongoDB 默认并不自动处理 OR 条件,需要使用 $or 来明确指定多个查询条件中的任意一个。
示例:使用 OR 条件查询
假设我们有一个 students 集合,包含以下文档:
{ "_id": 1, "name": "Jhon", "age": 21, "sex": "male" } { "_id": 2, "name": "Amy", "age": 22, "sex": "female" } { "_id": 3, "name": "Mike", "age": 21, "sex": "male" } { "_id": 4, "name": "Emma", "age": 22, "sex": "female" }假设我们想查询年龄为 21 或性别为女性的学生,这就需要使用 OR 条件。
1. 使用 $or 显式指定 OR 条件
你可以使用 $or 操作符,后跟一个包含多个查询条件的数组。例如,查询年龄为 21 或性别为女性的学生:
db.students.find({ $or: [ { age: 21 }, { sex: "female" } ] })查询结果
这条查询会返回以下文档,符合 age: 21 或 sex: "female" 的学生:
{ "_id": 1, "name": "Jhon", "age": 21, "sex": "male" } { "_id": 2, "name": "Amy", "age": 22, "sex": "female" } { "_id": 3, "name": "Mike", "age": 21, "sex": "male" } { "_id": 4, "name": "Emma", "age": 22, "sex": "female" }示例:AND 和 OR 联合使用
假设我们有一个 students 集合,包含以下文档:
{ "_id": 1, "name": "Jhon", "age": 21, "sex": "male" } { "_id": 2, "name": "Amy", "age": 22, "sex": "female" } { "_id": 3, "name": "Mike", "age": 21, "sex": "male" } { "_id": 4, "name": "Emma", "age": 22, "sex": "female" }1. 使用 $and 和 $or 结合查询
假设我们想查询:
- 年龄为 21 或 22,
- 且性别为 "female" 或名字包含字母 "M"。
为了实现这个查询,我们需要用到 $and 和 $or 操作符,组合多个条件。查询可以写作:
db.students.find({ $and: [ { $or: [ { age: 21 }, { age: 22 } ] }, // 年龄为 21 或 22 { $or: [ { sex: "female" }, { name: /M/ } ] } // 性别为 female 或名字包含 M ] })
查询结果
这条查询会返回符合以下两个条件的文档:
- 年龄为 21 或 22
- 性别为 "female" 或名字中包含字母 "M"。
查询结果:
{ "_id": 2, "name": "Amy", "age": 22, "sex": "female" } { "_id": 3, "name": "Mike", "age": 21, "sex": "male" } { "_id": 4, "name": "Emma", "age": 22, "sex": "female" }2. 复杂的联合查询
假设我们想查询以下情况:
- 年龄为 21 或 22,
- 并且名字包含字母 "J",
- 或者性别为 "male" 且年龄大于 21。
查询可以这样写:
db.students.find({ $and: [ { $or: [ { age: 21 }, { age: 22 } ] }, // 年龄为 21 或 22 { name: /J/ }, // 名字包含 "J" { $or: [ { sex: "male" }, // 性别为 "male" { age: { $gt: 21 } } // 年龄大于 21 ]} ] })查询结果
这条查询会返回符合以下条件的文档:
- 年龄为 21 或 22
- 名字包含字母 "J"
- 或者,性别为 "male" 且年龄大于 21
查询结果:
{ "_id": 1, "name": "Jhon", "age": 21, "sex": "male" }在 MongoDB 中,条件操作符用于比较表达式中的值,以便从集合中筛选出符合条件的数据。常用的条件操作符包括 $gt、$lt、$gte 和 $lte,它们分别用于进行大于、小于、大于等于和小于等于的比较。
以下是这些条件操作符的具体说明和使用方法:
1. $gt(大于)
- 说明:用于查询大于指定值的文档。
- 语法:
{ field: { $gt: value } } - 示例:查询
age大于 25 的文档:
db.users.find({ age: { $gt: 25 } })2. $lt(小于)
- 说明:用于查询小于指定值的文档。
- 语法:
{ field: { $lt: value } } - 示例:查询
age小于 30 的文档:
db.users.find({ age: { $lt: 30 } })3. $gte(大于等于)
- 说明:用于查询大于或等于指定值的文档。
- 语法:
{ field: { $gte: value } } - 示例:查询
age大于或等于 18 的文档:
db.users.find({ age: { $gte: 18 } })4. $lte(小于等于)
- 说明:用于查询小于或等于指定值的文档。
- 语法:
{ field: { $lte: value } } - 示例:查询
age小于或等于 50 的文档:
db.users.find({ age: { $lte: 50 } })复合查询
这些条件操作符不仅可以单独使用,还可以与其他查询条件组合使用。例如,结合 $gt 和 $lt 操作符,查询年龄在 18 到 30 之间的文档:
db.users.find({ age: { $gt: 18, $lt: 30 } })此查询将返回 age 大于 18 且小于 30 的所有文档。
示例:查询年龄在 18 到 50 之间的男性用户
假设 users 集合包含如下文档:
{ "_id": 1, "name": "John", "age": 25, "sex": "male" } { "_id": 2, "name": "Alice", "age": 22, "sex": "female" } { "_id": 3, "name": "Bob", "age": 30, "sex": "male" } { "_id": 4, "name": "Charlie", "age": 35, "sex": "male" } { "_id": 5, "name": "David", "age": 60, "sex": "male" }查询年龄在 18 到 50 之间的男性用户:
db.users.find({ age: { $gte: 18, $lte: 50 }, sex: "male" })查询结果:
