








生产环境中经常会看到要取一个表不同条件值的时候,写n多子查询查同一个表。本文整理一些典型案例和改写方法。核心思想就是减少对表的多次扫描,最好减成一次。
创建测试表
create table t1 as select * from dba_objects;
create index ind_object_id on t1(object_id);
create index ind_object_name on t1(object_name);
create index ind_owner on t1(owner);
create index ind_object_type on t1(object_type);
create table t2 as select * from cdb_objects;
create index ind_object_id_2 on t2(object_id);
create index ind_object_name_2 on t2(object_name);
create index ind_owner_2 on t2(owner);
create index ind_object_type_2 on t2(object_type);一、简单的case when改写
1. 单表多次union all
原sql
select 'O_SYS' as name,count(*) from t1 where owner='SYS'
union all
select 'O_SYSTEM' as name,count(*) from t1 where owner='SYSTEM'
union all
select 'T_TABLE' as name,count(*) from t1 where object_type='TABLE'
union all
select 'T_VIEW' as name,count(*) from t1 where object_type='VIEW';
SQL> select 'O_SYS' as name,count(*) from t1 where owner='SYS'
2 union all
3 select 'O_SYSTEM' as name,count(*) from t1 where owner='SYSTEM'
4 union all
5 select 'T_TABLE' as name,count(*) from t1 where object_type='TABLE'
6 union all
7 select 'T_VIEW' as name,count(*) from t1 where object_type='VIEW';
NAME COUNT(*)
-------- ----------
O_SYS 14555
O_SYSTEM 472
T_TABLE 1815
T_VIEW 6824查看执行计划
------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 40 (100)| | 4 |00:00:00.01 | 85 |
| 1 | UNION-ALL | | 1 | | | | 4 |00:00:00.01 | 85 |
| 2 | SORT AGGREGATE | | 1 | 1 | 66 | | 1 |00:00:00.01 | 58 |
|* 3 | INDEX FAST FULL SCAN| IND_OWNER | 1 | 15036 | 969K| 16 (0)| 00:00:01 | 14555 |00:00:00.01 | 58 |
| 4 | SORT AGGREGATE | | 1 | 1 | 66 | | 1 |00:00:00.01 | 3 |
|* 5 | INDEX RANGE SCAN | IND_OWNER | 1 | 472 | 31152 | 2 (0)| 00:00:01 | 472 |00:00:00.01 | 3 |
| 6 | SORT AGGREGATE | | 1 | 1 | 13 | | 1 |00:00:00.01 | 7 |
|* 7 | INDEX RANGE SCAN | IND_OBJECT_TYPE | 1 | 1815 | 23595 | 5 (0)| 00:00:01 | 1815 |00:00:00.01 | 7 |
| 8 | SORT AGGREGATE | | 1 | 1 | 13 | | 1 |00:00:00.01 | 17 |
|* 9 | INDEX RANGE SCAN | IND_OBJECT_TYPE | 1 | 6609 | 85917 | 17 (0)| 00:00:01 | 6824 |00:00:00.01 | 17 |
------------------------------------------------------------------------------------------------------------------------------------
2. 改写为case when避免重复扫描
select count(CASE WHEN owner='SYS' THEN 1 END) as O_SYS,
