







很早之前就说要写这个的,但是中间我去写其他爬虫了,所以一直拖着没更( ˃᷄˶˶̫˶˂᷅ )
BUT,说好的要写这个爬虫那就一定要写!!
先说怎样找到我们要爬取的数据
我的思路是这样的:
主页→歌单页面→分类的各个歌单界面→分类歌单里的每一个歌单→歌单中的每一首歌(歌名,歌手,歌曲id)→歌曲下载链接
按照上述步骤
我们先到网易云音乐的主页:http://music.163.com/#
这里一定要注意,在编写爬虫代码时,后面的‘#’我们不能要!
所以代码里你要写入的链接是:http://music.163.com
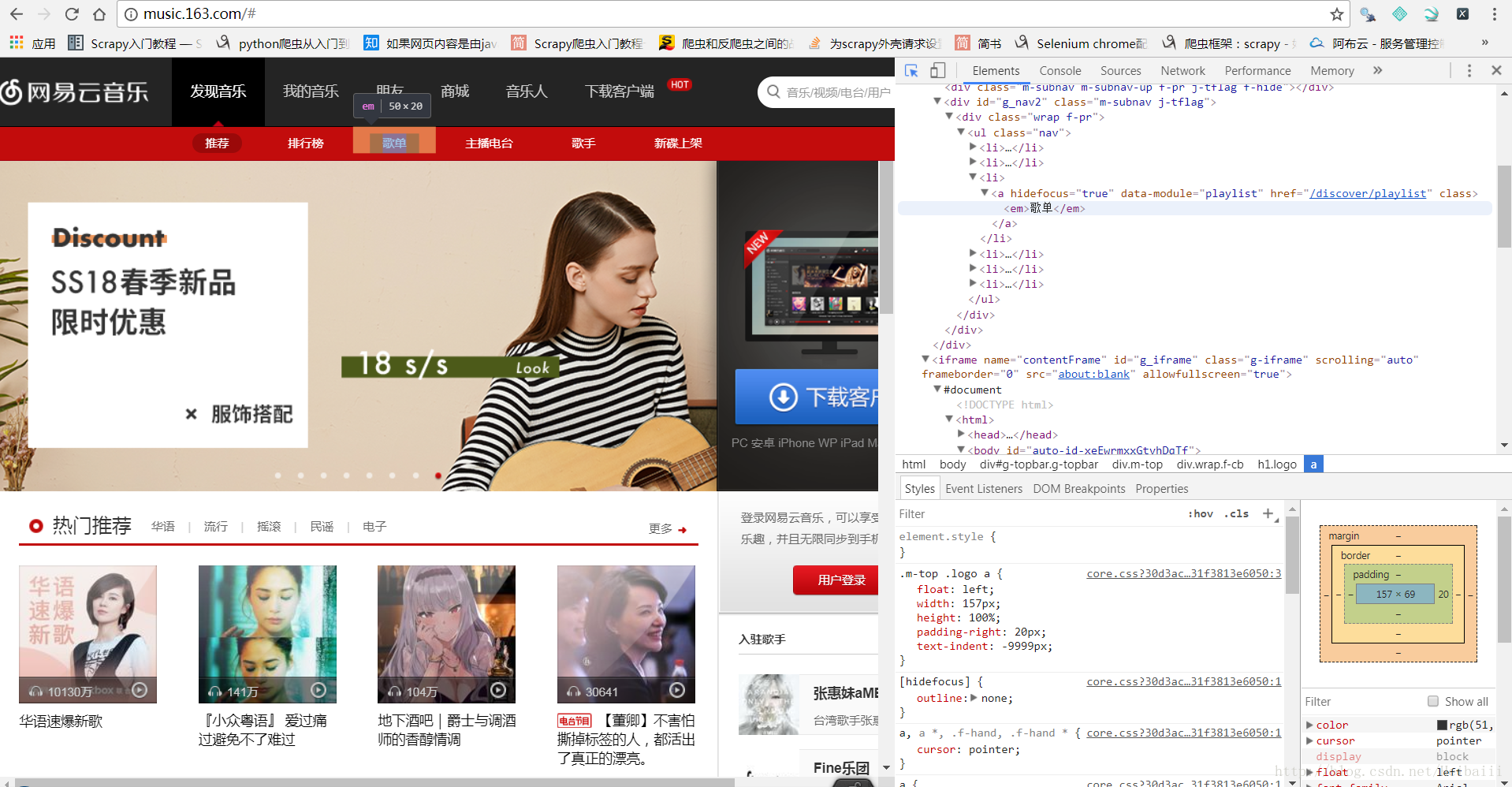
很轻松既可以找到‘歌单’这一分类的地址
接下来是‘歌单’分类的界面:
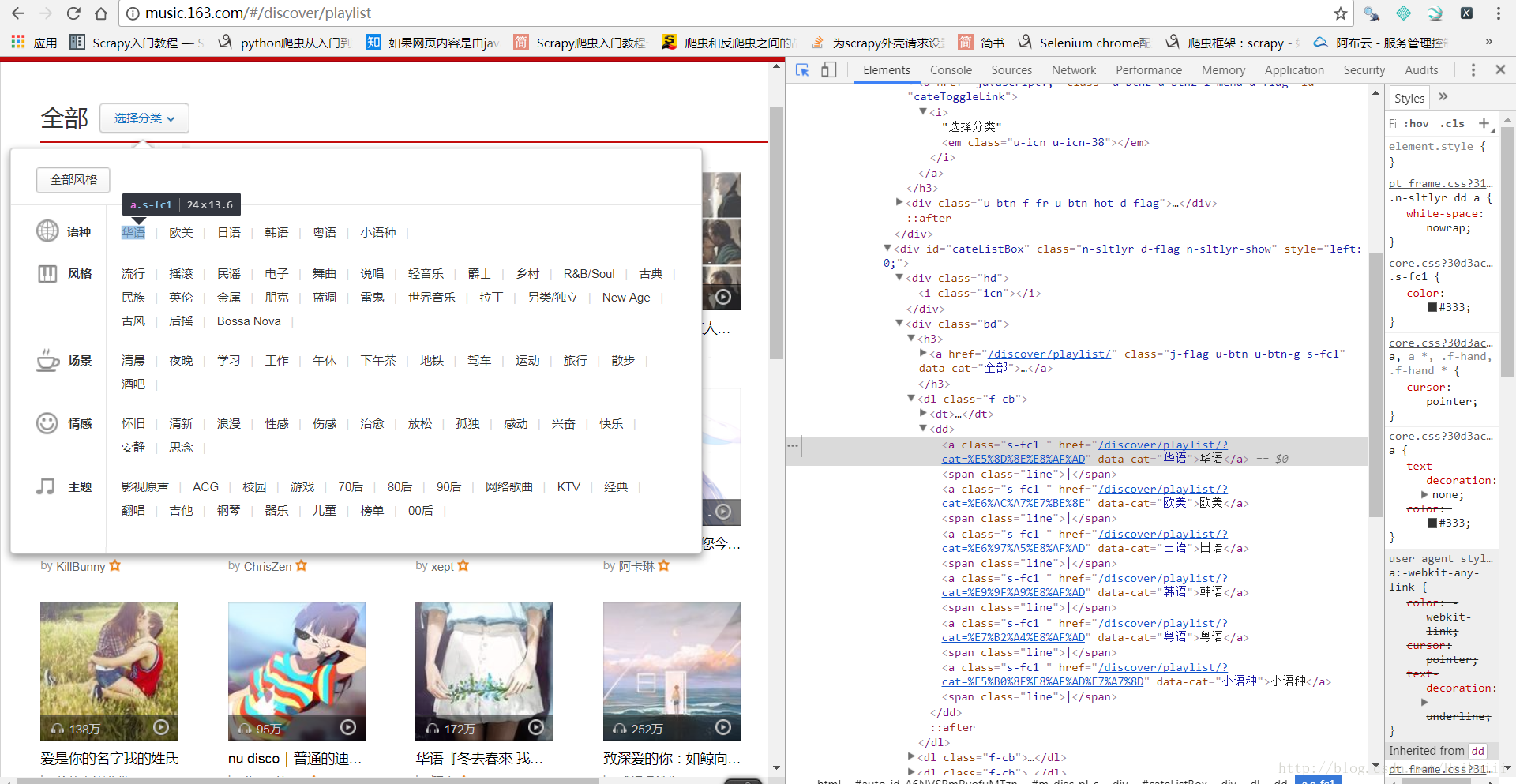
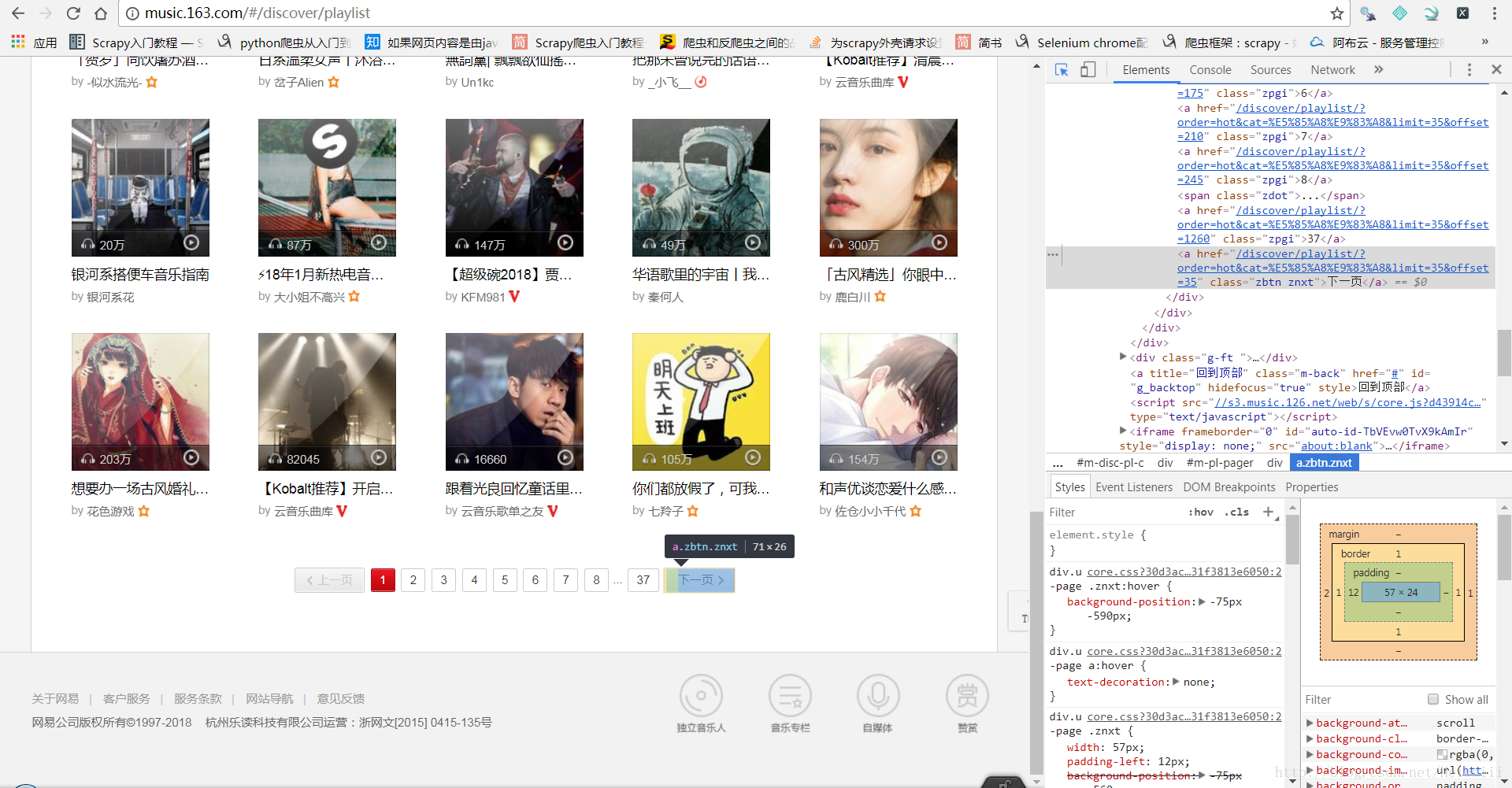