{ "_id": 1, "name": "John", "age": 25, "sex": "male" } { "_id": 3, "name": "Bob", "age": 30, "sex": "male" } { "_id": 4, "name": "Charlie", "age": 35, "sex": "male" }$gt:大于指定值。$lt:小于指定值。$gte:大于或等于指定值。$lte:小于或等于指定值。
这些条件操作符是 MongoDB 查询中非常重要的部分,它们使得你能够执行更加灵活和精确的数据筛选。在实际应用中,可以通过将这些操作符与其他操作符(如 $and、$or 等)组合,构建复杂的查询条件。
1. MongoDB $type 操作符
$type 操作符用于查询指定字段的 BSON 数据类型。
语法:
{ field: { $type: <BSON_type> } }
- 常见的 BSON 类型:
- 1: Double
- 2: String
- 3: Object
- 4: Array
- 5: Binary data
- 8: Boolean
- 9: Date
- 10: Null
- 16: Integer
- 18: Undefined
示例:
查询所有 age 字段是整数类型的文档:
db.users.find({ age: { $type: 16 } })
查询所有 data 字段是数组类型的文档:
db.users.find({ data: { $type: 4 } })
2. MongoDB limit() 和 skip() 方法
limit():限制查询结果的数量。skip():跳过查询结果的前 N 个文档。
语法:
limit():db.collection.find().limit(n)skip():db.collection.find().skip(n)
示例:
- 查询
users集合中的前 5 个文档:
db.users.find().limit(5)
- 查询
users集合中的跳过前 3 个文档,获取接下来的 5 个文档:
db.users.find().skip(3).limit(5)
3. MongoDB sort() 方法
sort() 方法用于排序查询结果,可以按照升序(1)或降序(-1)进行排序。
语法:
db.collection.find().sort({ field: 1 }) // 升序 db.collection.find().sort({ field: -1 }) // 降序
示例:
- 按
age字段升序排序:
db.users.find().sort({ age: 1 })
- 按
age字段降序排序:
db.users.find().sort({ age: -1 })
- 按多个字段排序:先按
age降序,再按name升序排序:
db.users.find().sort({ age: -1, name: 1 })
4. MongoDB createIndex() 方法
createIndex() 方法用于为集合创建索引,优化查询性能。
语法:
db.collection.createIndex({ field: 1 }) // 升序索引 db.collection.createIndex({ field: -1 }) // 降序索引
示例:
- 为
users集合的age字段创建升序索引:
db.users.createIndex({ age: 1 })
- 为
users集合的name字段创建降序索引:
db.users.createIndex({ name: -1 })
- 为
users集合的name和age字段创建复合索引:
db.users.createIndex({ name: 1, age: -1 })
5. MongoDB aggregate() 方法
aggregate() 方法用于进行聚合操作,通过多个管道操作符对文档进行处理,如过滤、分组、排序等。
语法:
db.collection.aggregate([{ $stage: { ... } }])
常见的聚合阶段:
$match: 用于过滤文档,类似于find()查询。$group: 用于分组操作,通常与聚合函数一起使用。$sort: 用于排序。$project: 用于指定输出字段。
示例:
- 查询
users集合中所有age大于 20 的用户,并按age降序排序:
db.users.aggregate([ { $match: { age: { $gt: 20 } } }, { $sort: { age: -1 } } ])
- 分组统计每个
age的用户数量:
db.users.aggregate([ { $group: { _id: "$age", count: { $sum: 1 } } } ])
6. MongoDB createCollection() 方法
createCollection() 方法用于显式地创建一个集合。通常在 MongoDB 中,插入数据时会自动创建集合,但有时也需要手动创建集合并定义集合的一些选项,如索引、数据存储等。
语法:
db.createCollection(name, options)
name: 集合的名称。options: 可选参数,如capped(是否为固定集合),size(集合的最大字节大小)。
示例:
- 创建一个名为
users的集合,并设置为固定大小:
db.createCollection("users", { capped: true, size: 5242880 })
7. MongoDB drop() 方法
drop() 方法用于删除集合或索引。
语法:
- 删除集合:
db.collection.drop()
- 删除索引:
db.collection.dropIndex("index_name")
示例:
- 删除
users集合:
db.users.drop()
- 删除
age字段的索引:
db.users.dropIndex("age_1")
总结:
$type:用于查询字段的 BSON 数据类型。limit():限制查询结果的数量。skip():跳过查询结果的前 N 个文档。sort():对查询结果进行排序。createIndex():为集合创建索引,提高查询性能。aggregate():执行聚合操作,对文档进行复杂的处理和分析。createCollection():手动创建集合,并可以设置集合的一些选项。drop():删除集合或索引。
14 Python操作MongoDB
from pymongo import MongoClient
class TestMongo(object):
def __init__(self):
self.client = MongoClient()
self.db = self.client['students']
def add_one(self):
''' 新增数据 '''
post = {
"name" : "张三",
"age" : 17,
"sex" : "male",
"grade" : 98.0,
"address" : "--"
}
return self.db.students.insert_one(post)