count(CASE WHEN owner='SYSTEM' THEN 1 END) as O_SYSTEM,
count(CASE WHEN object_type='TABLE' THEN 1 END) as T_TABLE,
count(CASE WHEN object_type='VIEW' THEN 1 END) as T_VIEW
from t1;
SQL> select count(CASE WHEN owner='SYS' THEN 1 END) as O_SYS,
2 count(CASE WHEN owner='SYSTEM' THEN 1 END) as O_SYSTEM,
3 count(CASE WHEN object_type='TABLE' THEN 1 END) as T_TABLE,
4 count(CASE WHEN object_type='VIEW' THEN 1 END) as T_VIEW
5 from t1;
O_SYS O_SYSTEM T_TABLE T_VIEW
---------- ---------- ---------- ----------
14555 472 1815 6824查看执行计划
---------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 112 (100)| | 1 |00:00:00.01 | 409 |
| 1 | SORT AGGREGATE | | 1 | 1 | 79 | | | 1 |00:00:00.01 | 409 |
| 2 | TABLE ACCESS FULL| T1 | 1 | 23760 | 1833K| 112 (1)| 00:00:01 | 22943 |00:00:00.01 | 409 |
---------------------------------------------------------------------------------------------------------------------
你发现值是对了,表也只扫描一次了,但是行列跟之前是反的。要跟之前一样的话需要用到行列转换函数 unpivot。
select name,val from
(select count(CASE WHEN owner='SYS' THEN 1 END) as O_SYS,
count(CASE WHEN owner='SYSTEM' THEN 1 END) as O_SYSTEM,
count(CASE WHEN object_type='TABLE' THEN 1 END) as T_TABLE,
count(CASE WHEN object_type='VIEW' THEN 1 END) as T_VIEW
from t1
)
unpivot (val for name in (O_SYS,O_SYSTEM,T_TABLE,T_VIEW));
SQL> select name,val from
2 (select count(CASE WHEN owner='SYS' THEN 1 END) as O_SYS,
3 count(CASE WHEN owner='SYSTEM' THEN 1 END) as O_SYSTEM,
4 count(CASE WHEN object_type='TABLE' THEN 1 END) as T_TABLE,
5 count(CASE WHEN object_type='VIEW' THEN 1 END) as T_VIEW
6 from t1
7 )
8 unpivot (val for name in (O_SYS,O_SYSTEM,T_TABLE,T_VIEW));
NAME VAL
-------- ----------
O_SYS 14555
O_SYSTEM 472
T_TABLE 1815
T_VIEW 6824查看执行计划
------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 114 (100)| | 4 |00:00:00.01 | 409 |
|* 1 | VIEW | | 1 | 4 | 76 | 114 (1)| 00:00:01 | 4 |00:00:00.01 | 409 |
| 2 | UNPIVOT | | 1 | | | | | 4 |00:00:00.01 | 409 |
| 3 | VIEW | | 1 | 1 | 52 | 112 (1)| 00:00:01 | 1 |00:00:00.01 | 409 |
| 4 | SORT AGGREGATE | | 1 | 1 | 79 | | | 1 |00:00:00.01 | 409 |
| 5 | TABLE ACCESS FULL| T1 | 1 | 23760 | 1833K| 112 (1)| 00:00:01 | 22943 |00:00:00.01 | 409 |
------------------------------------------------------------------------------------------------------------------------
二、简单的标量子查询改写
