







1. 基本形式
给定由d个属性描述的示例 x = ( x 1 ; x 2 ; . . . x d ) x = (x_1;x_2;...x_d) x=(x1;x2;...xd),其中 x i x_i xi是x在第i个属性上的取值,线性模型试图学得一个通过属性的线性组合来进行预测的函数,即:
f ( x ) = w 1 x 1 + w 2 x 2 + . . . + w d x d + b f(x) = w_1x_1+w_2x_2+...+w_dx_d +b f(x)=w1x1+w2x2+...+wdxd+b
写成向量形式就是:
f ( x ) = w T x + b f(x) = w^Tx+b f(x)=wTx+b
w和b就是需要学习的参数,分别为权重(weights)和偏移(bios)。
2. 线性回归
2.1 最小二乘线性回归
线性回归试图学得 $ f(x_i)=wx_i+b,\text{ 使得 }f(x_i)\simeq y_i\mathrm{~.}$那么为了确定w和b,就要衡量f(x)与y之间的差别。均方误差是回归任务中的最常用的性能度量,因此就可以让均方误差最小,从而使得f(x)与y更接近。即:
( w ∗ , b ∗ ) = arg min ( w , b ) ∑ i = 1 m ( f ( x i ) − y i ) 2 = arg min ( w , b ) ∑ i = 1 m ( y i − w x i − b ) 2 . \begin{aligned} (w^{*},b^{*})& =\arg\min_{(w,b)}\sum_{i=1}^m\left(f\left(x_i\right)-y_i\right)^2 \\ &=\arg\min_{(w,b)}\sum_{i=1}^m(y_i-wx_i-b)^2~. \end{aligned} (w∗,b∗)=arg(w,b)mini=1∑m(f(xi)−yi)2=arg(w,b)mini=1∑m(yi−wxi−b)2 .
这种求解w和b的方式其实就是画一条直线,使得所有样本到直线上的欧几里得距离之和最小,因此也叫做最小二乘参数估计。
2.2 对数线性回归
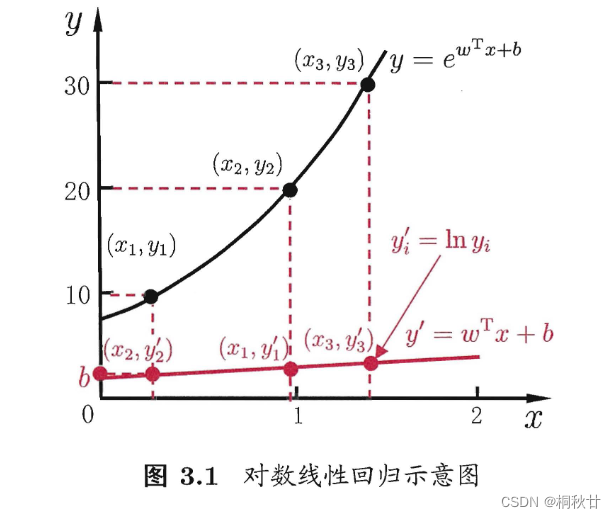
假设我们认为示例所对应的输出标记是在指数尺度上变化,那就可将输出标记的对数作为线性模型逼近的目标, 即
ln y = w T x + b . \ln y=\boldsymbol{w^\mathrm{T}}\boldsymbol{x}+b. lny=wTx+b.
这种方法叫做对数线性回归,形式上仍然是线性回归,但实质是在求取输入空间到输出空间的对数函数映射。
2.3 广义线性模型
将对数函数ln广义到任意可微函数 g ( ⋅ ) g(·) g(⋅),令
y = g − 1 ( w T x + b ) y=g^{-1}(\boldsymbol{w}^\mathrm{T}\boldsymbol{x}+b) y=g−1(wTx+b)
这样得到的模型就是广义线性模型,其中 g ( ⋅ ) g(·) g(⋅)被称为联系函数,显然对数线性回归是广义线性模型的特例之一。
3. 对数几率回归
回归任务的目标是通过输入一个值,可以预测一个输出值出来,但如果我们的任务是分类任务,那么回归模型就无法解决,但只需找一个单调可微函数将分类任务的真实标记y与线性回归模型的预测值联系起来即可,也即做一个映射函数,将回归模型的预测值R映射到(0,1)区间内。
考虑最简单的二分类任务,假设其输出标记为{0, 1},那么只需将预测值转换为0或者1即可。最理想的是单位阶跃函数,即
y = { 0 , z < 0 ; 0.5 , z = 0 ; 1 , z > 0 , y=\left\{\begin{array}{cc}0,&z<0;\\0.5,&z=0;\\1,&z>0,\end{array}\right. y=⎩ ⎨ ⎧0,0.5,1,z<0;z=0;z>0,
如果预测值小于0,则判为0,大于0则判断为1,若刚好等于0,则可任意判别。
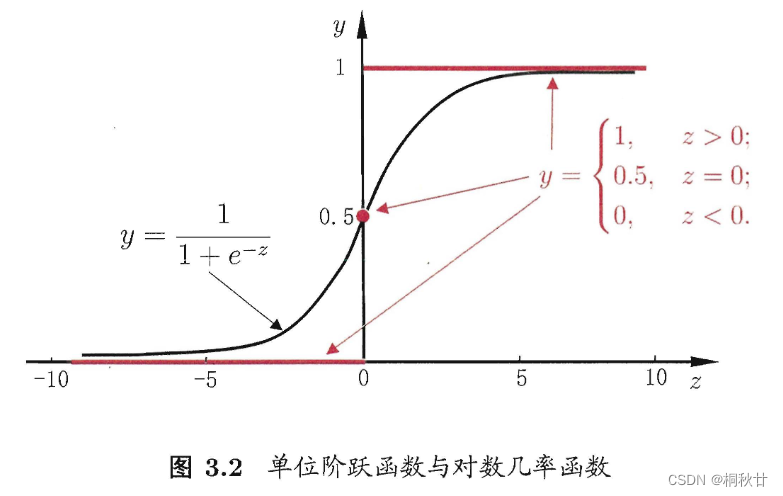
但单位阶跃函数不连续,因此对数几率函数是一个常用的替代函数:
y = 1 1 + e − z . y=\frac1{1+e^{-z}}. y=1+e−z1.