def main():
obj = TestMongo()
rest = obj.add_one()
print(rest.inserted_id)
if __name__ == '__main__':
main()from datetime import datetime
from pymongo import MongoClient
from bson.objectid import ObjectId
from mongoengine import connect, Document, EmbeddedDocument, \
StringField, IntField, FloatField, DateTimeField, ListField, \
EmbeddedDocumentField
connect('test')
# connect('students', host='192.168.1.35', port=27017)
#connect('test', host='mongodb://localhost/students')
class Grade(EmbeddedDocument):
''' 学生的成绩 '''
name = StringField(required=True)
score = FloatField(required=True)
SEX_CHOICES = (
('female', '女'),
('male', '男')
)
class Student(Document):
''' 学生模型 '''
name = StringField(required=True, max_lenght=32)
age = IntField(required=True)
sex = StringField(required=True, choices=SEX_CHOICES)
grade = FloatField()
created_at = DateTimeField(default=datetime.now())
grades = ListField(EmbeddedDocumentField(Grade))
address = StringField()
school = StringField()
meta = {
'collection': 'students'
}
class TestMongoEngine(object):
def add_one(self):
''' 添加一条数据到数据库 '''
yuwen = Grade(
name='语文',
score=95
)
english = Grade(
name='英语',
score=89)
stu_obj = Student(
name='张三',
age=21,
sex='male',
grades=[yuwen, english]
)
# stu_obj.test = 'OK'
stu_obj.save()
return stu_obj
def get_one(self):
''' 查询一条数据 '''
return Student.objects.first()
def get_more(self):
''' 查询多条数据 '''
# return Student.objects
return Student.objects.all()
#return Student.objects[:5]
#return Student.objects().order_by('grade')
def get_one_from_oid(self, oid):
''' 查询指定ID的数据 '''
return Student.objects.filter(id=oid).first()
def update(self):
''' 修改数据 '''
# 修改一条数据
# rest = Student.objects.filter(sex='male').update_one(inc__age=1)
# return rest
# 修改多条数据
rest = Student.objects.filter(sex='male').update(inc__age=1)
return rest
def delete(self):
''' 删除数据 '''
# 删除一条数据
rest = Student.objects.filter(sex='male').first().delete()
# 删除多条数据
rest = Student.objects.filter(sex='male').delete()
return rest
def main():
obj = TestMongoEngine()
# rest = obj.add_one()
# print(rest.id)
# rest = obj.get_one()
# print(rest.id)
rest = obj.get_more()
print(type(rest))
for item in rest:
print(item.name)
# rest = obj.get_one_from_oid('593bb8e7fa3ebd091078d40e')
# print(rest.name)
# rest = obj.update()
# print(rest)
# rest = obj.delete()
# print(rest)
if __name__ == '__main__':
main()from datetime import datetime
from mongoengine import *
connect('students')
# connect('students', host='192.168.1.35', port=27017)
#connect('test', host='mongodb://localhost/students')
class Grade(EmbeddedDocument):
"""学生成绩"""
name = StringField(required=True)
score = FloatField(required=True)
SEX_CHOICES=(
('female','女'),
('male','男')
)
class Student(Document):
"""学生模型"""
name = StringField(required=True,max_length=32)
age = IntField(required=True)
sex = StringField(required=True,choices=SEX_CHOICES)
grade = FloatField()
created_at = DateTimeField(default=datetime.now())
grades = ListField(EmbeddedDocumentField(Grade))
address = StringField()
school = StringField()
meta = {
'collection':'students'
}
def __str__(self):