1. 改写规则
标量子查询 —— 在字段部分(select之后from之前)的子查询,典型例子:
select owner,(select object_name from t2 where t2.object_id = t1.object_id) from t1
如果主查询结果集小,一般不需要改写;某些特殊情况,还会将连接改写成标量子查询做优化
什么情况要改写:外层查询结果集大的时候。外层查询返回多少条非重复值,内层查询就要被循环执行多少次,类似于nest loop join。改为关联之后,在外层查询结果集大时就可以走上hash join,避免多次扫描
本质上还是小结果集走nest loop join,大结果集走hash join
当外层结果集大时,可以把标量子查询改为left join,另外原逻辑没有去重,所以改写后也不用。
为什么是left join?因为原逻辑是以外层表(左表)为基准,逐条匹配子查询表(右表)。换言之,最后返回的行数是要与左表一致的。
下面来看个实际的例子
2. 最简单的标量子查询改写
select owner,(select object_name from t2 where t2.object_id = t1.object_id) from t1

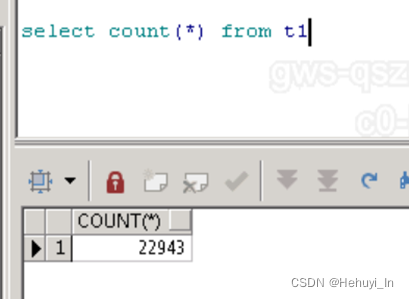
改写为left join
select t1.owner,t2.object_name from t1 left join t2 on t2.object_id = t1.object_id
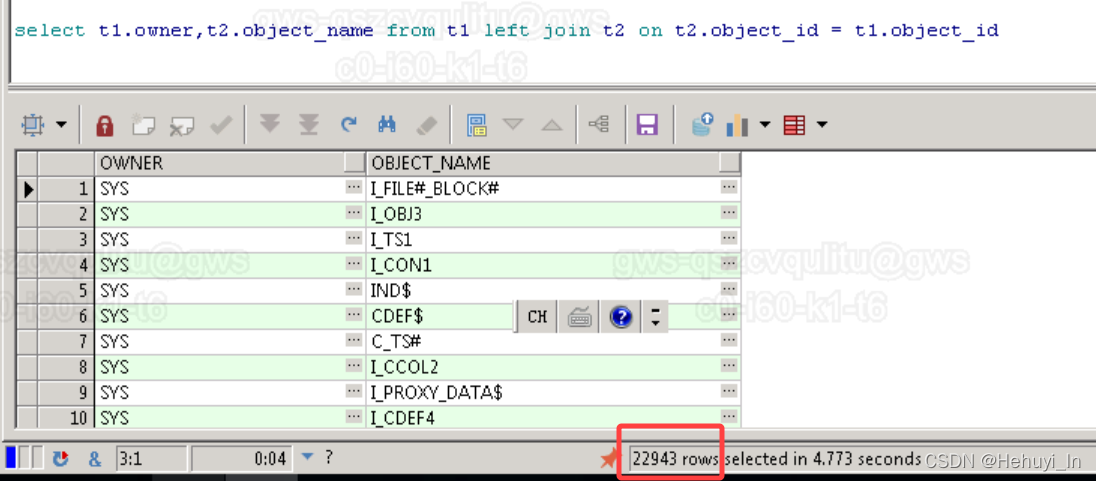
3. 加点条件的标量子查询
比最简单的加了一丢丢函数和条件,但改写原理是完全一样的
select owner,object_id ,
nvl((select object_name from t2 b where a.object_id=b.object_id),'unknown') as t2_name
from t1 a where owner not in ('SYS');
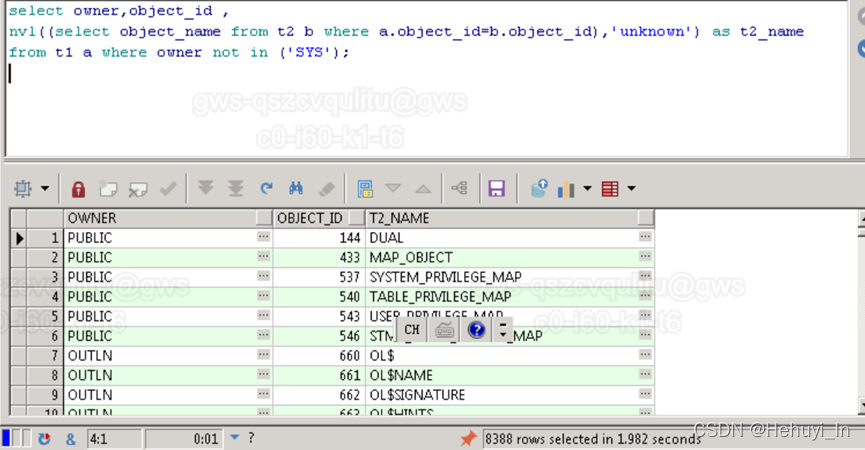
-------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
-------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 1597 (100)| | 8388 |00:00:00.01 | 959 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T2 | 8388 | 227 | 17933 | 2 (0)| 00:00:01 | 8388 |00:00:00.02 | 1832 |
|* 2 | INDEX RANGE SCAN | IND_OBJECT_ID_2 | 8388 | 91 | | 1 (0)| 00:00:01 | 8388 |00:00:00.01 | 954 |
|* 3 | TABLE ACCESS FULL | T1 | 1 | 8724 | 673K| 112 (1)| 00:00:01 | 8388 |00:00:00.01 | 959 |
-------------------------------------------------------------------------------------改写后
select a.owner,a.object_id,nvl(b.object_name,'unknown') as t2_name
from t1 a left join t2 b
on a.object_id=b.object_id
where a.owner not in ('SYS');
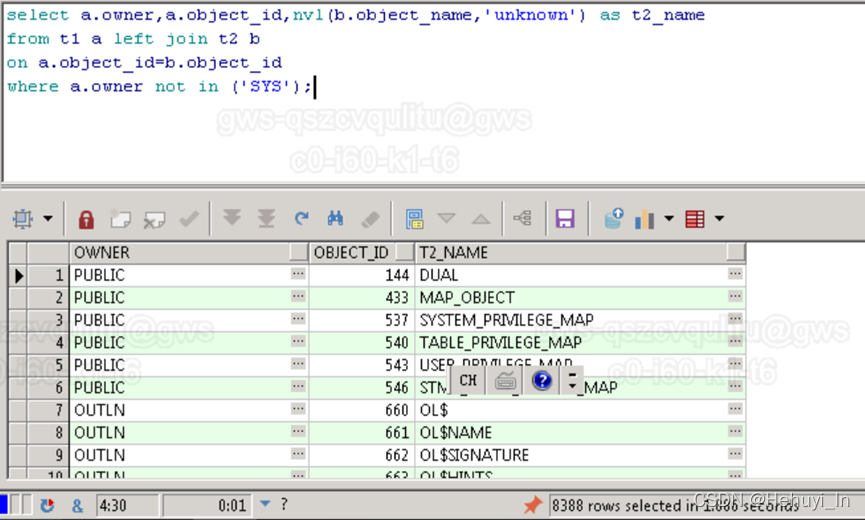
---------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 229 (100)| 8388 |00:00:00.02 | 1395 |
|* 1 | HASH JOIN OUTER | | 1 | 8724 | 1346K| 229 (1)| 00:00:01 8388 |00:00:00.02 | 1395 |
|* 2 | TABLE ACCESS FULL| T1 | 1 | 8724 | 673K| 112 (1)| 00:00:01 8388 |00:00:00.01 | 409 |
| 3 | TABLE ACCESS FULL| T2 | 1 | 22651 | 1747K| 118 (1)| 00:00:01 | 22948 |00:00:00.01 | 986 |
---------------------------------------------------------------------------------------------------------------------4. 带有聚合函数标量子查询
- 创建测试表
SQL> create table a(a1 varchar2(10),a2 int);
Table created.