这种模型就叫做对数几率回归,虽然叫做回归,但其实是分类学习方法。
4. 线性判断分析
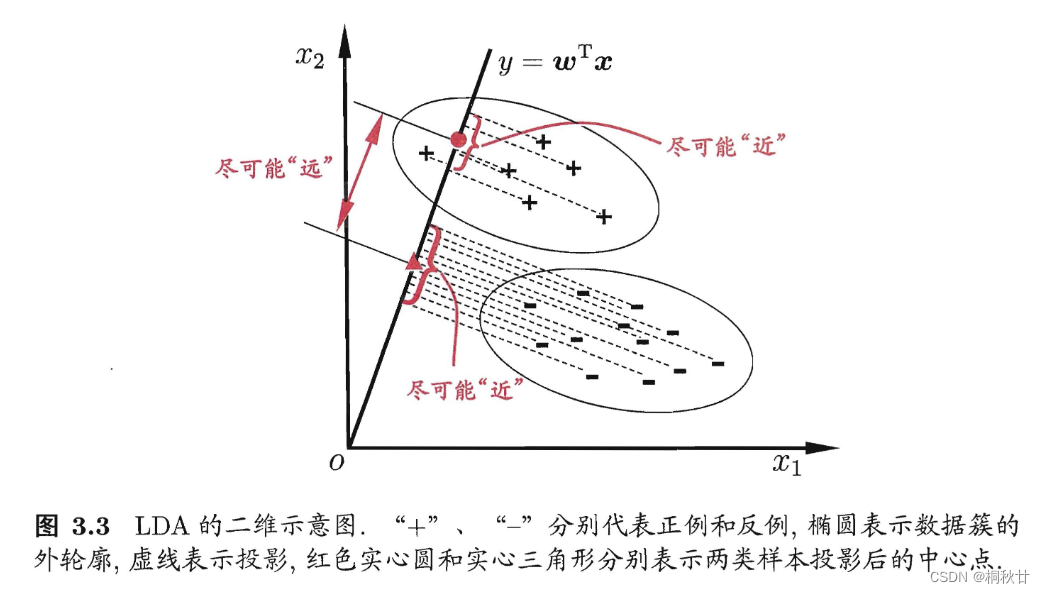
LDA 的思想非常朴素: 给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线 上,再根据投影点的位置来确定新样本的类别。
5. 多分类学习
多分类学习的基本思路是“拆解法”,即将多分类任务拆为若干个二分类任务求解。具体来说,就是先对问题进行拆分,然后拆除的每个二分类任务训练一个分类器。在测试时,对这些分类器的预测结果进行集成以获得最终的多分类结果。经典的拆分策略有三种:
-
一对一:将N个类别两两配对,产生N(N-1)/2个二分类任务,最终测试时通过投票产生最终结果,预测的最多的就是最终分类结果。
-
一对其余:将一个类作为正例,其余类作为反例训练N个分类器。
-
有一个分类器预测为正类:则结果就是正类
-
有多个分类器预测为正类:考虑各个分类器的置信度,选取置信度最大的类别。
-
-
多对多:取若干个类作为正类,若干个其他类作为反类
6. 类别不平衡问题
例如有998个反例,但正例只有2个,那么学习方法只需返回一个永远将新样本预测为反例的学习器,就能达到99.8%的精
度;然而这样的学习器往往没有价值,因为它不能预测出任何正例。
类别不平衡学习的基本策略——再缩放
-
反例欠采样:少采样一些反例
-
正例过采样:增加一些正例
-
阈值移动:通过修改判断是否为正值的阈值来达到目的,公式为:
y ′ 1 − y ′ = y 1 − y × m − m + . \frac{y^{\prime}}{1-y^{\prime}}=\frac y{1-y}\times\frac{m^-}{m^+}. 1−y′y′=1−yy×m+m−.
其中,y`是修正后的阈值,m-代表反例数目,m+代表正例数目。若无修正,y一般取0.5,代表正值反值概率相同。增加修正后,则观测几率就代表了真实几率。















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