# 创建一个包含学生信息的字符串
grades_str = ', '.join([f"{grade.name}: {grade.score}" for grade in self.grades])
return (f"Student Name: {self.name}, Age: {self.age}, Sex: {self.sex}, "
f"Grade: {self.grade}, Created At: {self.created_at}, "
f"Address: {self.address}, School: {self.school}, "
f"Grades: [{grades_str}]")
class TestMongoEngine(object):
def add_one(self):
"""新增数据"""
yuwen = Grade(
name='语文',
score=95
)
english = Grade(
name='英语',
score=89
)
stu_obj = Student(
name='张三',
age=21,
sex='male',
grades=[yuwen,english]
)
# stu_obj.test = 'OK'
stu_obj.save()
return stu_obj
def get_one(self):
"""查询一条数据"""
return Student.objects.first()
def get_more(self):
"""查询多条数据"""
return Student.objects.all()
def get_one_from_oid(self,oid):
"""查询指定ID的数据"""
return Student.objects.filter(id=oid).first()
def update(self):
"""修改数据"""
# 修改一条数据
rest = Student.objects.filter(sex='male').update_one(inc__age=1)
return rest
# # 修改多个数据
# rest = Student.objects.filter(sex='male').update(inc__age=1)
# return rest
def delete(self):
"""删除数据"""
# 删除一条数据
rest = Student.objects.filter(sex='male').first().delete()
# 删除多条数据
# rest = Student.objects.filter(sex='male').delete()
return rest
def main():
obj = TestMongoEngine()
# rest = obj.add_one()
# print(rest.id)
# rest = obj.get_one()
# print(rest.id)
# rest = obj.get_more()
# print(type(rest))
# for item in rest:
# print(item.name)
rest = obj.get_one_from_oid('67469abc0c7193368d06eaf6')
print(rest)
# rest = obj.update()
# print(rest)
# rest = obj.delete()
# print(rest)
if __name__ == '__main__':
main()15 MongoDB网易新闻实战
from datetime import *
from flask import Flask, render_template, redirect, flash, url_for
from datetime import datetime
from flask_mongoengine import MongoEngine
from forms import NewsForm_mongo
app = Flask(__name__)
app.config['MONGODB_SETTINGS'] = {'db' : 'mongo_news','host':'127.0.0.1','port':27017}
db = MongoEngine(app)
app.config['SECRET_KEY'] = 'this is a mongodb key'
NEWS_TYPE = (
('推荐','推荐'),
('百家','百家'),
('本地','本地'),
('图片','图片'))
class News(db.Document):
""" 新闻模型 """
title = db.StringField(required=True, max_lenght=64)
img_url = db.StringField(required=True)
content = db.StringField(required=True)
is_valid = db.BooleanField(default=True)
news_type = db.StringField(required=True, choices=NEWS_TYPE)
created_at = db.DateTimeField(default=datetime.now())
updated_at = db.DateTimeField(default=datetime.now())
meta = {'collection':'news',
'ordering':['-created_at']
}
# def __repr__(self):
# return '<News %r>' % self.title
def gettime():
time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
return time
@app.route('/')
def index():
""" 新闻首页 """
news_list = News.objects.all()
return render_template("index.html",news_list = news_list,var=gettime())
@app.route('/cat/<name>/', methods=['GET', 'POST'])
def cat(name):
''' 栏目 '''
news_list = News.objects.filter(is_valid=True, news_type=name).all()
return render_template('cat.html', news_list=news_list,var=gettime())
@app.route('/detail/<pk>/', methods=['GET', 'POST'])
def detail(pk):
''' 新闻详情页 '''
obj = News.objects.filter(pk=pk).first_or_404()
return render_template('detail.html', new_obj=obj,var=gettime())
################################