SQL> create table b(b1 varchar2(10),b2 int);
Table created.
SQL> select * from a;
A1 A2
---------- ----------
h 3
k 5
h 8
h 2
q 1
SQL> select * from b;
B1 B2
---------- ----------
h 3
h 20
h 7
q 5
m 6- 原SQL,标量子查询中带聚合操作
select a1,(select sum(b2) from b where b.b1 = a.a1) sum from a;
SQL> select a1,(select sum(b2) from b where b.b1 = a.a1) sum from a;
A1 SUM
---------- ----------
h 30
h 30
h 30
q 5
k- 改为表连接
你注意子查询里看似没有group by分组,其实是有的,b1=a1就是分组条件。它在子查询按b1字段分组,然后过滤出符合b1=a1的行。所以改写的时候不仅需要left join,还需要group by
select a1,sum
from a
left join (select b1,sum(b2) sum from b group by b1) v_b1
on a1=v_b1.b1;
SQL> select a1,sum from a left join (select b1,sum(b2) sum from b group by b1) v_b1 on a1=v_b1.b1;
A1 SUM
---------- ----------
h 30
h 30
h 30
q 5
k 三、 标量子查询结合case when
看起来复杂,本质上就是前面简单改写例子的排列组合
1. 包含行转列的标量子查询改写
- 原SQL
select t1.object_name,
(select t2.data_object_id
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'INDEX') col1,
(select t2.data_object_id
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'TABLE') col2,
(select t2.data_object_id
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'PROCEDURE') col3
from t1
where t1.object_name LIKE 'LOG%';
---------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 3019 (100)| | 447 |00:00:00.01 | 437 |
|* 1 | TABLE ACCESS BY INDEX ROWID BATCHED| T2 | 447 | 23 | 897 | 2 (0)| 00:00:01 | 113 |00:00:00.01 | 128 |
|* 2 | INDEX RANGE SCAN | IND_OBJECT_ID_2 | 447 | 91 | | 1 (0)| 00:00:01 | 447 |00:00:00.01 | 79 |
|* 3 | TABLE ACCESS BY INDEX ROWID BATCHED| T2 | 447 | 18 | 702 | 2 (0)| 00:00:01 | 126 |00:00:00.01 | 128 |
|* 4 | INDEX RANGE SCAN | IND_OBJECT_ID_2 | 447 | 91 | | 1 (0)| 00:00:01 | 447 |00:00:00.01 | 79 |
|* 5 | TABLE ACCESS BY INDEX ROWID BATCHED| T2 | 447 | 2 | 78 | 9 (0)| 00:00:01 | 7 |00:00:00.03 | 9424 |
|* 6 | INDEX RANGE SCAN | IND_OBJECT_TYPE_2 | 447 | 192 | | 1 (0)| 00:00:01 | 85824 |00:00:00.01 | 37 |
|* 7 | TABLE ACCESS FULL | T1 | 1 | 447 | 35313 | 112 (1)| 00:00:01 | 447 |00:00:00.01 | 437 |
---------------------------------------------------------------------------------------------------------------------------------------------------- 改写:标量子查询 -> left join,重复查询 -> case when
select t1.object_name,
(case when t2.object_type = 'INDEX' then t2.data_object_id end) col1,
(case when t2.object_type = 'TABLE' then t2.data_object_id end) col2,
(case when t2.object_type = 'PROCEDURE' then t2.data_object_id end) col3
from t1 left join t2
on t2.object_id = t1.object_id
where t1.object_name LIKE 'LOG%';
---------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 229 (100)| 447 |00:00:00.01 | 870 |
|* 1 | HASH JOIN OUTER | | 1 | 447 | 52746 | 229 (1)| 00:00:01 447 |00:00:00.01 | 870 |
|* 2 | TABLE ACCESS FULL| T1 | 1 | 447 | 35313 | 112 (1)| 00:00:01 447 |00:00:00.01 | 409 |
| 3 | TABLE ACCESS FULL| T2 | 1 | 22651 | 862K| 118 (1)| 00:00:01 | 22948 |00:00:00.01 | 461 |
---------------------------------------------------------------------------------------------------------------------4. 行转列+聚合函数的标量子查询
- 原SQL
select t1.object_name,
(select max(t2.data_object_id)
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'INDEX') col1,
(select max(t2.data_object_id)
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'TABLE') col2,
(select max(t2.data_object_id)
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'PROCEDURE') col3
from t1
where t1.object_name LIKE 'LOG%';
明显这个执行计划复杂了不少
----------------------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