这里也可以很轻松的找到所有类别的歌单地址与下一页的地址
接着我们进入某一歌单的页面:
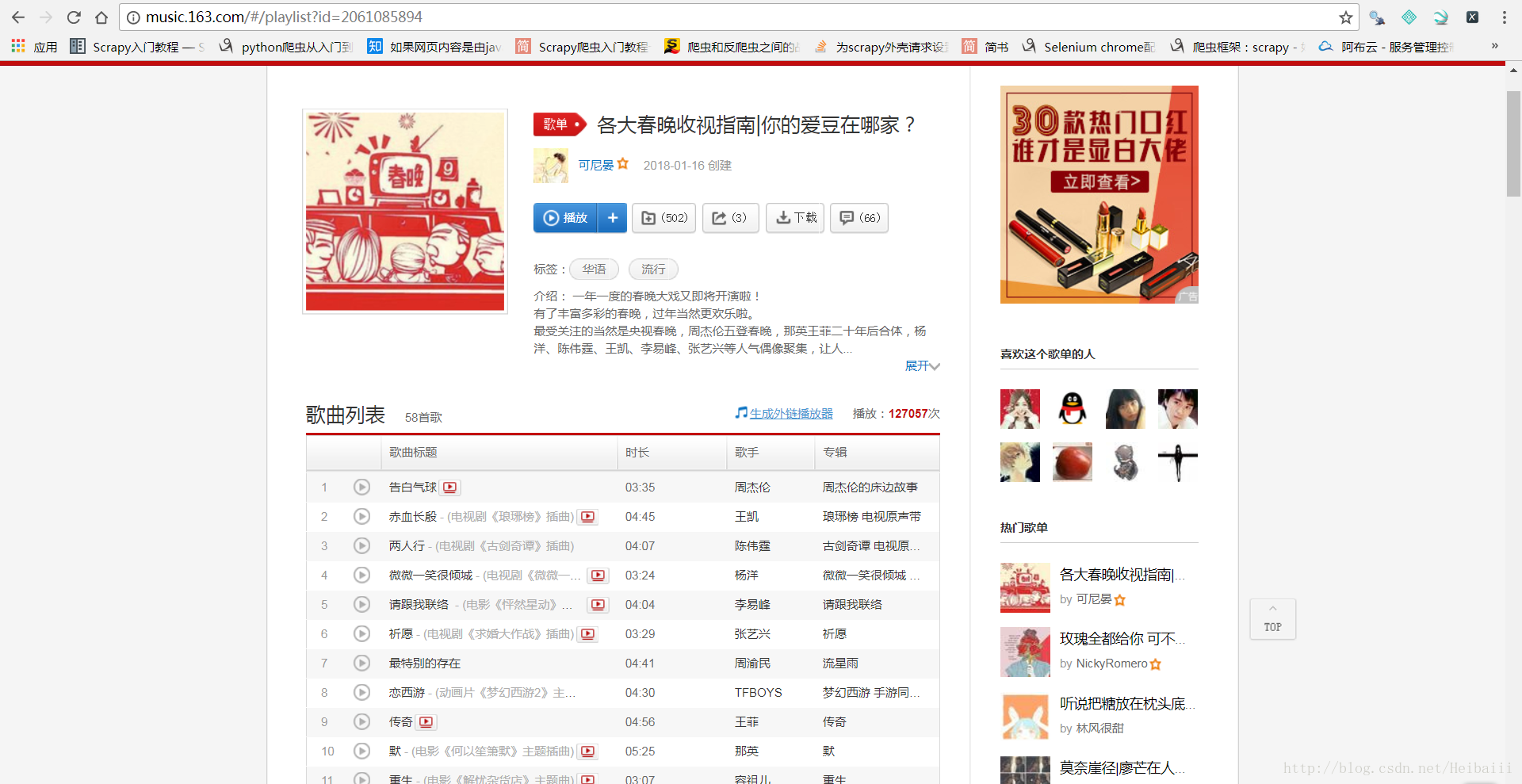
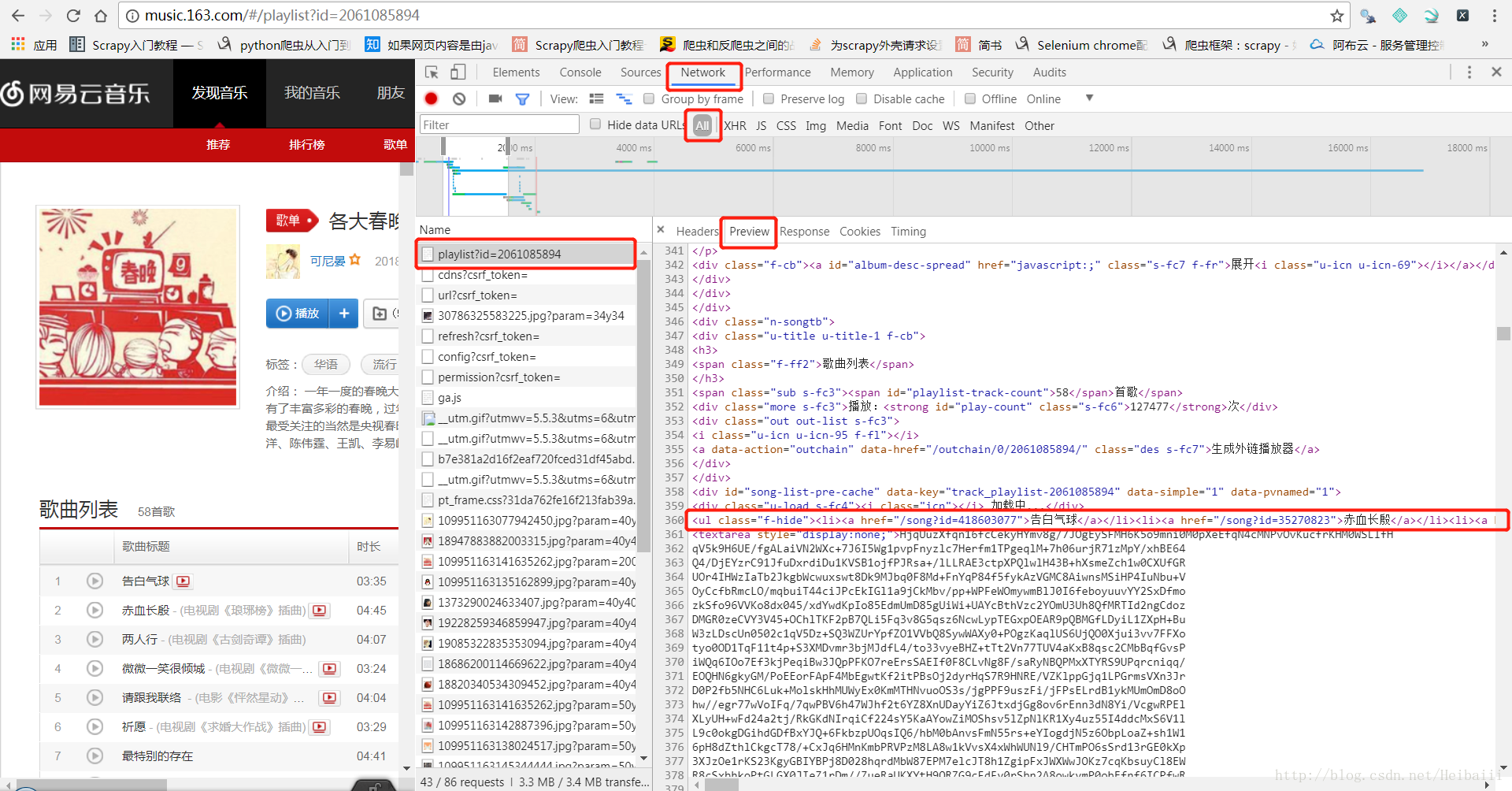
到这里你会发现,根据Elements编写的xpath路径根本找不到每一首歌的链接,因为Elments里的代码其实并不是真实源码,而是经过浏览器渲染后的代码,我们要找的源码在这里:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