@app.route('/admin/', methods=['GET', 'POST'])
@app.route('/admin/<page>/', methods=['GET', 'POST'])
def admin(page=None):
''' 后台首页 '''
# 如果page参数没有传就默认显示首页
if page == None:
page = 1
page_data = News.objects.paginate(page=int(page), per_page=5)
return render_template('admin/index.html', page_data=page_data, page=int(page))
@app.route('/admin/add/', methods=['GET', 'POST'])
def add():
''' 添加新闻 '''
form = NewsForm_mongo()
if form.validate_on_submit:
# 获取数据
new_obj = News(
title=form.title.data,
img_url=form.img_url.data,
content=form.content.data,
news_type=form.news_type.data
)
new_obj.save()
flash('新闻添加成功')
return redirect(url_for('admin'))
return render_template('admin/add.html', form=form)
@app.route('/admin/delete/<pk>/', methods=['GET', 'POST'])
def delete(pk):
''' 删除新闻 '''
new_obj = News.objects.filter(pk=pk).first()
print(new_obj.title)
if not new_obj:
return 'no'
# 逻辑删除
new_obj.is_valid = False
new_obj.save()
return 'yes'
# 物理删除
# new_obj.delete()
# return 'yes'
@app.route('/admin/update/<pk>/', methods=['POST', 'GET'])
def update(pk):
''' 修改新闻 '''
new_obj = News.objects.get_or_404(pk=pk)
print(new_obj.title)
form = NewsForm_mongo(obj=new_obj)
if form.validate_on_submit():
new_obj.title = form.title.data
new_obj.content = form.content.data
new_obj.news_type = form.news_type.data
new_obj.img_url = form.img_url.data
new_obj.save()
flash('新闻修改成功')
return redirect(url_for('admin'))
return render_template('admin/update.html', form=form)
if __name__ == '__main__':
app.run(debug=True)
# from flask_pymongo import PyMongo
# from flask import Flask
#
# app = Flask(__name__)
# app.config["MONGO_URI"] = "mongodb://127.0.0.1:27017/mongo_news"
# mongo = PyMongo(app)
#
# def insert_data():
# mongo.db.news.insert_many( # 修正大小写
# [
# {
# "title": "朝鲜特种部队视频公布 展示士兵身体素质与意志",
# "img_url": "/static/img/news/01.png",
# "content": "新闻内容",
# "is_valid": True,
# "news_type": "推荐"
# },
# {
# "title": "男子长得像\"祁同伟\"挨打 打人者:为何加害检察官",
# "img_url": "/static/img/news/02.png",
# "content": "新闻内容",
# "is_valid": True,
# "news_type": "百家"
# },
# {
# "title": "导弹来袭怎么办?日本政府呼吁国民躲入地下通道",
# "img_url": "/static/img/news/03.png",
# "content": "新闻内容",
# "is_valid": True,
# "news_type": "本地"
# },
# {
# "title": "美媒:朝在建能发射3发以上导弹的3000吨级新潜艇",
# "img_url": "/static/img/news/04.png",
# "content": "新闻内容",
# "is_valid": True,
# "news_type": "推荐"
# },
# {
# "title": "证监会:前发审委员冯小树违法买卖股票被罚4.99亿",
# "img_url": "/static/img/news/08.png",
# "content": "新闻内容",
# "is_valid": True,
# "news_type": "百家"
# },
# {
# "title": "外交部回应安倍参拜靖国神社:同军国主义划清界限",
# "img_url": "/static/img/news/new1.jpg",
# "content": "新闻内容",
# "is_valid": True,
# "news_type": "推荐"
# },
# {
# "title": "外交部回应安倍参拜靖国神社:同军国主义划清界限",
# "img_url": "/static/img/news/new1.jpg",
# "content": "新闻内容",
# "is_valid": True,
# "news_type": "百家"
# },
# {
# "title": "\"萨德\"供地违法?韩民众联名起诉要求撤回供地",
# "img_url": "/static/img/news/new1.jpg",
# "content": "新闻内容",
# "is_valid": True,
# "news_type": "百家"
# }
# ]
# )
# print("Data inserted successfully!")
#
# if __name__ == '__main__':
# insert_data() # 运行插入数据函数
















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