----------------------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 366 (100)| | 447 |00:00:00.01 | 1294 |
|* 1 | HASH JOIN OUTER | | 1 | 447 | 70179 | 366 (2)| 00:00:01 | 447 |00:00:00.01 | 1294 |
| 2 | JOIN FILTER CREATE | :BF0000 | 1 | 447 | 58557 | 247 (2)| 00:00:01 | 447 |00:00:00.01 | 863 |
|* 3 | HASH JOIN OUTER | | 1 | 447 | 58557 | 247 (2)| 00:00:01 | 447 |00:00:00.01 | 863 |
| 4 | JOIN FILTER CREATE | :BF0001 | 1 | 447 | 46935 | 129 (2)| 00:00:01 | 447 |00:00:00.01 | 432 |
|* 5 | HASH JOIN RIGHT OUTER | | 1 | 447 | 46935 | 129 (2)| 00:00:01 | 447 |00:00:00.01 | 432 |
| 6 | VIEW | VW_SSQ_1 | 1 | 192 | 4992 | 17 (6)| 00:00:01 | 192 |00:00:00.01 | 23 |
| 7 | HASH GROUP BY | | 1 | 192 | 7488 | 17 (6)| 00:00:01 | 192 |00:00:00.01 | 23 |
| 8 | TABLE ACCESS BY INDEX ROWID BATCHED| T2 | 1 | 192 | 7488 | 16 (0)| 00:00:01 | 192 |00:00:00.01 | 23 |
|* 9 | INDEX RANGE SCAN | IND_OBJECT_TYPE_2 | 1 | 192 | | 1 (0)| 00:00:01 | 192 |00:00:00.01 | 2 |
|* 10 | TABLE ACCESS FULL | T1 | 1 | 447 | 35313 | 112 (1)| 00:00:01 | 447 |00:00:00.01 | 409 |
| 11 | VIEW | VW_SSQ_2 | 1 | 1816 | 47216 | 119 (2)| 00:00:01 | 134 |00:00:00.01 | 431 |
| 12 | HASH GROUP BY | | 1 | 1816 | 70824 | 119 (2)| 00:00:01 | 134 |00:00:00.01 | 431 |
| 13 | JOIN FILTER USE | :BF0001 | 1 | 1816 | 70824 | 118 (1)| 00:00:01 | 134 |00:00:00.01 | 431 |
|* 14 | TABLE ACCESS FULL | T2 | 1 | 1816 | 70824 | 118 (1)| 00:00:01 | 134 |00:00:00.01 | 431 |
| 15 | VIEW | VW_SSQ_3 | 1 | 2315 | 60190 | 119 (2)| 00:00:01 | 123 |00:00:00.01 | 431 |
| 16 | HASH GROUP BY | | 1 | 2315 | 90285 | 119 (2)| 00:00:01 | 123 |00:00:00.01 | 431 |
| 17 | JOIN FILTER USE | :BF0000 | 1 | 2315 | 90285 | 118 (1)| 00:00:01 | 123 |00:00:00.01 | 431 |
|* 18 | TABLE ACCESS FULL | T2 | 1 | 2315 | 90285 | 118 (1)| 00:00:01 | 123 |00:00:00.01 | 431 |
----------------------------------------------------------------------------------------------------------------------------------------------------------- 改写:left join去标量子查询,case when去多次扫描,还要加一个,t2表按object_id分组,再按object_type取max(t2.data_object_id)
select t1.object_name,col1,col2,col3
from t1 left join
(select object_id,
max(case when t2.object_type = 'INDEX' then t2.data_object_id end) col1,
max(case when t2.object_type = 'TABLE' then t2.data_object_id end) col2,
max(case when t2.object_type = 'PROCEDURE' then t2.data_object_id end) col3
from t2
group by object_id) v_t2
on v_t2.object_id = t1.object_id
where t1.object_name LIKE 'LOG%';
---------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows |E-Bytes| Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers |
---------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 231 (100)| | 447 |00:00:00.01 | 840 |
|* 1 | HASH JOIN OUTER | | 1 | 447 | 58557 | 231 (2)| 00:00:01 | 447 |00:00:00.01 | 840 |
| 2 | JOIN FILTER CREATE | :BF0000 | 1 | 447 | 35313 | 112 (1)| 00:00:01 | 447 |00:00:00.01 | 409 |
|* 3 | TABLE ACCESS FULL | T1 | 1 | 447 | 35313 | 112 (1)| 00:00:01 | 447 |00:00:00.01 | 409 |
| 4 | VIEW | | 1 | 22651 | 1150K| 120 (3)| 00:00:01 | 591 |00:00:00.01 | 431 |
| 5 | HASH GROUP BY | | 1 | 22651 | 862K| 120 (3)| 00:00:01 | 591 |00:00:00.01 | 431 |
| 6 | JOIN FILTER USE | :BF0000 | 1 | 22651 | 862K| 118 (1)| 00:00:01 | 591 |00:00:00.01 | 431 |
|* 7 | TABLE ACCESS FULL| T2 | 1 | 22651 | 862K| 118 (1)| 00:00:01 | 591 |00:00:00.01 | 431 |
---------------------------------------------------------------------------------------------------------------------------这里补充一下,原文这个写法根本就执行不了,子查询中没有object_id,外面哪来的 object_id去跟a表关联?

5. 标量子查询中有rownum=1或者rownum<2
原则上标量子查询中出现rownum表示该SQL是不严谨的,加上ROWNUM=1更多是为了防止标量子查询中返回多行而出现错误:
select t1.object_name,
(select t2.data_object_id
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'INDEX'
and rownum = 1) col1,
(select t2.data_object_id
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'TABLE'
and rownum = 1) col2,
(select t2.data_object_id
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'PROCEDURE'
and rownum = 1) col3
from t1
where t1.object_name LIKE 'LOG%';
分析思路:其实rownum=1就是为了避免子查询返回结果不止一行导致报错,所以随便取哪一行都可以。既然随便取哪一行都可以,那我们直接取 max(t2.data_object_id) 也可以。
所以本质上这个查询又变成了前面那个max的,既然如此,按照前面的方法改写就ok了。
select t1.object_name,
(select max(t2.data_object_id)
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'INDEX') col1,
(select max(t2.data_object_id)
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'TABLE') col2,
(select max(t2.data_object_id)
from t2
where t2.object_id = t1.object_id
AND t2.object_type = 'PROCEDURE') col3
from t1
where t1.object_name LIKE 'LOG%';
类似案例
--subs_product是大表
create table subs_product(subsid number,prodid number);
create table subscriber(subsid number,active number,region varchar2(10),status number,servnumber number);
create index idx_subscriber_subsid on subscriber(subsid);- 原SQL
select
(select b.servnumber from subscriber b
where b.subsid = a.subsid
and b.region = '14' and rownum < 2
) as "phone_number",
a.prodid,
(select r.status from subscriber r
where r.subsid = a.subsid
and r.region = '14' and r.active='1' and rownum < 2
) as "status"
from subs_product a;
- 改写法1:取max值+case when
select
b.phone_number,
a.prodid,
b.status
from subs_product a
left join (select subsid ,
max(servnumber) as phone_number,
max(case when active='1' then status end) status
from subscriber where region='14'
group by subsid
) b
on b.subsid = a.subsid;
- 改写法2:分析函数(取最值)+decode(case when)
select
b. servnumber as "phone_number",
a.prodid,
decode(b.active,1,b.status,null) as "user_status"
from subs_product a,
(select * from
(select r.subsid, r.status, r. servnumber , r.active,
row_number() over (partition by subsid order by decode(active,1,1,0) desc) as rn
from subscriber r
where r.region = '14'
) where rn=1
)b
where a.subsid=b.subsid(+);
四、 实际优化案例两个
1. 提取公因式
- 原SQL
select c.cardno, c.cout, nvl(d.cout2019, 0), c.cout - nvl(d.cout2019, 0)
from (select a.cardno, sum(a.point) cout
from guest a
where a.cardtype in ('01', '02', '99')
group by a.cardno) c
left join (select b.cardno, sum(b.point) cout
from guest b
where b.cardtype in ('01', '02', '99')
and b.lastusedate >= to_date('2019-01-01', 'yyyy-mm-dd')
and b.lastusedate <= to_date('2019-12-31', 'yyyy-mm-dd')
group by b.cardno) d
on c.cardno = d.cardno
where c.cout > 1
这个例子不涉及标量子查询,所以只是单纯case when改写。
将共同部分(紫色)提到where部分,特殊条件(橙色)使用case when。统计部分如果是sum,符合条件的 then point,不符合的else 0;如果是count,符合条件的 then 1,不符合的else 0;
下面两种方法没啥本质区别,都ok
- 改写法1:比较直接,完全是按照前面的思路改的
select cardno, cout, cout2019, (cout - cout2019) diff
from (select cardno,
sum(point) cout, -- 原子查询c
sum(case
when (lastusedate >= to_date('2019-01-01', 'yyyy-mm-dd') and b.lastusedate <= to_date('2019-12-31', 'yyyy-mm-dd')) then
point
else
0
end) cout2019 -- 原子查询d,另外有了else 0之后不需要nvl,因为不会有空值
from guest
where cardtype in ('01', '02', '99')
group by cardno) tmp
where cout > 1;
- 改写法2:重新命名了字段,更易读,另外用having point_all > 1替代了外层的 where cout > 1
select cardno, point_all, point2019, (point_all - point2019) as point_diff
from (select cardno,
sum(case
when lastusedate >= to_date('20190101', 'yyyymmdd') and lastusedate < to_date('20200101', 'yyyymmdd') then
point
else
0
end) as point2019,
sum(point) as point_all
from guest
where cardtype in ('01', '02', '99')
group by cardno
having point_all > 1);
2. case when+变量子查询改写
- 原sql,比较长
SELECT SVCCODE, SVCNAME,
(SELECT COUNT(1) AS Expr1
FROM dbo.CallTmp
WHERE (QueueStartTime IS NOT NULL) AND (TalkStartTime IS NULL) AND (AgentID IS NULL) AND (RingStartTime IS NULL) AND (DATEDIFF(SECOND, QueueStartTime, GETDATE()) BETWEEN 15 AND
6000) AND (SkillGroup = dbo.IVR.SVCCODE)) AS QueueCount,
(SELECT COUNT(1) AS Expr1
FROM dbo.CallTmp AS CallTmp_1
WHERE (TalkStartTime IS NOT NULL) AND (SkillGroup = dbo.IVR.SVCCODE)) AS CallCount,
(SELECT COUNT(1) AS Expr1
FROM dbo.Call
WHERE (QueueStartTime IS NOT NULL) AND (CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime)) AND (SkillGroup = dbo.IVR.SVCCODE)) AS AllCount,
(SELECT COUNT(1) AS Expr1
FROM dbo.Call AS Call_3
WHERE (TalkStartTime IS NULL) AND (QueueStartTime IS NOT NULL) AND (CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime)) AND
(SkillGroup = dbo.IVR.SVCCODE)) AS AbnCount,
(SELECT (CASE WHEN COUNT(1) = 0 THEN 0 ELSE CAST(ROUND(SUM(CASE WHEN TalkStartTime IS NOT NULL THEN 1 ELSE 0 END) * 100.0 / COUNT(1), 2) AS NUMERIC(5, 2)) END) AS Expr1
FROM dbo.Call AS Call_2
WHERE (CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime)) AND (SkillGroup = dbo.IVR.SVCCODE)) AS AnswerRate,
(SELECT (CASE WHEN COUNT(1) = 0 THEN 0 ELSE CAST(ROUND(SUM(CASE WHEN TalkStartTime IS NOT NULL AND WaitTime <= 30 THEN 1 ELSE 0 END) * 100.0 / COUNT(1), 2) AS NUMERIC(5, 2)) END)
AS Expr1
FROM dbo.Call AS Call_2
WHERE (CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime)) AND (SkillGroup = dbo.IVR.SVCCODE)) AS AnswerRate30s,
(SELECT AVG(TalkTime) AS Expr1
FROM dbo.Call AS Call_1
WHERE (CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime)) AND (SkillGroup = dbo.IVR.SVCCODE)) AS AvgTalkTime
FROM dbo.IVR
GROUP BY SVCNAME, SVCCODE
-- 物理读和逻辑读数目
(146 rows affected)
Table 'Call'. Scan count 295, logical reads 112985, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'IVR'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'CallTmp'. Scan count 2, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 28, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.根据逻辑读,绝大部分消耗在Call表,标量子查询导致其被扫描5次,calltmp虽然也有两次,但该表非常小,可以忽略。我们就先去掉calltmp部分来看,嗯,短了一丢丢(个鬼
SELECT SVCCODE, SVCNAME,
(SELECT COUNT(1) AS Expr1
FROM dbo.Call
WHERE (QueueStartTime IS NOT NULL) AND (CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime)) AND (SkillGroup = dbo.IVR.SVCCODE)) AS AllCount,
(SELECT COUNT(1) AS Expr1
FROM dbo.Call AS Call_3
WHERE (TalkStartTime IS NULL) AND (QueueStartTime IS NOT NULL) AND (CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime)) AND (SkillGroup = dbo.IVR.SVCCODE)) AS AbnCount,
(SELECT (CASE WHEN COUNT(1) = 0 THEN 0 ELSE CAST(ROUND(SUM(CASE WHEN TalkStartTime IS NOT NULL THEN 1 ELSE 0 END) * 100.0 / COUNT(1), 2) AS NUMERIC(5, 2)) END) AS Expr1
FROM dbo.Call AS Call_2
WHERE (CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime)) AND (SkillGroup = dbo.IVR.SVCCODE)) AS AnswerRate,
(SELECT (CASE WHEN COUNT(1) = 0 THEN 0 ELSE CAST(ROUND(SUM(CASE WHEN TalkStartTime IS NOT NULL AND WaitTime <= 30 THEN 1 ELSE 0 END) * 100.0 / COUNT(1), 2) AS NUMERIC(5, 2)) END)
AS Expr1
FROM dbo.Call AS Call_2
WHERE (CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime)) AND (SkillGroup = dbo.IVR.SVCCODE)) AS AnswerRate30s,
(SELECT AVG(TalkTime) AS Expr1
FROM dbo.Call AS Call_1
WHERE (CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime)) AND (SkillGroup = dbo.IVR.SVCCODE)) AS AvgTalkTime
FROM dbo.IVR
GROUP BY SVCNAME, SVCCODE
首先看子查询where部分,找公共和差异条件,整理出来
- 公共条件: (CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime) AND (SkillGroup = dbo.IVR.SVCCODE)
- 查询1:(QueueStartTime IS NOT NULL)
- 查询2:(TalkStartTime IS NULL) AND (QueueStartTime IS NOT NULL)
- 查询3-5:无差异条件
所以改法如下:
- 公共部分提取到where,查询3-5只是所取字段不同,可以照抄
- 查询1和2分别按差异条件改成case when
- 标量子查询中有聚合函数,所以改写后Call表应该按关联字段group by
- 与主表dbo.IVR的关联方式应该为left join
- 把CallStatTmp那两段子查询再加回去(灰色部分)
select SVCCODE,SVCNAME, (SELECT COUNT(1) AS Expr1
FROM dbo.CallStatTmp
WHERE (QueueStartTime IS NOT NULL) AND (TalkStartTime IS NULL) AND (AgentID IS NULL) AND (RingStartTime IS NULL) AND (DATEDIFF(SECOND, QueueStartTime, GETDATE()) BETWEEN 15 AND
6000) AND (SkillGroup = dbo.IVRSVC.SVCCODE)) AS QueueCount,
(SELECT COUNT(1) AS Expr1
FROM dbo.CallStatTmp AS CallStatTmp_1
WHERE (TalkStartTime IS NOT NULL) AND (SkillGroup = dbo.IVRSVC.SVCCODE)) AS CallCount,
ISNULL(AllCount,0) AllCount,ISNULL(AbnCount,0) AbnCount,ISNULL(AnswerRate,0) AnswerRate,ISNULL(AnswerRate30s,0) AnswerRate30s,AvgTalkTime
from dbo.IVRSVC
left join (
select SkillGroup,
SUM(CASE WHEN QueueStartTime IS NOT NULL THEN 1 ELSE 0 END)AS AllCount,
SUM(CASE WHEN TalkStartTime IS NULL AND QueueStartTime IS NOT NULL THEN 1 ELSE 0 END) AS AbnCount,
(CASE WHEN COUNT(1) = 0 THEN 0 ELSE CAST(ROUND(SUM(CASE WHEN TalkStartTime IS NOT NULL THEN 1 ELSE 0 END) * 100.0 / COUNT(1), 2) AS NUMERIC(5, 2)) END) AS AnswerRate,
(CASE WHEN COUNT(1) = 0 THEN 0 ELSE CAST(ROUND(SUM(CASE WHEN TalkStartTime IS NOT NULL AND WaitTime <= 30 THEN 1 ELSE 0 END) * 100.0 / COUNT(1), 2) AS NUMERIC(5, 2)) END) AS AnswerRate30s,
AVG(TalkTime) AS AvgTalkTime
from CallStat where CallStartTime >= CAST(CONVERT(varchar(10), GETDATE(), 120) + ' 00:00:00' AS datetime)
group by SkillGroup) tmp_CallStat
on tmp_CallStat.SkillGroup = SVCCODE
-- 物理读和逻辑读数目
(146 rows affected)
Table 'IVR'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 35, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Call'. Scan count 1, logical reads 383, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'CallTmp'. Scan count 2, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.参考
SQL为王:oracle标量子查询和表连接改写 - 云+社区 - 腾讯云
《专题培训-SQL写法与改写》


















 2558
2558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











